您现在的位置是:主页 > news > 网站 后台 java/百度搜索
网站 后台 java/百度搜索
![]() admin2025/5/18 15:11:25【news】
admin2025/5/18 15:11:25【news】
简介网站 后台 java,百度搜索,长沙好的网站建设公司哪家好,淄博网站备案常用的正则表达式操作符 Re库 则表达式(英文名称:regular expression,regex,RE)是用来简洁表达一组字符串特征的表达式。最主要应用在字符串匹配中。 模式介绍: 1).re.I(re.IGNORECASE): 忽略大小写 2)…
常用的正则表达式操作符
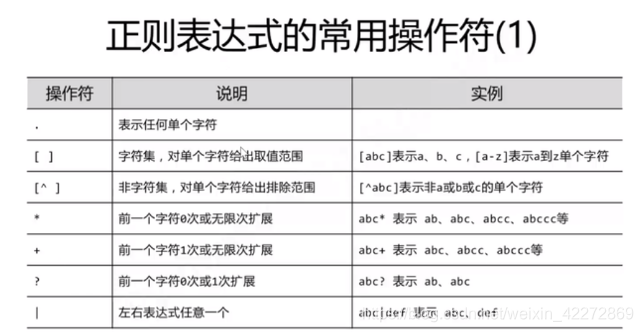
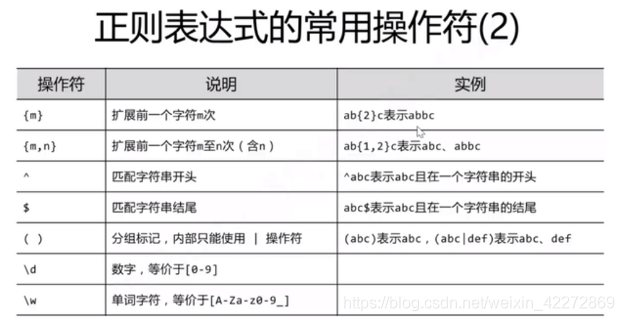
Re库
则表达式(英文名称:regular expression,regex,RE)是用来简洁表达一组字符串特征的表达式。最主要应用在字符串匹配中。
模式介绍:
1).re.I(re.IGNORECASE): 忽略大小写
2).re.M(MULTILINE): 多行模式,改变’^‘和’$‘的行为
3).re.S(DOTALL): 点任意匹配模式,改变’.'的行为
4).re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
5).re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
6).re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
函数介绍:

1、re.search(pattern,string,flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象。
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记,哪个模式
第一种:
# -*- coding = utf-8 -*-
import re
# 创建模式对象
pat = re.compile("aa") # 此处的aa是正则表达式reh = pat.search("aaa") # search后的字符串是被校验的字符串
print(reh)
# <re.Match object; span=(0, 2), match='aa'>
第二种:
pat = re.search("aa","aaa")
print(pat)
# <re.Match object; span=(0, 2), match='aa'>
2、re.match(pattern,string,flags=0)
从一个字符串的开始位置起匹配正则表达式,返回match对象。
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记
第一种:
pat = re.match("a","aaaa")
print(pat)
# <re.Match object; span=(0, 1), match='a'>
第二种:
pat = re.compile("a")
p = pat.match("aaaa")
print(p)
# <re.Match object; span=(0, 1), match='a'>
3、re.findall(pattern,string,flags=0)
搜索字符串,以列表类型返回全部能匹配的子串。
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记
第一种:
pat = re.findall("a","aassaaddd");
print(pat)
# ['a', 'a', 'a', 'a']
第二种:
# 创建模式对象
pat = re.compile("a") # 此处的aa是正则表达式re = pat.findall("aassaaddd") # search后的字符串是被校验的字符串
print(re)
4、re.split(pattern,string,maxsplit=0,flags=0)
搜索字符串,以列表类型返回全部能匹配的子串。
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
maxsplit:最大分割数,剩余部分作为最后一个元素输出
flags:正则表达式使用时的控制标记
第一种:
pat = re.split("a","hadhks",2)
print(pat)
# ['h', 'dhks']
5、re.finditer(pattern,string,flags=0)
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象。
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记
第一种:
pat = re.finditer("a","aabbss")
for i in pat:print(i)
# <re.Match object; span=(0, 1), match='a'>
# <re.Match object; span=(1, 2), match='a'>
6、re.sub(pattern,repl,string,count=0,flags=0)
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。
pattern:正则表达式的字符串或原生字符串表示
repl:替换匹配字符串的字符串
string:待匹配字符串
count:匹配的最大替换次数
flags:正则表达式使用时的控制标记
第一种:
pat = re.sub("a","b","aaaadddvvv",5)
print(pat)
# bbbbdddvvv
Re库的另一种等价用法:
函数式用法:一次性操作
rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
面向对象用法:编译后的多次操作
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
regex = re.comile(pattern,flags=0)
将正则表达式的字符串形式编译成正则表达式对象
pattern:正则表达式的字符串或原生字符串表示
flags:正则表达式使用时的控制标记
regex 才是正则表达式:regex = re.compile(r’[1-9]\d{5}’)
在匹配的字符串前加上r就可以避免转义字符
s = r"'ssssss\'"
print(s)
# 'ssssss\'








