您现在的位置是:主页 > news > 那些网站是php做的/seo专业培训机构
那些网站是php做的/seo专业培训机构
![]() admin2025/5/26 6:18:56【news】
admin2025/5/26 6:18:56【news】
简介那些网站是php做的,seo专业培训机构,开封网站设计,网站模板下载RNN的类别: 循环神经网络主要应用于序列数据的处理,因输入与输出数据之间有时间上的关联性,所以在常规神经网络的基础上,加上了时间维度上的关联性,也就是有了循环神经网络。因此对于循环神经网络而言,它能…
RNN的类别:
循环神经网络主要应用于序列数据的处理,因输入与输出数据之间有时间上的关联性,所以在常规神经网络的基础上,加上了时间维度上的关联性,也就是有了循环神经网络。因此对于循环神经网络而言,它能够记录很长时间的历史信息,即使在某一时刻有相同的输入,但由于历史信息不同,也会得到不同的输出,这也是循环神经网络相比于常规网络的不同之处。
根据输入与输出之间的对应关系,可以将循环神经网络分为以下五大类别:
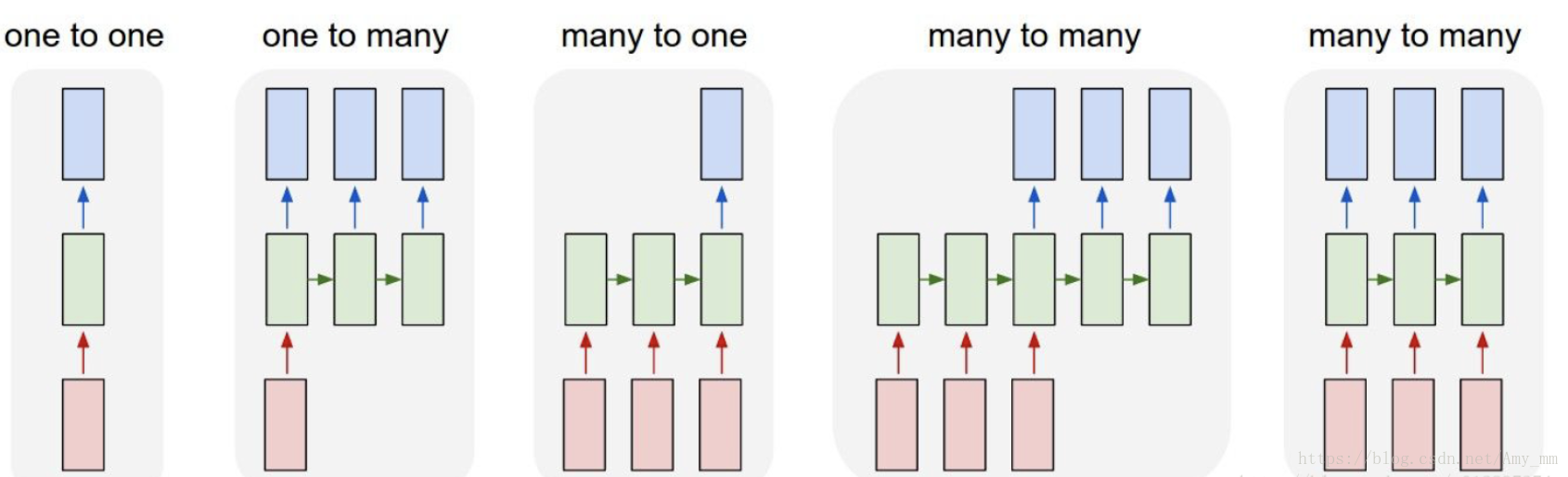
常规网络中的输入与输出大多是向量与向量之间的关联,不考虑时间上的联系,而在循环神经网络中,输入与输出之间大多是序列与序列(Sequence-to-Sequence.)之间的联系,也就产生了多种模式。
- 一对一(one to one):最为简单的反向传播网络
- 一对多(one to many):可用于图像捕捉(image captioning),将图像转换为文字
- 多对一(many to one):常用于情感分析(sentiment analysis),将一句话中归为具体的情感类别。
- 多对多( many to many):常用于输入输出序列长度不确定时,例如机器翻译(machine translate),实质是两个神经网络的叠加。
- 不确定长度的多对多(many to many)(最右方):常用于语音识别(speech recognition)中,输入与输出序列等长。
文本生成原理:
本章节的文本生成(text generation)示例基于char RNN,也就是说循环神经网络的输入为一个字一个字的序列,输出为与输入等长的字序列,属于上述中的等长的多对多的结构。
基于字符集的文本生成原理可以这样简单理解:
(1)将一个长文本序列依次输入到循环神经网络
(2)对于给定前缀序列的序列数据,对序列中将要出现的下一个字符的概率分布建立模型
(3)这样就可以每次产生一个新的字符
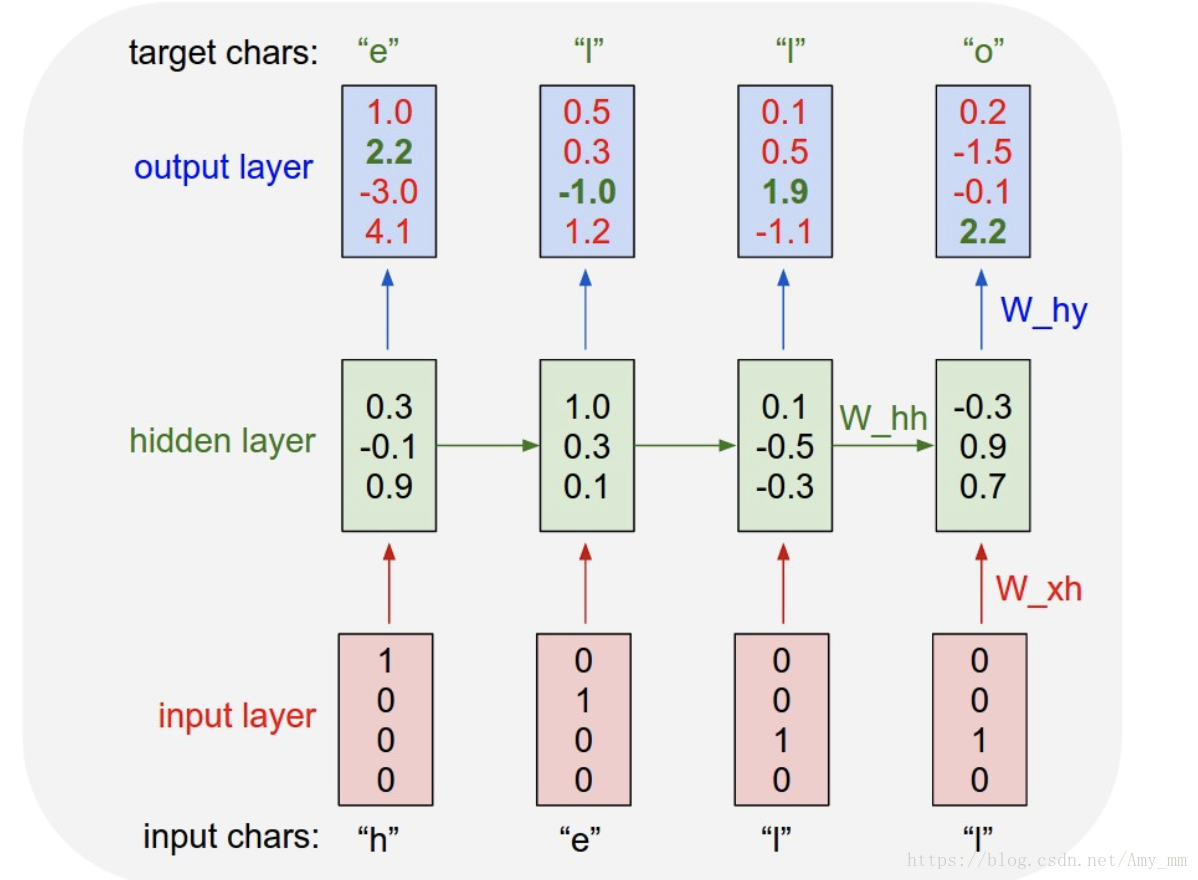
如下图所示,我们想要从给定序列‘hell’中生成‘hello’。每次输入到循环神经网络中一个字符,并计算其概率分布。所以每个字符的出现概率分布都是基于前面历史序列得到的,如第二个‘l’的概率是通过历史信息‘hel’得出。在输出层可以通过最大似然或者条件随机场等规则选择结果。
再经过不断的迭代和优化训练出文本生成的模型。
古诗生成:
在本示例中,将会通过3000多首的唐诗,利用LSTM网络训练一个古诗生成的模型。
代码解读:
