您现在的位置是:主页 > news > 做简历用的网站/网站排名查询工具
做简历用的网站/网站排名查询工具
![]() admin2025/5/7 23:41:29【news】
admin2025/5/7 23:41:29【news】
简介做简历用的网站,网站排名查询工具,福田网站建设论文结论,网站备案年限自定义elasticsearch插件实现 1 插件项目结构 这是一个传统的maven项目结构,主要是多了一些插件需要的的目录和文件 plugin.xml和plugin-descriptor.properties这两个是插件的主要配置和描述 pom.xml里面也有一些插件的配置pom.xml文件 <?xml version"…
自定义elasticsearch插件实现
1 插件项目结构
这是一个传统的maven项目结构,主要是多了一些插件需要的的目录和文件
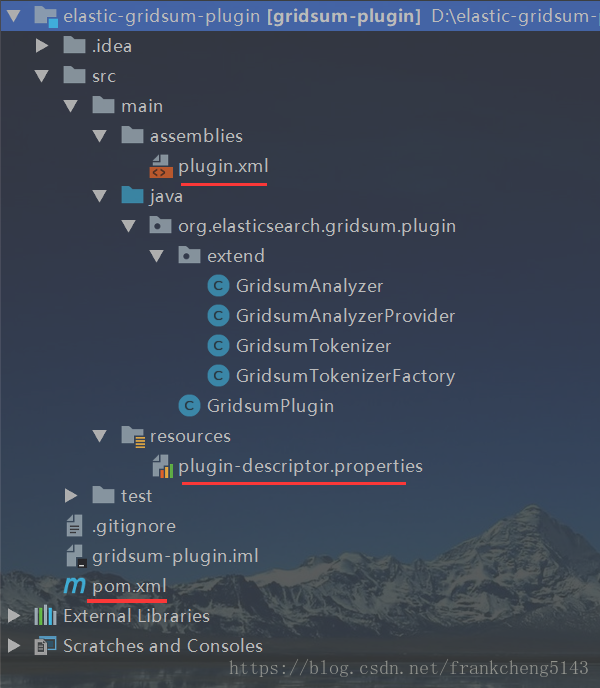
plugin.xml和plugin-descriptor.properties这两个是插件的主要配置和描述
pom.xml里面也有一些插件的配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><name>analysis-gridsum</name><groupId>org.elasticsearch</groupId><artifactId>gridsum-plugin</artifactId><version>0.0.1</version><description>gridsum elasticsearch plugin 国双elasticsearch自定义分词插件</description><properties><elasticsearch.version>6.4.1</elasticsearch.version><lucene.version>7.5.0</lucene.version><maven.compiler.target>1.8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>${elasticsearch.version}</version><scope>provided</scope></dependency><!-- Testing --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.7</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.7</version><scope>test</scope></dependency><dependency><groupId>org.elasticsearch.test</groupId><artifactId>framework</artifactId><version>${elasticsearch.version}</version><scope>test</scope></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