您现在的位置是:主页 > news > 网站制作公司获取客户/成人技能培训
网站制作公司获取客户/成人技能培训
![]() admin2025/6/29 18:49:28【news】
admin2025/6/29 18:49:28【news】
简介网站制作公司获取客户,成人技能培训,网站广审怎么做,昆明企业网站建设一条龙tinyimagenet下载数据的保存方式 val文件夹下的文件 其中images是图片,val—annotations.txt是包含分类信息和框位置信息的标签文件,因为我用来做分类任务的,就没管后面的框,只提取了分类标签和图片名,有需要提取其他…
网站制作公司获取客户,成人技能培训,网站广审怎么做,昆明企业网站建设一条龙tinyimagenet下载数据的保存方式 val文件夹下的文件 其中images是图片,val—annotations.txt是包含分类信息和框位置信息的标签文件,因为我用来做分类任务的,就没管后面的框,只提取了分类标签和图片名,有需要提取其他…
tinyimagenet下载数据的保存方式
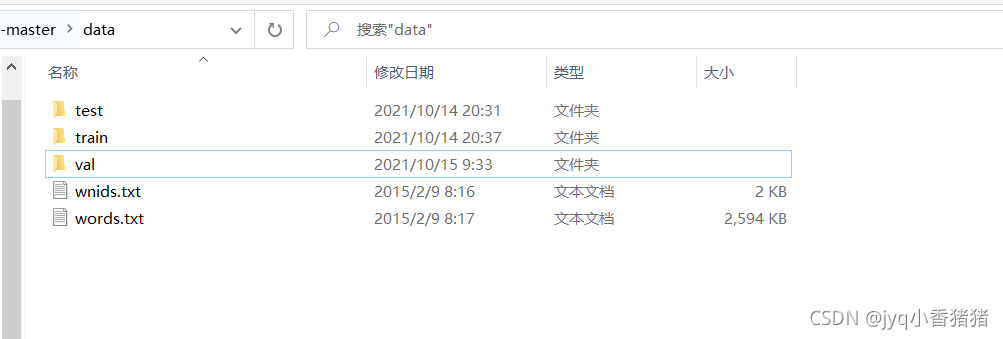
val文件夹下的文件

其中images是图片,val—annotations.txt是包含分类信息和框位置信息的标签文件,因为我用来做分类任务的,就没管后面的框,只提取了分类标签和图片名,有需要提取其他信息的可直接参考我代码中的a,b的来源
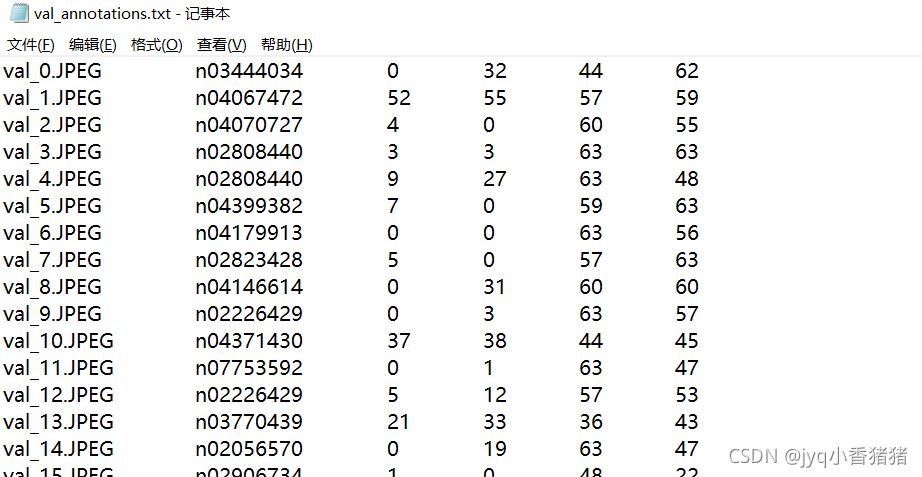
import os
import shutil
#因为我做分类,tinyimagenet一共有200个分类,val中每个分类有50张,所以先创建存放图片的文件夹
def mkdir(path):folder=os.path.exists(path)if not folder:os.makedirs(path)else:print(path)
if __name__=='__main__':
#tinyimagenet提供了200分类的txt,winds.txt,根据它创建file='data/val'with open('data/wnids.txt', 'r') as w:for line in w.readlines():line = line.strip('\n')folder=file+'/'+linemkdir(folder)
里面尚未有图片
#现在根据val_annotations.txt,来提取出images中的每一类图片,根据每一行图片的信息,来指定对应文件夹存放
with open("data/val/val_annotations.txt", 'r') as f:for line in f.readlines():line = line.strip('\n')dirlist = []imagelist=[]dir = line.split()dir_name = dir[1:2]image_name=dir[0:1]dirlist.append(dir_name)imagelist.append(image_name)a=dirlist[0][0]b=imagelist[0][0]image_path='data/val/images'+'/'+bdir_path='data/val'+'/'+ashutil.copy(image_path, dir_path)
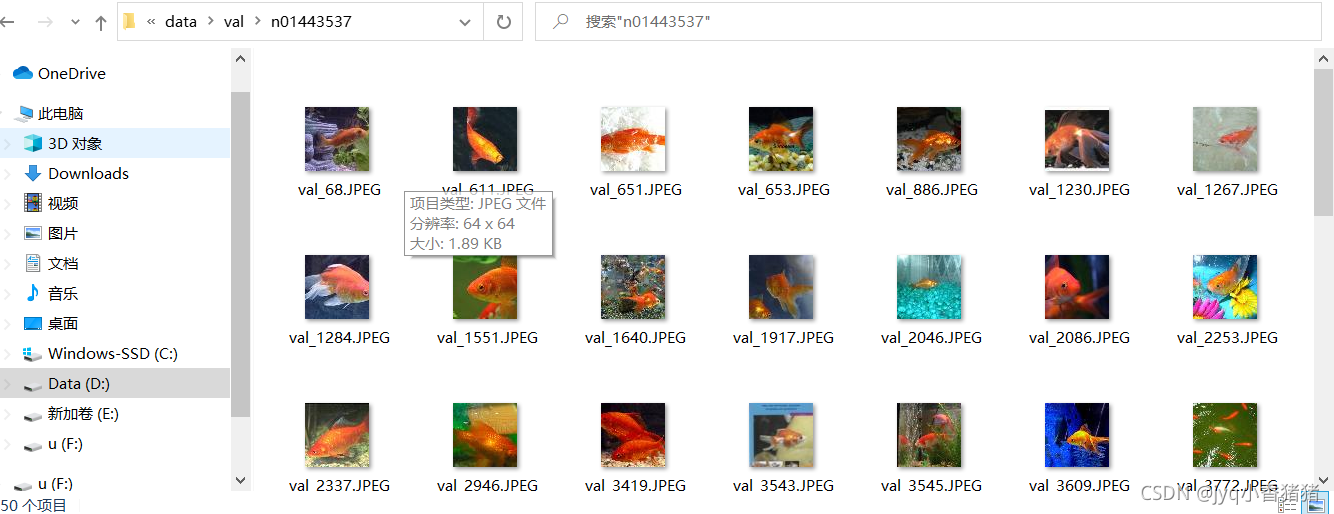
正好50个,类别也正确。这就处理结束了!程序还是有有点冗长,感觉有许多操作可以更加简化,不过还是可以的。








