您现在的位置是:主页 > news > 网站设计要如何做支付功能/外包网络推广公司
网站设计要如何做支付功能/外包网络推广公司
![]() admin2025/5/7 10:12:01【news】
admin2025/5/7 10:12:01【news】
简介网站设计要如何做支付功能,外包网络推广公司,做网站招聘的职业顾问,网站建设需要什么资质引言 2006年的一篇论文《Map-Reduce for Machine Learning on Multicore》[1]在PAC(probably approximate correct)理论和SQL(Statistical Query Learning)[2]理论的框架下,指出了“求和形式算法”可以自然的利用多CPU并行训练(也可以推广到MapReduce编…
引言
2006年的一篇论文《Map-Reduce for Machine Learning on Multicore》[1]在PAC(probably approximate correct)理论和SQL(Statistical Query Learning)[2]理论的框架下,指出了“求和形式算法”可以自然的利用多CPU并行训练(也可以推广到MapReduce编程范式下并行训练)。我们见到的绝大多数使用MapReduce进行训练的模型,都可以归结到这篇论文中提出的形式,它们本质上对于算法本身没有进行任何修改,只是将计算的数据集合进行了一定的拆分。
另外一类的并行训练不依赖MapReduce,例如XGBoost和LightGBM的集群训练模式。这些并行训练本质上是将模型训练过程中的某些方便并行化的步骤做了特殊处理,同样不会修改算法本身。这一类并行算法非常依赖于工程实现。
不同于上述的方式,本文分享的是一种基于微分方程稳定性点的分布式算法:Zero-Gradient-Sum(梯度和零)[3]算法。该算法适用于求和形式的凸问题。同样,这种训练方法不改变算法本身,并且有较优秀的效率,较少的网络IO,以及完备的理论基础。ZGS是一种隐私算法,分布式计算时不同节点之间不交换原始数据,可以使用在医疗数据、金融数据的模型训练场景。经过推广的ZGS在不同类型的网络拓扑结构上(有向图,无向图),不同类型的数据分片上(按行分布或按列分布)以及连续时间和离散时间上均有较为成熟的理论,有很强的适用范围.
问题描述
ZGS适用于如下形式的问题:
x∗∈argminx∑i=1Nfi(x)(1)x^* \in \underset {x}{argmin} \sum_{i=1}^Nf_i(x) \tag 1 x∗∈xargmini=1∑Nfi(x)(1)
其中fif_ifi均为可二次求导的凸函数,并且是局部李普希兹的,NNN表示有N个计算节点,x∗x^*x∗是使得∑i=1Nfi(x)\sum_{i=1}^Nf_i(x)∑i=1Nfi(x)最小的全局最优解.
举个例子,径向基网络(Radial Basis Function Network,RBFN)就满足上述的形式.
我们定义RBFN的损失函数
L=∣∣y−Hw∣∣2+σ∣∣w∣∣2/2(2)L = ||y-Hw||^2 + \sigma||w||^2/2 \tag 2 L=∣∣y−Hw∣∣2+σ∣∣w∣∣2/2(2)
其中y=[y1,...,yN]Ty=[y_1,...,y_N]^Ty=[y1,...,yN]T,w=[w1,....,wL]Tw=[w_1,....,w_L]^Tw=[w1,....,wL]T
H=[φ(∣∣x1−c1∣∣)…φ(∣∣x1−cL∣∣)⋮⋱⋮φ(∣∣xN−c1∣∣)…φ(∣∣xN−cL∣∣)]N×L(3)H= \left[ \begin{matrix} \varphi(||x_1-c_1||) & \dots & \varphi(||x1-c_L||) \\ \vdots & \ddots & \vdots \\ \varphi(||x_N-c_1||) & \dots & \varphi(||xN-c_L||) \end{matrix} \right]_{N \times L } \tag 3 H=⎣⎢⎡φ(∣∣x1−c1∣∣)⋮φ(∣∣xN−c1∣∣)…⋱…φ(∣∣x1−cL∣∣)⋮φ(∣∣xN−cL∣∣)⎦⎥⎤N×L(3)
当径向基函数中xix_ixi确定后, 网络的优化即为计算www,显然,RBF的损失函数是一个二阶连续的凸函数,满足ZGS可分布式条件.