-test-framework</artifactId><version>${lucene.version}</version><scope>test</scope></dependency></dependencies><build><resources><resource><directory>src/main/resources</directory><filtering>false</filtering><excludes><exclude>*.properties</exclude></excludes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.6</version><configuration><appendAssemblyId>false</appendAssemblyId><outputDirectory>${project.build.directory}/releases/</outputDirectory><descriptors><descriptor>${basedir}/src/main/assemblies/plugin.xml</descriptor></descriptors></configuration><executions><execution><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version><configuration><source>${maven.compiler.target}</source><target>${maven.compiler.target}</target></configuration></plugin></plugins></build>
</project>
plugin.xml文件
<?xml version="1.0"?>
<assembly><id>analysis-gridsum</id><formats><format>zip</format></formats><includeBaseDirectory>false</includeBaseDirectory><fileSets><fileSet><directory>${project.basedir}/config</directory><outputDirectory>config</outputDirectory></fileSet></fileSets><files><file><source>${project.basedir}/src/main/resources/plugin-descriptor.properties</source><outputDirectory/><filtered>true</filtered></file></files><dependencySets><dependencySet><outputDirectory/><useProjectArtifact>true</useProjectArtifact><useTransitiveFiltering>true</useTransitiveFiltering><excludes><exclude>org.elasticsearch:elasticsearch</exclude></excludes></dependencySet></dependencySets>