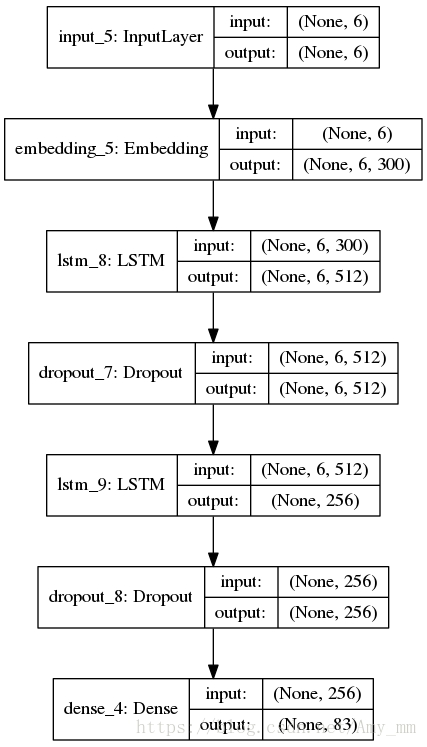
网络逻辑图如下:
1、数据处理
自然语言处理中,数据预处理的很多过程是共通的,都是要将文本数据进行编码,变为机器可以识别的词向量或者字向量,比如Word2Vec,one-hot编码等方法。
本次数据预处理步骤如下:
(1)读取古诗数据集,在每首诗的末尾加‘]’,并去除古诗名字只取古诗内容,最后得到一个长文本
with open('poetry.txt', 'r') as f:files_content = ''lines = [x for x in f]for line in lines[:10]:files_content += (line.strip() + "]").split(":")[-1]
(2)统计每个字出现的频率,并去除出现频率较低的字。一般来说如果数据集较小可以不去除。
# 统计每个字符出现的概率words = sorted(list(files_content))counted_words = {}for word in words:if word in counted_words:counted_words[word] += 1else:counted_words[word] = 1# 去除出现概率较小的字符。此处设置为2word_delet = []for key in counted_words:if counted_words[key] <= 2:word_delet.append(key)for key in word_delet:del counted_words[key]
(3) 按照出现频率排序,保留字符集词典,并在最后添加空格字符。
wordPairs = sorted(counted_words.items(), key=lambda x: -x[1])words, _ = zip(*wordPairs)print(words)words += (" ",)
(4) 按照(3)中得到的词典,得到每个字对应的索引号,建立{字符:索引号}以及{索引号:字符}两个字典。因为机器无法识别汉字,只能转换为数字输入,这也是自然语处理中的常规操作。此处还定义了由字符转换为索引号的函数,以便之后使用。
word2num = dict((c, i) for i, c in enumerate(words))num2word = dict((i, c) for i, c in enumerate(words))word2numF = lambda x: word2num.get(x, len(words) - 1)return word2numF, num2word, words, files_content
2、定义配置数据
这里所谓的配置数据指的是每次处理的样本数据量batch_size,模型训练的学习率learning_rate,每次取字符的最大长度maxlen,模型参数存储的文件路径,此处参数主要是权重,model_path。
model_path = 'poetry_model.h5'max_len = 6batch_size = 512learning_rate = 0.001
3、生成训练数据。