算法
ZGS的算法最早提出被用于解决无向通信网络中有固定拓扑结构的无约束且可分的凸优化问题.算法表达式如下:
{sumi=1V∇fi(x)=0xi(0)=xi∗(4)\left\{ \begin{aligned} sum_{i=1}^V \nabla f_i(x)=0 \\ x_i(0)=x_i^* \\ \end{aligned} \right. \tag 4 {sumi=1V∇fi(x)=0xi(0)=xi∗(4)
其中xi∗x_i^*xi∗表示节点i上的局部最优解.这表示,ZGS将数据分散的存储在不同的节点上,再迭代求解.
例.使用ZGS对RBFN进行训练.
根据公式(2),可以容易求得RBFN损失函数关于wi(k)w_i(k)wi(k)的导数:
∇Li(wi(k))=(HiTHi+σiIL)wi(k)−HiTyi(5)\nabla L_i(w_i(k))=(H_i^TH_i+\sigma_iI_L)w_i(k)-H_i^Ty_i \tag 5 ∇Li(wi(k))=(HiTHi+σiIL)wi(k)−HiTyi(5)
根据ZGS算法,可以得到w(k)w(k)w(k)的迭代式:
{wi(k+1)=wi(k)+γ(HiTHi+σiIL)−1sumj∈Niaij(wj(k)−wi(k))wi(0)=wi∗=(HiTHi+σiIL)−1HiTyi(6)\left\{ \begin{aligned} w_i(k+1)=w_i(k)+\gamma(H_i^TH_i+\sigma_iI_L)^{-1}sum_{j \in \mathbb{N}_i}a_ij(w_j(k)-w_i(k)) \\ w_i(0)=w_i^*=(H_i^TH_i+\sigma_iI_L)^-1H_i^Ty_i \end{aligned} \right. \tag 6 {wi(k+1)=wi(k)+γ(HiTHi+σiIL)−1sumj∈Niaij(wj(k)−wi(k))wi(0)=wi∗=(HiTHi+σiIL)−1HiTyi(6)
进一步,写成矩阵形式:
{W(k+1)=W(k)−γ(HTH+σ⊗IL)−1(L⊗I)W(k)+W(k)W(0)=W∗=(HTH+σ⊗IL)−1HTy(7)\left\{ \begin{aligned} W(k+1)=W(k)-\gamma(H^TH+\sigma \otimes I_L)^{-1} (\mathbb{L}\otimes I)W(k)+W(k) \\ W(0)=W^*=(H^TH+\sigma \otimes I_L)^{-1}H^Ty \end{aligned} \right. \tag 7 {W(k+1)=W(k)−γ(HTH+σ⊗IL)−1(L⊗I)W(k)+W(k)W(0)=W∗=(HTH+σ⊗IL)−1HTy(7)
其中, W(k)=[w1T(k),w2T(k),...,wVT(k)]T,H=diagH1,H2,...,HV,σ=diagσ1,σ2,...,σVW(k)=[w_1^T(k),w_2^T(k), ... ,w_V^T(k)]^T,H=diag{H_1,H_2,...,H_V},\sigma = diag{\sigma _ 1,\sigma_2, ..., \sigma_V}W(k)=[w1T(k),w2T(k),...,wVT(k)]T,H=diagH1,H2,...,HV,σ=diagσ1,σ2,...,σV,σi,γ\sigma _i , \gammaσi,γ都是可以调的参数.VVV代表分布式拓扑图里的节点集合,L\mathbb{L}L是网络拓扑图的拉普拉斯矩阵.