</assembly>plugin-descriptor.properties文件
description=${project.description}
version=${project.version}
name=${project.name}
classname=org.elasticsearch.gridsum.plugin.GridsumPlugin
java.version=${maven.compiler.target}
elasticsearch.version=${elasticsearch.version}
把项目结构和这几个文件添加好之后就可以编写插件了。
2 插件主要实现类和方法
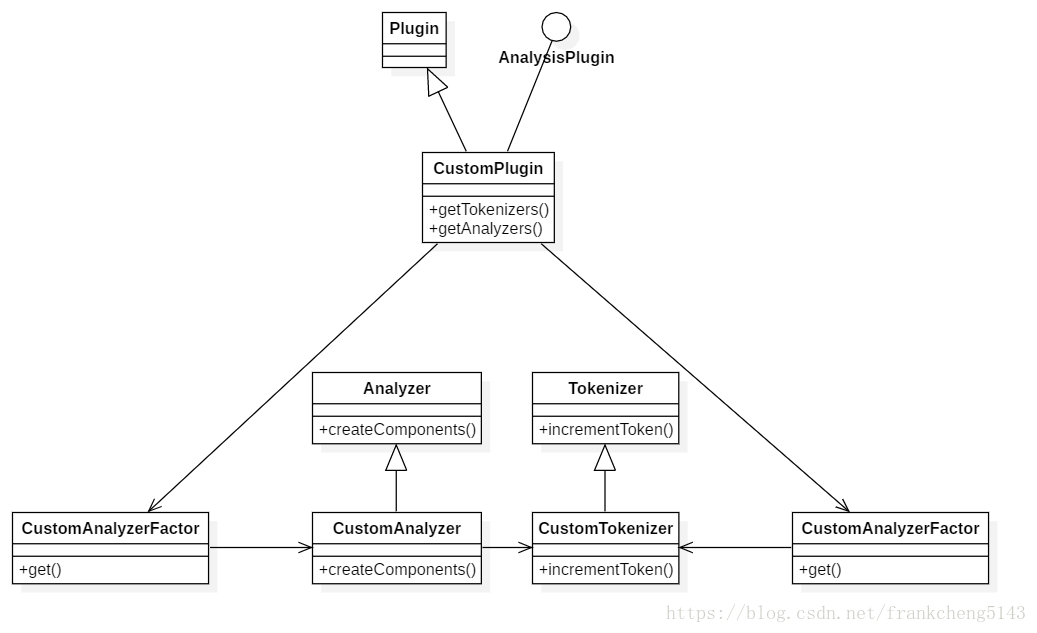
2.1 开发插件只需要继承Plugin实现AnalysisPlugin就可以了
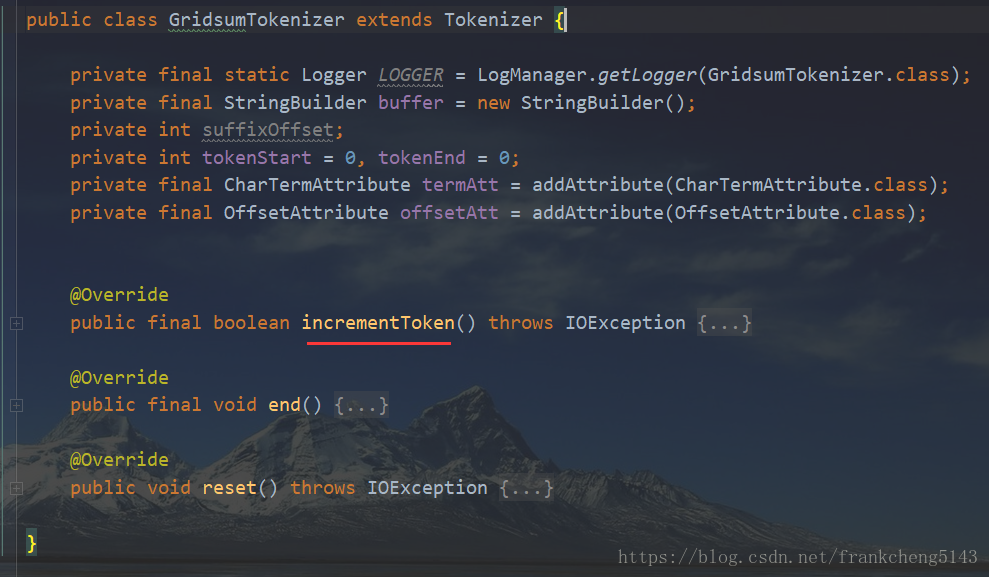
GridsumTokenizer是分词器,继承Tokenizer,通过重写incrementToken方法来实现自己的分词程序
GridsumAnalyzer是分析器,继承Analyzer,里面需要塞一个分词器
GridsumAnalyzerProvider是分析器提供程序,继承AbstractIndexAnalyzerProvider,通过重写get方法返回自定义分析器
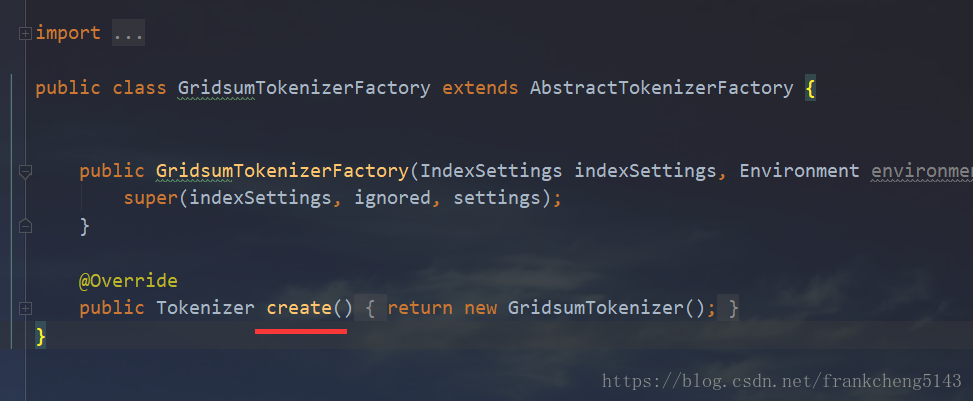
GridsumTokenizerFactory是分词器工厂,继承AbstractTokenizerFactory,通过重写create方法返回自定义的分词器
GridsumPlugin自定义插件的主要实现,继承Plugin实现AnalysisPlugin,通过重写getTokenizers将分词器工厂放入map,通过重写getAnalyzers将分析器放入map(这里的key后面会用到)
结构图如下
先来看一下自定义Tokenzier,最主要的是incrementToken方法
再看一下自定义Tokenizer工厂,主要的方法是create方法返回自定义Tokenizer
看一下自定义Analyzer
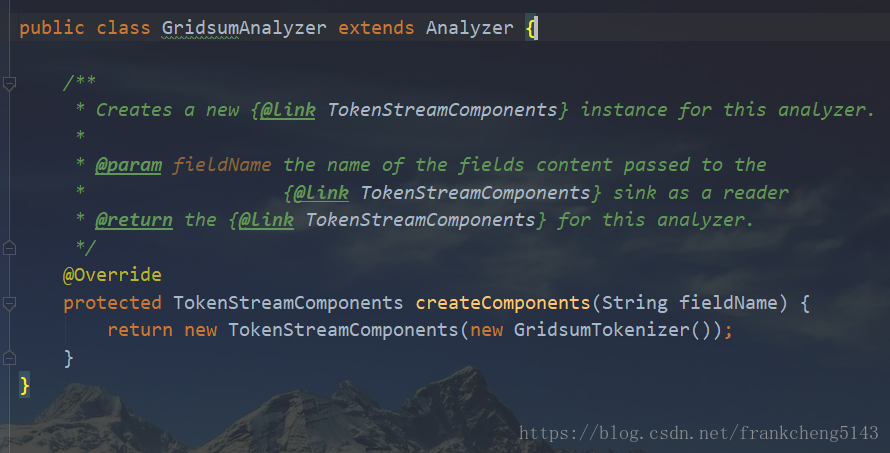
在createComponents方法中返回TokenStreamComponents,里面塞了一个我们的自定义Tokenizer
再看一下Analyzer工厂
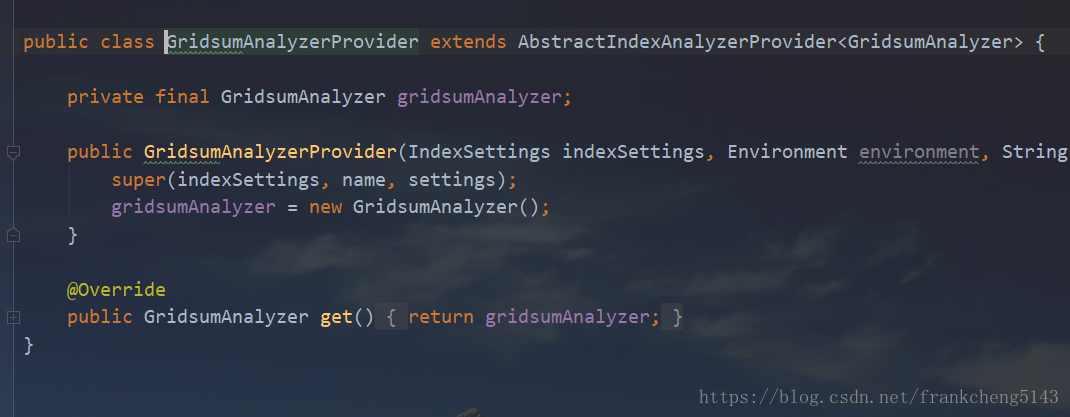
主要返回一个自定义Analyzer
最终我们看一下自定义Plugin
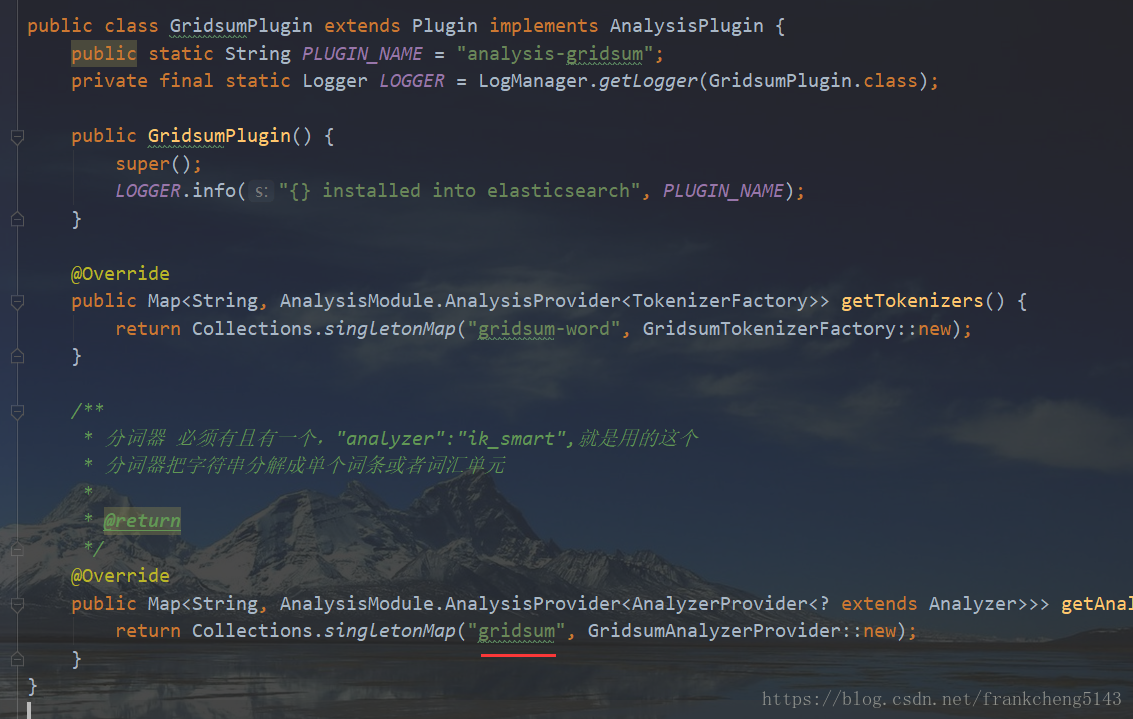
到这里整个插件的结构就完成了。
2.2 实现自己的分词程序
整个自定义分词的最关键方法就是自定义分词器GridsumTokenizer的incrementToken方法,通过重写该方法来实现自定义分词功能