(1)训练数据分为输入数据和输出数据,因为此处生成的是七言古诗,所以可得知输入6个字,预测输出一个字。
# max_len=6
x = self.files_content[i: i + self.config.max_len]
y = self.files_content[i + self.config.max_len]
(2)将输入输出数据转为向量。
y_vec = np.zeros(shape=(1, len(self.words)),dtype=np.bool)
x_vec = np.zeros(shape=(1, self.config.max_len),dtype=np.int32
)
y_vec[0, self.word2numF(y)] = 1.0
for t, char in enumerate(x):x_vec[0, t] = self.word2numF(char)yield x_vec, y_vec
(3)此处用到一个while 1 的循环加生成器,每个batch生成一次输入输出向量,送入模型训练。
i = 0while 1:··· ···(上述代码)i += 1
4、建立模型
模型很简单,就是两个lstm的叠加加上一个全连接层。因为keras已经将模型封装的很好了,使用起来很简单。
input_tensor = Input(shape=(self.config.max_len,))
embedd = Embedding(len(self.num2word), 300, input_length=self.config.max_len)(input_tensor)
lstm = (LSTM(512, return_sequences=True))(embedd)
dropout = Dropout(0.6)(lstm)
lstm = LSTM(256)(dropout)
dropout = Dropout(0.6)(lstm)
dense = Dense(len(self.words), activation='softmax')(dropout)
self.model = Model(inputs=input_tensor, outputs=dense)optimizer = Adam(lr=self.config.learning_rate)
self.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
5、训练模型
计算epoch,防止输入输出的下标超出文本长度。
number_of_epoch = len(self.files_content) // self.config.batch_sizeif not self.model:self.build_model()
self.model.summary()
self.model.fit_generator(generator=self.data_generator(),verbose= 1,steps_per_epoch=self.config.batch_size,epochs=number_of_epoch)
6、输入文本,输出预测的古诗。
