您现在的位置是:主页 > news > 拿品牌做网站算侵权吗/营销型网站建设怎么做
拿品牌做网站算侵权吗/营销型网站建设怎么做
![]() admin2025/5/23 2:13:25【news】
admin2025/5/23 2:13:25【news】
简介拿品牌做网站算侵权吗,营销型网站建设怎么做,用php做的网站实例,买了一台配置强悍的电脑怎么做网站服务器【训练判别器】1.在隐空间中对一批随机点采样2.通过“生成器”模型将这些点转换为虚假图像3.获取一批真实图像,并将它们与生成的图像组合4.训练“判别器”模型以对生成的图像与真实图像进行分类【训练生成器】1.在隐空间中对随机点采样2.通过“生成器”网络将这些点…
【训练判别器】
1.在隐空间中对一批随机点采样
2.通过“生成器”模型将这些点转换为虚假图像
3.获取一批真实图像,并将它们与生成的图像组合
4.训练“判别器”模型以对生成的图像与真实图像进行分类
【训练生成器】
1.在隐空间中对随机点采样
2.通过“生成器”网络将这些点转换为虚假图像
3.训练“生成器”模型以“欺骗”判别器,并将虚假图像分类为真实图像
我们在之前的文章里简单介绍了对抗生成网络(GAN),通过“工艺品”和“鉴赏师”的例子并推导了基本的原理。今天,我们继续深入剖析GAN算法的细节,彻底了解其精髓。
传送门:生成对抗网络(GAN)

对抗的初衷

生成对抗网络,是一个生成模型。对于生成模型,我们的想法是根据输入的训练样本去生成符合真实分布的新样本:
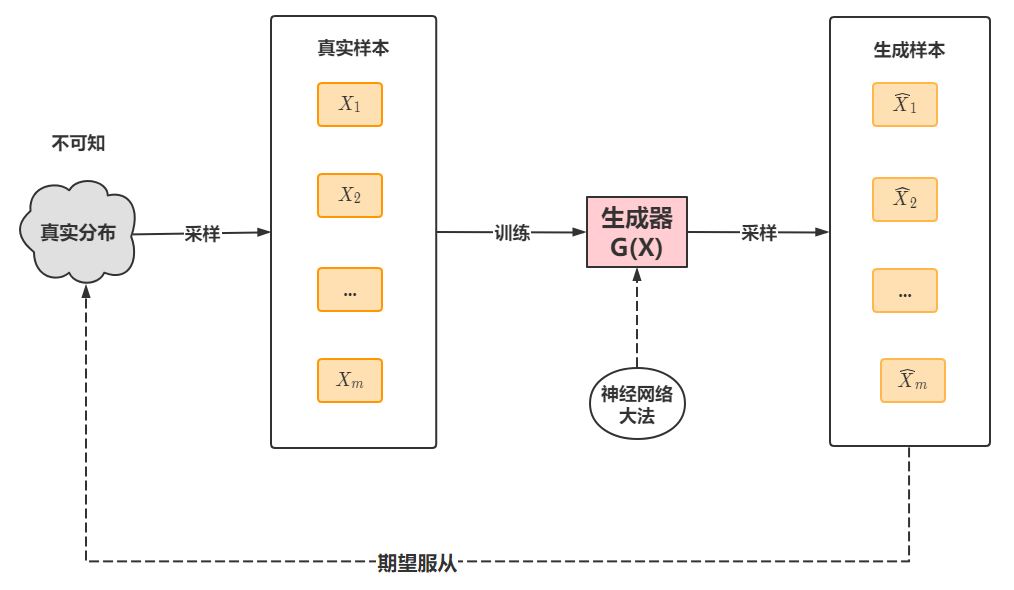
其数学思想是根据一个已知简单分布去逼近任意复杂函数,这一点我们在变分自编码深入剖析文章讲解过——假设真实样本来自于正态分布(Z),根据隐变量Z进行采样再译码成新样本。
传送门:带你看懂变分自编码(VAE)
但在GAN这里,我们不再限制真实样本要来自某个分布,而是将encode-decode两个过程融合到一起,用一个神经网络去逼近,然后直接生成样本。那么接下来的问题就是,怎么判断这个生成样本是真的来自于真实分布呢,VAE是通过与训练样本比较,在GAN这里不是这样,而是首先初始化生成器G(X),然后生成一系列样本,假定真实样本是正样本,生成样本是负样本,训练一个神经网络作为判别器D(X)。然后再用生成样本作为正样本去“迷惑”判别器,更新生成器。流程如下:

