您现在的位置是:主页 > news > 做外贸怎么进入国外的网站/最火的网络推广平台
做外贸怎么进入国外的网站/最火的网络推广平台
![]() admin2025/6/22 14:57:17【news】
admin2025/6/22 14:57:17【news】
简介做外贸怎么进入国外的网站,最火的网络推广平台,wordpress隐藏播放器,用jsp做网站的感想计量经济学服务中心专辑汇总!计量百科资源干货:Stata|Python|Matlab|Eviews|RGeoda|ArcGis|GeodaSpace|SPSS一文读懂|数据资源|回归方法|网络爬虫门限回归|工具变量|内生性|空间计量 因果推断|合成控制法|倾向匹配得分|断点回归|双重差分面板数据| 动态面…
计量经济学服务中心专辑汇总!计量百科·资源·干货:Stata |Python |Matlab |Eviews |R Geoda |ArcGis |GeodaSpace |SPSS 一文读懂 |数据资源 |回归方法 |网络爬虫 门限回归 |工具变量 |内生性 |空间计量 因果推断 |合成控制法 |倾向匹配得分 |断点回归 |双重差分 面板数据 | 动态面板数据
?2021年寒假Stata研讨班:高级计量经济学及Stata应用研讨班
?2021空间计量研讨班:空间计量及Geoda、Stata、ArcGis、Matlab应用
SAR模型数据集包含对地理区域或其他单元的观测;所以需要的是有一些距离的度量标准来区分哪些单位彼此之间比较近。
spregress命令对横断面数据进行建模。它要求每一个观察都代表一个独特的空间单元。对于每个单元(即面板数据)有多个观察值的数据,请参见spxtregress命令。
为了使模型与内生性问题符合横截面数据,请参考spivregress。
gs2sls使用了广义空间两阶段最小二乘(gs2sls)的广义矩估计方法。ml使用最大似然(ml)估计。对于正态分布的数据,ml在理论上比gs2sls更有效,但是当数据是i.i.d的时候,spregress,gs2sls产生的结果与spregress,ml并没有多大区别。
vce(稳健)方差估计可与spregress, ml一起使用,产生对非标准i.i.d.误差稳健的标准误差。
1
权重矩阵
重要的是要理解加权矩阵的选择是SAR模型的一部分。
只根据邻近区域来定义空间滞后有意义吗?或者你想要模拟随着距离增加而减少的距离的影响?或者,您希望根据数据中的某些度量(例如国家之间的进出口价值)来建模空间滞后吗? Sp系统有spmatrix create命令,可以创建连续矩阵和 inverse-distance矩阵。例如,输入
spmatrix create contiguity W
产生了连续性W,创建一个对称加权矩阵W,对于连续空间具有相同的正权单位,默认情况下,所有其他单位的权值为零,还可以选择包括二阶邻居(邻居的邻居)的非零权值。还有用于创建自定义权重矩阵的Sp命令。