算法推导
引理1:
强图二次可导的函数满足以下不等式
f(y)−f(x)−∇f(x)T(y−x)≥θ2∣∣y−x∣∣2(∇f(y)−∇f(x))T(y−x)≥θ∣∣y−x∣∣2∇2f(x)≥θIn(8)f(y)-f(x)-\nabla f(x)^T(y-x) \ge \frac {\theta}{2}||y-x||^2 \\ \tag 8 (\nabla f(y)-\nabla f(x))^T(y-x) \ge \theta||y-x||^2 \\ \nabla ^2 f(x) \ge \theta I_n f(y)−f(x)−∇f(x)T(y−x)≥2θ∣∣y−x∣∣2(∇f(y)−∇f(x))T(y−x)≥θ∣∣y−x∣∣2∇2f(x)≥θIn(8)
等价的,有
f(y)−f(x)−∇f(x)T(y−x)≤Θ2∣∣y−x∣∣2(∇f(y)−∇f(x))T(y−x)≤Θ∣∣y−x∣∣2∇2f(x)≤ΘIn(9)f(y)-f(x)-\nabla f(x)^T(y-x) \le \frac {\Theta}{2}||y-x||^2 \\ \tag 9 (\nabla f(y)-\nabla f(x))^T(y-x) \le \Theta||y-x||^2 \\ \nabla ^2 f(x) \le \Theta I_n f(y)−f(x)−∇f(x)T(y−x)≤2Θ∣∣y−x∣∣2(∇f(y)−∇f(x))T(y−x)≤Θ∣∣y−x∣∣2∇2f(x)≤ΘIn(9)
引理2:
Lyapunov稳定性分析可以用来确定一个微分方程的稳定性.
对于一个系统,如果平衡状态受到扰动后,任然停留在稳定状态附近,则称为该稳定状态在Lyapunov定义下是稳定的.
如果平衡状态在受到扰动后,最终都会收敛到稳定状态,则称为渐进稳定的.
如果在稳定状态受到 任何扰动 后,最终都会收敛到稳定状态,则称为 大范围内渐进稳定的.
算法推导:
我们的目的是构造一个连续时间的分布式算法:
x˙i(t)=φi(xi(t),xNi(t);fi,fNi)xi(0)=xi∗(fi,fNi)(10)\dot{x}_i(t)=\varphi_i(x_i(t),x_{Ni}(t);f_i,f_{Ni}) \tag {10}\\ x_i(0) = x_i^*(f_i,f_{Ni}) x˙i(t)=φi(xi(t),xNi(t);fi,fNi)xi(0)=xi∗(fi,fNi)(10)
其中下标中带有N的表示i节点的邻接节点集合.x˙\dot{x}x˙表示x的一阶导数.对于这样的微分方程,我们希望他是稳定的,在一定的初值条件下最终能收敛到我们期望的状态.
通过f构造一个Lyapunov方程:
V(x)=sumi∈Vfi(x∗)−fi(xi)T(x∗−xi)(11)V(x)=sum_{i \in V}f_i(x^*)-f_i(x_i)^T(x^*-x_i) \tag {11} V(x)=sumi∈Vfi(x∗)−fi(xi)T(x∗−xi)(11)
当f为二阶可求导并且强凸时,根据公式(8)易知:
V(x)≥sumi∈Vθi2∣∣x∗−xi∣∣2≥0∀xinRnNV(x)→∞whenx→∞(12)V(x) \ge sum_{i \in V} \frac {\theta_i}{2}||x^*-x_i||^2 \ge 0 \ \ \ \ \ \ \forall x \ in R^{nN} \tag {12}\\ V(x) \to \infty \ \ \ when \ \ \ x \to \infty V(x)≥sumi∈V2θi∣∣x∗−xi∣∣2≥0 ∀x inRnNV(x)→∞ when x→∞(12)
因此,我们构造的方程是一个合法的Lyapunov方程(该方程取值大于等于0,且当x趋于无穷大时方程趋于无穷大,可以用来刻画系统的能量状态).
