您现在的位置是:主页 > news > 宁波做外贸网站推广/google网站入口
宁波做外贸网站推广/google网站入口
![]() admin2025/6/27 0:52:41【news】
admin2025/6/27 0:52:41【news】
简介宁波做外贸网站推广,google网站入口,做纯净系统的网站,网站如何制作 优帮云1. 论文研究的主要问题 文章认为多尺度匹配问题是行人搜索任务中的重要挑战。行人检索不同于行人重识别,行人检索是在一个没有限制的场景下检索行人,考虑到自动检索行人的需求,行人的检测框可能是包含错误结果和未知程度的误对齐的剪裁结果&…
1. 论文研究的主要问题
文章认为多尺度匹配问题是行人搜索任务中的重要挑战。行人检索不同于行人重识别,行人检索是在一个没有限制的场景下检索行人,考虑到自动检索行人的需求,行人的检测框可能是包含错误结果和未知程度的误对齐的剪裁结果,这个行人重识别的匹配带来了更大的挑战。
自动检测到的行人边界框尺度变化(分辨率)往往比行人重识别的边界框变化要大,如图 b 所示。尺度变化主要是由于摄像头和行人之间的不可控制的距离产生的,其本质问题是多尺度匹配问题。

2. 主要工作
为了解决多尺度匹配问题,提出了 Cross-Level Semantic Alignment (CLSA)深度学习方法。主要包括行人检测和行人重识别两个组件。

2.1 行人检测模块
选择 Faster-RCNN 作为检测模块,并在此基础上进行微调。将 ROI Pooling 层替换成 剪切并缩放区域特征图,然后再最大池化。
ResNet-50 再 ImageNet-1K 预训练后,固定第一个块的参数进行微调。
保留所有尺寸的候选框,以减少极端尺寸下的误检。
2.2 跨语义对齐的多尺度匹配
借助深度卷积神经网络 (CNN) 中的多尺度特征表示学习,在单个输入图像尺度上可以形成的内置特征金字塔结构。
然而由于内置金字塔深度不同的层存在很大的语义差距,低层特征和高层特征联合使用会损害整体的性能。
因此引入 Cross-Level Semantic Alignment (CLSA) 学习机制来改进网络内特征金字塔。所有级别都对所需的高级行人身份语义进行编码。

为了训练行人身份匹配模型,还提出了语义对齐学习损失函数。
首先,为了训练行人身份匹配模型,我们采用了 softmax 交叉熵 (CE) 损失函数优化身份分类任务。
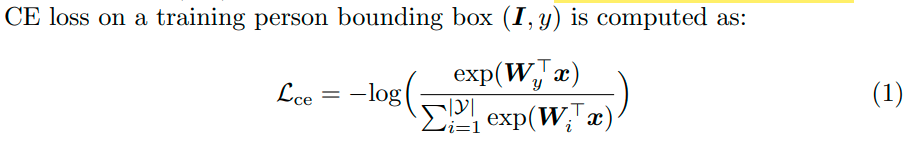
为了将最强的语义从金字塔的顶层(K-th)转移到较低的(s-th)层,在知识蒸馏的启发下引入了基于 Kullback-Leibler 散度的跨层语义对齐(CLSA)损失公式[ 16]:

为了端到端地训练模型,将 CLSA 损失加入整体损失中。

2.3 通过 CLSA 特征金字塔进行身份匹配
在部署中,首先通过前向传播任何给定的行人边界框图像来计算 CLSA 特征金字塔。 然后,将所有金字塔级别的特征向量连接起来作为行人重识别匹配的最终表示。
3. 实验
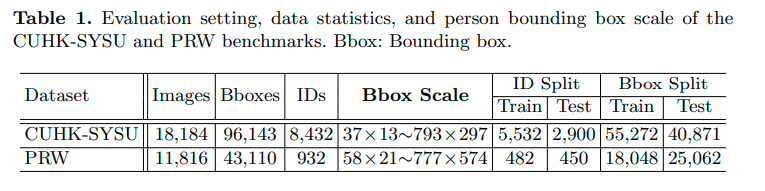
实验设置:在 Person Search 数据集 CUHK-SYSU 和 PRW 上进行实验,