这里,生成器相当于“工艺师”,判别器相当于”鉴赏师“。先优化判别器,再优化生成器。我们仔细观察,判别器D(X)的输出目标是否为真实样本,也就是二分类问题,如果来自真实样本,则y=0,如果来自生成样本,则y=1。然后,更新生成器是固定住判别器后,人为的把生成样本当作”正样本“训练。
以上,就是GAN的核心思想以及实现过程,下面我们通过源码加深了解。

tf的GAN源码解析

本次展示的是tensorflow的GAN实现,编写两个模型——生成器,判别器。事先导入相关的包。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
接着编写判别器,可以区分真实图像(来自训练数据集)与虚假图像(生成器网络的输出)之间差异的分类器:
discriminator = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Conv2D(64, (3, 3), strides=(2, 2), padding="same"),layers.LeakyReLU(alpha=0.2),layers.Conv2D(128, (3, 3), strides=(2, 2), padding="same"),layers.LeakyReLU(alpha=0.2),layers.GlobalMaxPooling2D(),layers.Dense(1),],name="discriminator",
)
然后是生成器,最后输出是28*28形状的张量,对于MNIST数字:
latent_dim = 128generator = keras.Sequential([keras.Input(shape=(latent_dim,)),# We want to generate 128 coefficients to reshape into a 7x7x128 maplayers.Dense(7 * 7 * 128),layers.LeakyReLU(alpha=0.2),layers.Reshape((7, 7, 128)),layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"),layers.LeakyReLU(alpha=0.2),layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"),layers.LeakyReLU(alpha=0.2),layers.Conv2D(1, (7, 7), padding="same", activation="sigmoid"),],name="generator",
)
接下来是重点的训练过程,首先初始化生成器,然后随机化输入张量,产生负样本(虚假图像),核心代码如下:
random_latent_vectors = tf.random.normal(shape=(batch_size, latent_dim))
# Decode them to fake images
generated_images = generator(random_latent_vectors)
然后,将负样本与正样本(真实图像)拼接,一起传给判别器,这里,需要打标签,负样本标记为1,正样本为0,这里还对标签加了服从均匀分布的噪声:
combined_images = tf.concat([generated_images, real_images], axis=0)
# Assemble labels discriminating real from fake images
labels = tf.concat([tf.ones((batch_size, 1)),tf.zeros((real_images.shape[0], 1))], axis=0)
labels += 0.05 * tf.random.uniform(labels.shape)
下面先训练判别器,更新判别器的参数:
# Train the discriminator
with tf.GradientTape() as tape:predictions = discriminator(combined_images)d_loss = loss_fn(labels, predictions)
grads = tape.gradient(d_loss, discriminator.trainable_weights)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_weights))
然后,将负样本标签更改为0,“误导”判别器,去更新生成器参数,源码是再重新生成负样本,这一步切记判别器的参数是固定的,只更新生成器:
# Sample random points in the latent spacerandom_latent_vectors = tf.random.normal(shape=(batch_size, latent_dim))# Assemble labels that say "all real images"misleading_labels = tf.zeros((batch_size, 1))with tf.GradientTape() as tape:predictions = discriminator(generator(random_latent_vectors))g_loss = loss_fn(misleading_labels, predictions)grads = tape.gradient(g_loss, generator.trainable_weights)g_optimizer.apply_gradients(zip(grads, generator.trainable_weights))
最后就是启动训练过程了,这里不再赘述了,查看源码即可。链接已附在参考资料。
参考资料:
https://tensorflow.google.cn/guide/keras/writing_a_training_loop_from_scratch