对公式(11)做对时间t的求导,可以得到:
V˙(x(t))=∑i∈V(xt(t)−x∗)∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)(13)\dot{V}(x(t))=\sum_{i \in V}(x_t(t)-x^*) \nabla ^2f_i(x_i(t)) \varphi_i(x_i(t),x_{N_i};f_i,f_{Ni}) \tag {13} V˙(x(t))=i∈V∑(xt(t)−x∗)∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)(13)
根据问题描述中的假设,每个φ\varphiφ都是局部李普希兹的.V′V'V′是连续的.并且,显然的V′(x∗)=0V'(x^*)=0V′(x∗)=0.因此,若果能到找到合适的φ\varphiφ使得
∑i∈V(xt(t)−x∗)∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)<0,∀x≠x∗(14)\sum_{i \in V}(x_t(t)-x^*) \nabla ^2f_i(x_i(t)) \varphi_i(x_i(t),x_{N_i};f_i,f_{Ni})<0, \forall x \ne x^* \tag {14} i∈V∑(xt(t)−x∗)∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)<0,∀x=x∗(14)
那么V′V'V′将在所有非x∗x^*x∗处小于0,整个系统将是Lyapunov渐进稳定的.
但是这样的φ\varphiφ很难构造.首先x∗x^*x∗对于每一个分布式计算节点都是未知的(如果已知那么问题已经得到了最优解).同时,每个节点在计算φ\varphiφ时只能利用到自己的fif_ifi和fNif_{Ni}fNi.因此我们不可以让φ\varphiφ 和x∗x^*x∗关联,例如令φ=x∗−x\varphi=x^*-xφ=x∗−x.
为了构造合适的φ\varphiφ,引入两个定义
agreementsetA={(y1,y2,...,yN)∈RnN:y1=y2=...=yN}(15)agreement\ set\ \ \ \mathscr{A}=\{(y_1,y_2,...,y_N) \in \mathbb{R}^{nN}:y_1=y_2=...=y_N\} \tag {15} agreement set A={(y1,y2,...,yN)∈RnN:y1=y2=...=yN}(15)
zero−gradient−summanifoldM={(y1,y2,...,yN)∈RnN:sumi∈V∇fi(yi)=0}(16)zero-gradient-sum\ manifold\ \ \mathscr{M}=\{(y_1,y_2,...,y_N) \in \mathbb{R}^{nN}:sum_{i \in V}\nabla f_i(y_i)=0\} \tag {16} zero−gradient−sum manifold M={(y1,y2,...,yN)∈RnN:sumi∈V∇fi(yi)=0}(16)
此时M\mathscr{M}M实际上就是一个流形,它的自由度是N-1.有x∗∈Ax^* \in \mathscr{A}x∗∈A,x∗∈Mx^* \in \mathscr{M}x∗∈M. 又因为
∀xinA∩M→x=x∗(17)\forall x \ in \mathscr{A} \cap \mathscr{M} \rightarrow x=x^* \tag {17} ∀x inA∩M→x=x∗(17)
所以A∩M={x∗}\mathscr{A} \cap \mathscr{M} = \{x^*\}A∩M={x∗}
接下来,在以上两个定义的基础上,给出以下的方法:
条件(14)确保了x沿着任意一条轨迹都将收敛到稳定状态,但这不是必须的.我们只要找出一条轨迹,在这个轨迹上x始终满足(14),那么x沿着这一条轨迹就可以收敛到稳定状态.