在网上找的一个空格分词的实现
package org.elasticsearch.gridsum.plugin.extend;import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;import java.io.IOException;public class GridsumTokenizer extends Tokenizer {private final static Logger LOGGER = LogManager.getLogger(GridsumTokenizer.class);private final static String PUNCTION = " -()/";private final StringBuilder buffer = new StringBuilder();private int suffixOffset;private int tokenStart = 0, tokenEnd = 0;private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);@Overridepublic final boolean incrementToken() throws IOException {clearAttributes();buffer.setLength(0);int ci;char ch;tokenStart = tokenEnd;ci = input.read();if(ci>64&&ci<91){ci=ci+32;}ch = (char) ci;while (true) {if (ci == -1){if (buffer.length() == 0)return false;else {termAtt.setEmpty().append(buffer);offsetAtt.setOffset(correctOffset(tokenStart),correctOffset(tokenEnd));return true;}}else if (PUNCTION.indexOf(ch) != -1) {//buffer.append(ch);tokenEnd++;if(buffer.length()>0){termAtt.setEmpty().append(buffer);offsetAtt.setOffset(correctOffset(tokenStart),correctOffset(tokenEnd));return true;}else{ci = input.read();if(ci>64&&ci<91){ci=ci+32;}ch = (char) ci;}} else {buffer.append(ch);tokenEnd++;ci = input.read();if(ci>64&&ci<91){ci=ci+32;}ch = (char) ci;}}}@Overridepublic final void end() {final int finalOffset = correctOffset(suffixOffset);this.offsetAtt.setOffset(finalOffset, finalOffset);}@Overridepublic void reset() throws IOException {super.reset();tokenStart = tokenEnd = 0;}}3 验证与安装
