您现在的位置是:主页 > news > wordpress会员互动/常用的seo查询工具
wordpress会员互动/常用的seo查询工具
![]() admin2025/6/26 0:52:35【news】
admin2025/6/26 0:52:35【news】
简介wordpress会员互动,常用的seo查询工具,海南住房和城乡建设部网站,wordpress菜单 标题属性首先,如果连值类型和引用类型都不明白的小白,最好先看看书,《C#入门经典》或《C#图解教程》都挺适合的。对很多刚入门的新手来说,可能犯过一个跟引用类型有关的错误。以下面控制台代码为例:public class ReferenceType…
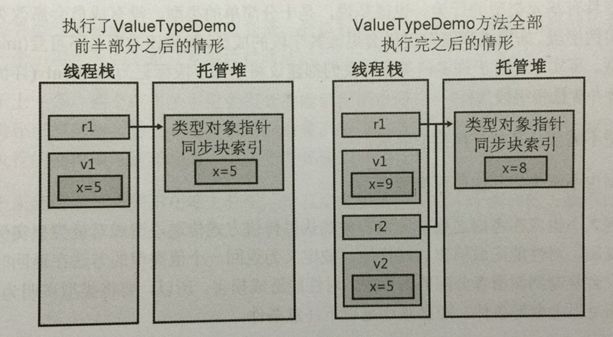
首先,如果连值类型和引用类型都不明白的小白,最好先看看书,《C#入门经典》或《C#图解教程》都挺适合的。
对很多刚入门的新手来说,可能犯过一个跟引用类型有关的错误。以下面控制台代码为例:
public class ReferenceType : IHaveID
{public long ID { get; set; }
}
public interface IHaveID
{long ID { get; set;}
}
在Main函数中:
private static void Main(string[] args)
{ReferenceType r1 = new ReferenceType();ReferenceType r2 = r1;IHaveID r3 = r1;r1.ID++;r2.ID++;//……
}
结果是r1、r2、r3的ID属性都变成了2。往往踩过一次坑之后,才理解了引用类型与值类型的不同。对引用类型来说,赋值只是复制了指向堆内存上的地址,所以r1、r2、r3其实还是一回事,对它们的任何操作,本质上还是对同一对象的操作。而值类型呢?例如下面的代码:
public struct Student : IHaveID{public long ID { get ; set ; }}
在Main函数中:
private static void Main(string[] args){Student c1 = new Student();Student c2 = c1;IHaveID c3 = c1;c1.ID++;//……}
结果是什么呢?c1的ID属性为1;c2为0;c3呢?还是0。对值类型来说,赋值相当于创建了一个新的实例(或者说拷贝了一个新的副本),所以c2为0很容易理解。c3呢?值类型是可以继承接口的,接口的本质还是类型(接口类型),所以“IHaveID c3 = c1”这行代码的实质是把一个值类型转化成引用类型,这就涉及到了“装箱”操作(Box)。装箱过程中一样会将原来的结构体拷贝一个新副本,然后将它对应的引用地址以接口类型的形式返回,所以……对c1的操作不会作用于c3。
在C#中,所有的类型都继承自System.Object类,其中,所有的值类型都继承自System.ValueType类。微软利用继承的特性在父类ValueType中规定好值类型的用法,比如重写了Object.Equals()的方法,将两个值类型的比较与引用类型区分开:引用类型的比较是比较内存中地址,而值类型的比较则是比较实例的数值。这是合理的,否则按照前者的方式,就会出现“1不等于1”的奇怪情况。
关于值类型和引用类型,笔者十分建议新手们去了解一下它们的区别,尤其是内存分配方面的差异(网上资料以及各类C#相关的技术书籍均有介绍,在此就不赘述了)。在适当的时候使用值类型,会带来比较明显的性能提升,但是需要注意值类型在传递过程中的装箱问题。比如新手入门最简单也是最常见的一个例子:控制台输出一个数字。很多人习惯写:
int num = 1;
Console.Write(num);
当然,这没有什么语法或者逻辑上的问题。但是从1到“1”的过程是什么样子呢?将int类型的num复制一个副本,装箱成引用类型(可以理解为新建一个类,将num的副本作为成员变量储存起来)。可是这里我们为什么需要装箱呢?所以良好的习惯是使用ToString()方法生成一个字符串对象来输出,这时候就不存在装箱操作了:
int num = 1;
Console.Write(num.ToString());
尽管大多数的情况下,装箱的损耗不会成为主要的性能瓶颈。但是既然可以尽力做得好一些,为什么不去做呢?尤其是,如果你接触过泛型,你就更没有借口不这样做了——因为泛型的出现,正是避免了大规模装箱带来的性能损耗。如果你接触过泛型,你就应该知道为什么从.Net 2.0开始,就不再建议使用集合的非泛型版本(淘汰ArrayList,使用List<T>)。
还要说一个关于值类型的小坑。对于Dictionary<TKey, TValue>,通常不建议使用引用类型作为Key(String类型除外)。对大多数情况来说,C#规定的元类型(如long、int等)就足够了;但可能某些极少的情况,我们会采用自定义的结构体作为Key。如:
public struct KeyStruct : IEquatable<KeyStruct>{public long Id { get; set; }public int SubId { get; set; }public bool Equals(KeyStruct other){return Id == other.Id && SubId == other.SubId;}public override bool Equals(object obj){if (obj is KeyStruct ks){return Equals(ks);}return false;}public override int GetHashCode(){//……}public override string ToString(){//……}}
那么请切记:一定要重写GetHashCode()方法!主要原因是一定要确保不同Key的HashCode绝不重复(这里的“绝不”是针对所有可能出现的Key值的范围而言),详情可以参考:Dictionary<TKey,TValue>。其实还是应当尽量避免这种情况,因为通常很难确定一个效率高的HashCode算法,而Dictionary的检索效率恰恰就跟HashCode算法的质量相关。
每个程序猿都曾经小白过,如果踩上什么坑,千万别放过提升对背后原理理解的好机会。好了,“就是这么坑”系列第二弹就先到这里吧。
参考文档:
装箱和取消装箱 - C# 编程指南docs.microsoft.com