(1)概率抽样。不是完全选择概率最大的输出,而是根据生成的概率抽样选择最后的预测输出数据。temperature参数可以调节抽样的权重,当temperature较小时,选择概率较大的值输出,反之选择概率较小的。
def sample(self, preds, temperature=1.0):'''当temperature=1.0时,模型输出正常当temperature小于1时时,模型输出比较open当temperature大于1时,模型输出比较保守在训练的过程中可以看到temperature不同,结果也不同'''preds = np.asarray(preds).astype('float64')preds = np.log(preds) / temperatureexp_preds = np.exp(preds)preds = exp_preds / np.sum(exp_preds)probas = np.random.multinomial(1, preds, 1)return np.argmax(probas)(2)预测输出
输入的文本长度如果小于4个字,则自动补全。
with open(self.config.poetry_file, 'r', encoding='utf-8') as f:file_list = f.readlines()
random_line = random.choice(file_list)
# 如果给的text不到四个字,则随机补全
if not text or len(text) != 4:for _ in range(4 - len(text)):random_str_index = random.randrange(0, len(self.words))text += self.num2word.get(random_str_index) \if self.num2word.get(random_str_index) not in [',', '。',','] \else self.num2word.get(random_str_index + 1)
seed = random_line[-(self.config.max_len):-1]利用sample函数产生概率抽样值,然后选择模型的输出概率,将向量转换为汉字输出。
# text 为输入文本
for c in text:# seed 为自定补全的输入文本,长度不小于4个字。seed = seed[1:] + cfor j in range(5):x_pred = np.zeros((1, self.config.max_len))for t, char in enumerate(seed):x_pred[0, t] = self.word2numF(char)preds = self.model.predict(x_pred, verbose=0)[0]next_index = self.sample(preds, 1.0)next_char = self.num2word[next_index]seed = seed[1:] + next_charres += seed

训练次数太少,模型还不能很好的生成古诗,可以看到随着训练次数的增加,模型会越加越智能。