本地测试方法如下
package org.elasticsearch.gridsum.plugin;import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.elasticsearch.gridsum.plugin.extend.GridsumAnalyzer;
import org.junit.Test;public class GridsumAnalyzerTest {@Testpublic void testAnalyzer() throws Exception {GridsumAnalyzer analyzer = new GridsumAnalyzer();TokenStream ts = analyzer.tokenStream("text", "我爱北京 天安门");CharTermAttribute term = ts.addAttribute(CharTermAttribute.class);ts.reset();while (ts.incrementToken()) {System.out.println(term.toString());}ts.end();ts.close();}}
输出结果
我爱北京
天安门
程序写完后打包
mvn clean package
打包后会生成一个本地的zip包,用来在elasticsearch进行安装
安装命令(windows)
elasticsearch bin目录> elasticsearch-plugin.bat install file:D:/elastic-gridsum-plugin/target/releases/gridsum-plugin-0.0.1.zip
如果提示已经存在了,请先卸载,不过前提是不要和系统的其他插件名称一致,名称是通过plugin.xml里面的<assembly><id>来定义的
卸载方法
elasticsearch bin目录> elasticsearch-plugin.bat remove analysis-gridsum
安装成功后启动elasticsearch
elasticsearch bin目录> elasticsearch.bat
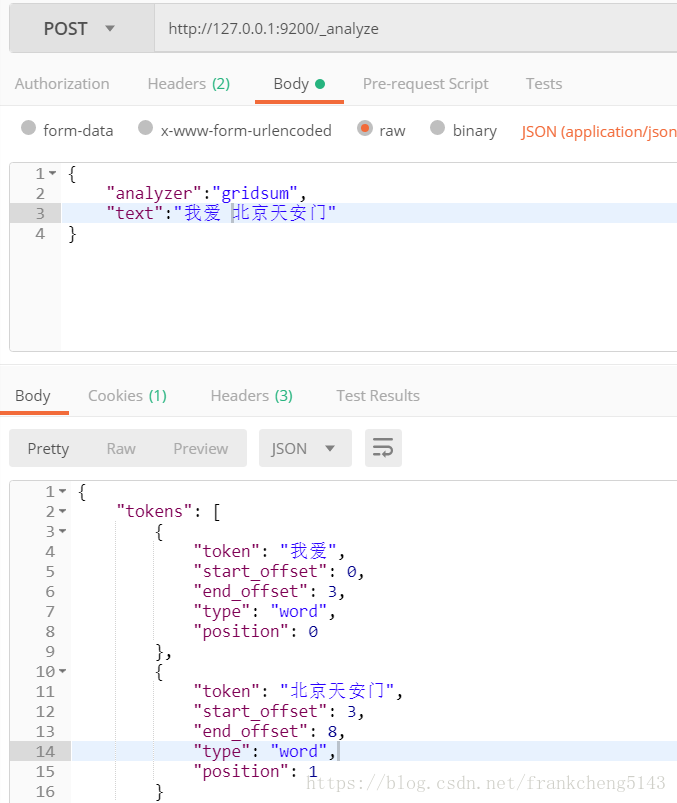
启动之后我们可以在postman验证一下
注意这里analyzer的key就是第二步重写getAnalyzers时map里面的key
完整项目下载地址
https://download.csdn.net/download/frankcheng5143/10691531
4 参考文献
官方文档
一个老外的文档
elasticsearch自带的各种分词器
姓名分词器
特殊分词器
空格分词实现