两个数据集的行人 ID 数目、边界框 Bbox 数目和尺度如下表所示:
实验一:CUHK-SYSU 数据集上的评估
随着 gallery 搜索池的增大,所有的方法性能都有所下降。这主要是因为,当更多的分散的人加入身份匹配过程中时,行人搜索任务变得更有挑战性了。
相比其他方法,CLSA 具有更高的可扩展性和鲁棒性。当 gallery size 从 100 增加到 4,000 时, NPSM 的 mAP 从 77.9% 下降到 53.0%,下降了 24.9% 。而 CLSA 的 mAP 下降了 9.7% (77.5-87.2) ,Rank-1 下降了 9.1% (79.4-88.5) 。

在标准的 gallery size 100 下 , CLSA 在 CUHK-SYSU 数据集上达到了最优的 mAP 和 Rank-1 。

实验二:PRW 数据集上的评估
CLSA 在 PRW 数据集上达到了最优的 mAP 和 Rank-1 。

实验三:CLSA 和其他多尺度深度学习方法的对比
根据实验可以发现:直接应用 CNN 特征层次结构可能会由于不同金字塔级别之间的内在语义差异而损害模型性能。
CLSA 提出的跨层级语义对齐机制 cross-level semantic alignment mechanism 在端到端的学习方式下,增强了模型的行人匹配性能。
相比其他 SOTA 的多尺度深度学习方法,CLSA 的 FLOPs 也较低,具有较高的计算效率。

4. 分析和讨论
4.1 行人检测器的影响
针对 Faster-RCNN 的三个传统组件在 CUHK-SYSU 数据集上进行了消融实验,得出了行人检测组件对行人搜索任务的影响:
- 调整区域候选框大小和最大池化的操作不会损害模型的性能
- 微调检测器时冻结第一个块的参数有助于模型性能提高
- 使用所有尺寸的候选框有助于提高模型性能,同时不会降低模型性能

图 a :加入 CLSA 后的改进后的 Faster-RCNN 相比其他检测器模型更加稳定,ACF 和 CCF 随着召唤率的增加,准确率快速下降。
图 b :使用完美的行人检测框只带来了 CLSA 模型的微小性能提高,说明行人检测模型不是行人搜索的瓶颈。
图 c :各种多尺度模型都在 Baseline Resnet50 的基础上有所提高,说明了多尺度问题对于行人检索是否关键。

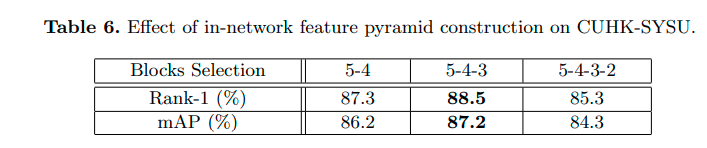
4.2 特征金字塔的影响
三层金字塔结构(5-4-3)结果最优,使用基础特征直接进行语义对齐可能会降低特征金字塔的表征能力。
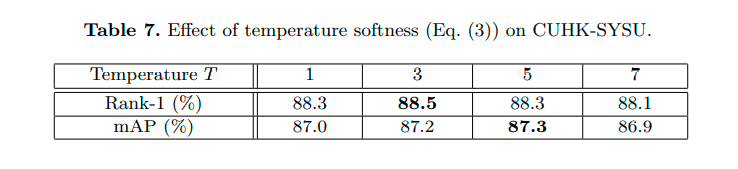
4.3 Temperature Softness 的影响
最优值为 3
4.4 在行人重识别和目标分类上的评估
CLSA 对行人重识别和目标分类任务都有助益。通过与 Resnet50 进行对比实验,发现:除了在不受约束的场景图像中进行人员搜索之外,针对一致且普遍存在问题,模型也具有优势。

5. 结论
为了解决跨尺度行人搜索问题,文章提出了一个端到端 CLSA 深度学习方法,通过构建网络内特征金字塔结构表示和语义对齐学习损失函数增强模型表示能力。