观察公式(13),可以得出
V˙(x(t))=Φ1(x(t)−x∗TΦ2(x(t))∀t≥0(18)\dot{V}(x(t))=\Phi_{1}(x(t)-x^{*T}\Phi_2(x(t))\ \forall t \ge 0 \tag {18} V˙(x(t))=Φ1(x(t)−x∗TΦ2(x(t)) ∀t≥0(18)
.如果我们可以让Φ2=0\Phi_2=0Φ2=0,那么(˙V)\dot(V)(˙V)就会与x∗x^*x∗无关.即需要:
∑∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)=0(19)\sum \nabla ^2f_i(x_i(t)) \varphi_i(x_i(t),x_{N_i};f_i,f_{Ni}) = 0 \tag {19} ∑∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)=0(19)
于是(˙V)\dot(V)(˙V)变成:
V˙(x(t))=∑i∈Vxt(t)∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)(20)\dot{V}(x(t))=\sum_{i \in V}x_t(t) \nabla ^2f_i(x_i(t)) \varphi_i(x_i(t),x_{N_i};f_i,f_{Ni}) \tag {20} V˙(x(t))=i∈V∑xt(t)∇2fi(xi(t))φi(xi(t),xNi;fi,fNi)(20)
这时只要让公式(20)小于0,我们的算法就会收敛.注意到公式(19)和假设(10),我们得到:
ddt∑i∈V∇fi(xi(t))=∑i∈V∇2fi(xi(t))xi˙(t)=0(21)\frac {d}{dt} \sum_{i \in V} \nabla f_i(x_i(t)) = \sum_{i \in V} \nabla ^2f_i(x_i(t))\dot{x_i}(t)=0 \tag {21} dtdi∈V∑∇fi(xi(t))=i∈V∑∇2fi(xi(t))xi˙(t)=0(21)
如果要满足
limt→∞x(t)=x∗(21)\lim_{t \to \infty} x(t) = x^* \tag {21} t→∞limx(t)=x∗(21)
那么由(21)知,应有:
limt→∞ddt∑i∈V∇fi(xi(t))=ddt∑i∈V∇fi(limt→∞xi(t))=∑i∈V∇fi(x∗)=∇F(x∗)=0(22)\lim_{t \to \infty}\frac {d}{dt} \sum_{i \in V} \nabla f_i(x_i(t)) = \frac {d}{dt} \sum_{i \in V} \nabla f_i(\lim_{t \to \infty}x_i(t))=\sum_{i \in V} \nabla f_i(x^*) = \nabla F(x^*)=0 \tag {22} t→∞limdtdi∈V∑∇fi(xi(t))=dtdi∈V∑∇fi(t→∞limxi(t))=i∈V∑∇fi(x∗)=∇F(x∗)=0(22)
也就是说,在迭代过程中,每个节点的x梯度和应该始终保持为0. 这里,可以导出初值条件, 所有节点的初值可以这样设置:每个节点的x是当前节点的最优解.(这是满足条件的轨迹上的一个点.)当然这不是唯一可选的初值,但确实最容易构造的初值.
上图解释了前边的推理过程.首先看左图,如果公式(14)除了初值以外均小于0,那么我们从任意的初始位置出发(图中给了3个绿色的点,代表随机选择的三个初值),都可以逐渐收敛到中心稳定的红色点位置. 但实际上,我们只要找出一条确定的收敛路径即可.有图中蓝色的线就只这一条确定的路线.在这条路径上分布式计算节点的梯度和始终都是0.这条路径上有一个特殊的点,很容易找到,也就是每个分布式计算点的本地最优解.
到此为止,只剩φ\varphiφ没有确定了.观察公式(20),φ\varphiφ总是左乘一个非奇异的∇2fi(xi(t))\nabla ^2f_i(x_i(t))∇2fi(xi(t)),所以我们这样构造φ\varphiφ:
φi=(∇2fi(xi))−1ϕi(xi,xNi;fi,fNi)(23)\varphi_i = (\nabla^2f_i(x_i))^{-1}\phi_i(x_i,x_{Ni};f_i,f_{Ni}) \tag {23} φi=(∇2fi(xi))−1ϕi(xi,xNi;fi,fNi)(23)
根据(20)应该小于0,结合公式(19),有:
∑i∈Vϕi=0∀x∈RnN∑i∈VxiTϕi<0∀x∈RnN−A(24)\sum_{i \in V}\phi_i = 0 \ \ \forall x \in \mathbb{R^{nN}} \tag {24}\\ \sum_{i \in V} x_i^T \phi_i <0 \ \ \forall x \in \mathbb{R^{nN} - \mathscr{A}} i∈V∑ϕi=0 ∀x∈RnNi∈V∑xiTϕi<0 ∀x∈RnN−A(24)
这时,x的迭代表达式可以写成:
xt˙(t)=(∇2fi(xi(t)))−1∑j∈Niϕij(xi(t),xj(t);fi.fj)ϕi=∑j∈Niϕij(25)\dot{x_t}(t) = (\nabla^2f_i(x_i(t)))^{-1}\sum_{j \in N_i}\phi_{ij}(x_i(t),x_j(t);f_i.f_j) \tag {25} \\ \phi_i = \sum_{j \in N_i}\phi_{ij} xt˙(t)=(∇2fi(xi(t)))−1j∈Ni∑ϕij(xi(t),xj(t);fi.fj)ϕi=j∈Ni∑ϕij(25)
只要让
ϕij=−ϕji(26)\phi_{ij}=-\phi_{ji} \tag {26} ϕij=−ϕji(26)
公式(24)的第一个等式就可以成立.带入(24)的不等式,得到
∑i∈VxiTϕi=12∑i∈V∑j∈Ni(xi−xj)Tϕij(27)\sum_{i \in V} x_i^T \phi_i = \frac{1}{2}\sum_{i \in V}\sum_{j \in N_i}(x_i-x_j)^T\phi_{ij} \tag {27} i∈V∑xiTϕi=21i∈V∑j∈Ni∑(xi−xj)Tϕij(27)
对于∀x∈RnN−A\forall x \in \mathbb{R}^{nN} - \mathscr{A}∀x∈RnN−A, (27)中的xi−xjx_i-x_jxi−xj都不等于0.于是(24)不等式成立的条件可以是:
(y−z)Tϕij(y.z;fi,fj)<0,∀i∈v,∀j∈Ni,∀y,z∈Rn,y≠z(28)(y-z)^T\phi_{ij}(y.z;f_i,f_j)<0,\ \ \ \forall i \in v ,\ \forall j \in N_i,\ \forall y,z \in \mathscr{R}^n,\ y \ne z \tag{28} (y−z)Tϕij(y.z;fi,fj)<0, ∀i∈v, ∀j∈Ni, ∀y,z∈Rn, y=z(28)
此时我们只需要考虑图中的一部分节点,对于节点i,需要满足(28)成立,但对于节点j,只要简单的利用(26)确定ϕ\phiϕ即可.
以下给出一些合适的ϕ\phiϕ的例子.
Example1:
ϕij(y,z;fi,fj)=(ψij1(y1,z1),ψij2(y2,z2),...,ψijn(yn,zn))ψijk(yk,zk)=−ψijk(zk,yk)(yk−zk)ψijk(yk,zl)<0∀yk≠zk\phi_{ij}(y,z;f_i,f_j)=(\psi_{ij1}(y_1,z_1),\psi_{ij2}(y_2,z_2),...,\psi_{ijn}(y_n,z_n)) \\ \psi_{ijk}(y_k,z_k)=-\psi_{ijk}(z_k,y_k)\\ (y_k-z_k)\psi_{ijk}(y_k,z_l) < 0 \ \ \forall y_k \ne z_k \\ ϕij(y,z;fi,fj)=(ψij1(y1,z1),ψij2(y2,z2),...,ψijn(yn,zn))ψijk(yk,zk)=−ψijk(zk,yk)(yk−zk)ψijk(yk,zl)<0 ∀yk=zk
e.g.ϕijk(yk,zk)=tanh(zk−yk)e.g.ϕijk(yk,zk)=zk−yk1+yk2e.g. \ \ \phi_{ijk}(y_k,z_k)=tanh(z_k-y_k)\\ e.g. \ \ \phi_{ijk}(y_k,z_k)=\frac{z_k-y_k}{1+y_k^2} e.g. ϕijk(yk,zk)=tanh(zk−yk)e.g. ϕijk(yk,zk)=1+yk2zk−yk
Example2:
ϕij(y,z;fi,fj)=∇g{i,j}(z)−∇g{i,j}(y)\phi_{ij}(y,z;f_i,f_j)=\nabla g\{i,j\}(z)-\nabla g\{i,j\}(y) ϕij(y,z;fi,fj)=∇g{i,j}(z)−∇g{i,j}(y)
其中g{i,j}g\{i,j\}g{i,j}可以是任意的二阶连续可导并且局部强凸的函数.例如
g{i,j}(y)=12yTA{i,j}yg\{i,j\}(y)=\frac{1}{2}y^TA\{i,j\}y g{i,j}(y)=21yTA{i,j}y
其中A是任意的对称正定矩阵.
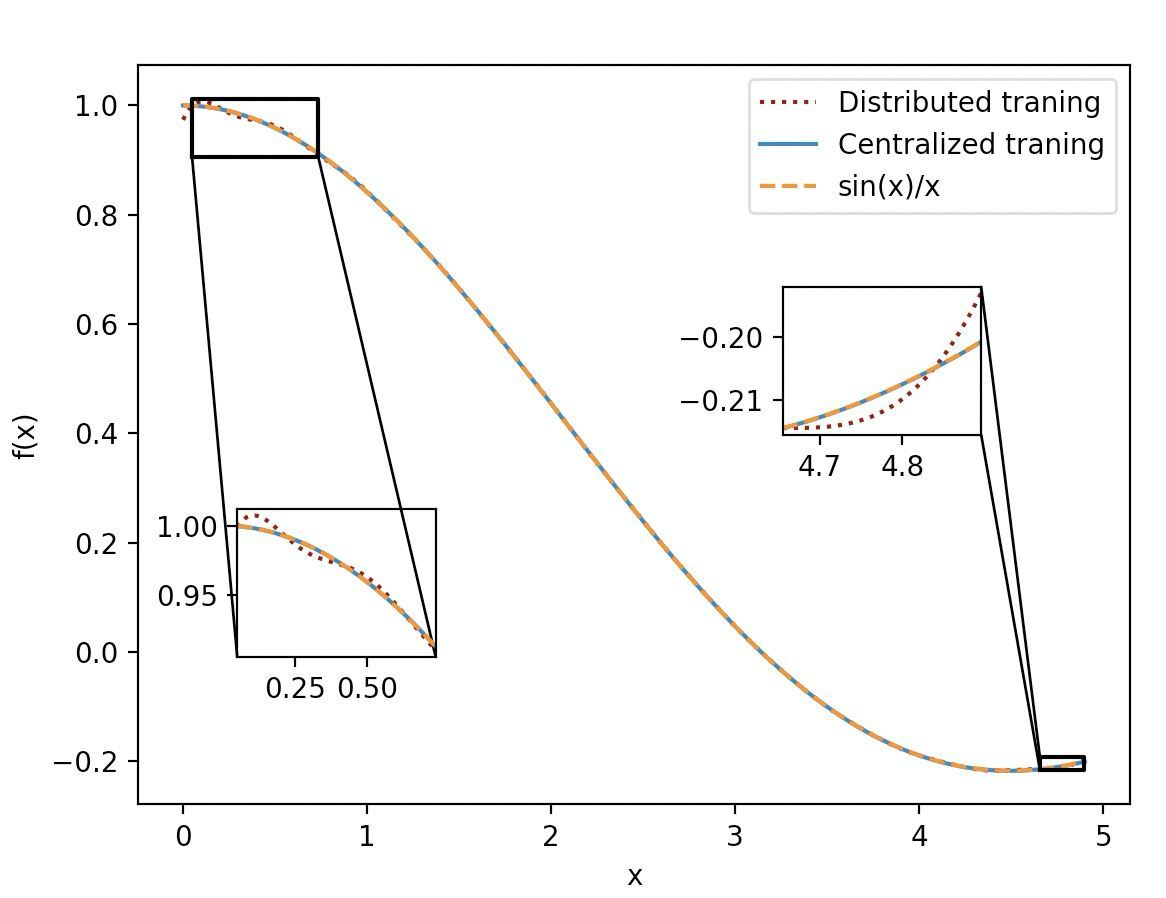
实验
利用算法描述里的公式(6),使用10000个样本在macbook上进行了实验.测试函数为sin(x)/x
参考文献
[1]Cheng-Tao Chu,Sang Kyun Kim,Yi-An Lin, et al.Map-Reduce for Machine Learning on Multicore[C].//Advances in neural information processing systems 19 :.2007:281-288.
[2]Diakonikolas I, Kane D M, Kontonis V, et al. Algorithms and sq lower bounds for pac learning one-hidden-layer relu networks[C]//Conference on Learning Theory. PMLR, 2020: 1514-1539.
[3]Lu J, Tang C Y. Zero-gradient-sum algorithms for distributed convex optimization: The continuous-time case[J]. IEEE Transactions on Automatic Control, 2012, 57(9): 2348-2354.