spregress、gs2sls和spregress、ml均可对具有多重空间滞后的模型进行拟合 独立变量。可以使用不同的空间权重指定多个ivarlag()选项 相同或不同变量的矩阵。
spregress, gs2sls和spregress, ml均能拟合具有多个独立变量空间滞后的模型。
对于相同或不同的变量,可以使用不同的空间权重矩阵指定多个ivarlag()选项。
使用gs2sls估计器,您还可以包含由两个或多个空间加权矩阵指定的相关变量空间滞后和自回归误差项。
为此,可以指定多个dvarlag()选项或多个errorlag()选项。
多重加权矩阵可以被看作是对真实因变量或误差空间依赖性的“高阶”近似,它们允许对空间滞后的公式进行测试。
使用ml估计器,您可以只包含一个dvarlag()和一个errorlag(),但是每个都可以有自己的空间加权矩阵,可能是不同的。
2
A spatial autoregressive model
我们想要模拟美国南部各县的谋杀率。homicide1990.dta包含
hrate,即每10万人每年的县级谋杀率;
ln-population,即县人口的对数;
ln-pdensity,人口密度的对数;
还有基尼系数(gini),即该县的基尼系数(gini coefficient),它是衡量收入不平等的指标,数值越大,代表的不平等越严重(gini 1909)。
数据是Messner等人(2000)最初使用的数据的摘录;参见Britt(1994)对该主题的文献综述。我们使用spshape2dta创建homicide1990.dtahe homicide1990 shp.dta。后一个文件包含美国南部各县的边界坐标。
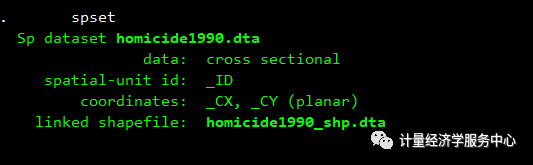
因为分析数据集和stata格式的shapefile必须在工作目录中才能设置数据,所以我们首先保存homicide1990.dta和homicide1990-shp.dta。使用copy命令将dta发送到工作目录。然后我们加载数据并输入spset来查看Sp设置。
代码为:
copy https://www.stata-press.com/data/r16/homicide1990.dta .copy https://www.stata-press.com/data/r16/homicide1990_shp.dta .use homicide1990spset结果为:

我们使用grmap命令在县地图上绘制谋杀率。结果如下:
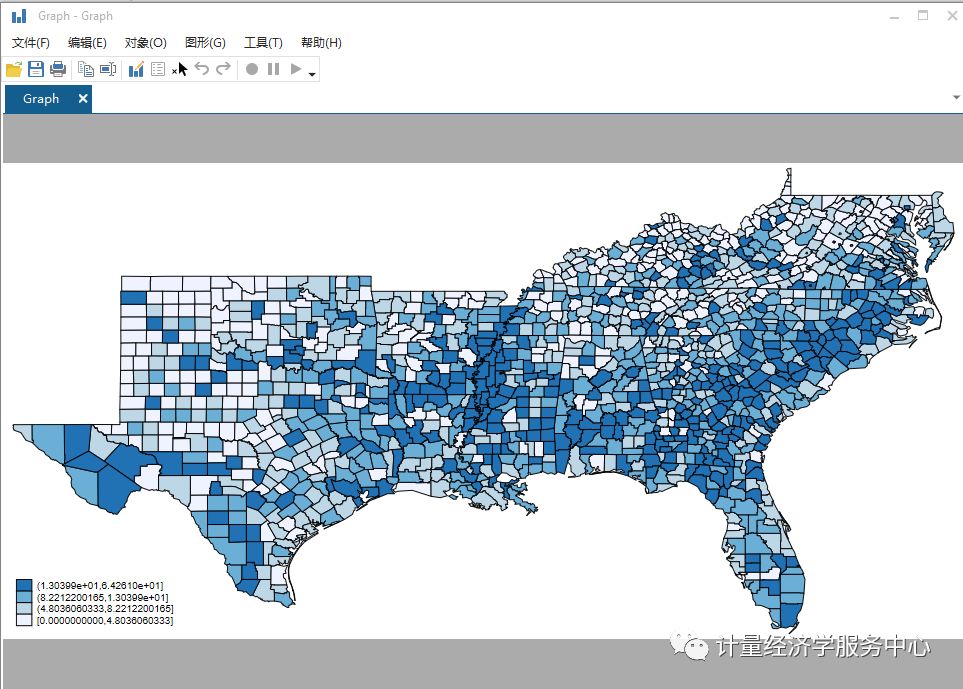
凶杀率似乎在空间上是相互依赖的,因为高自杀率的县似乎聚集在一起。我们可以拟合一个普通的线性回归,并使用Moran检验检验误差是否与空间相关。
为了进行测试,我们需要一个空间加权矩阵。我们将创建一个对相邻的县使用相同的正权值,而对所有其他县使用零权值的矩阵—称为连续矩阵。我们将使用默认的归一化矩阵。
生成空间权重矩阵代码为:
spmatrix create contiguity W结果为:

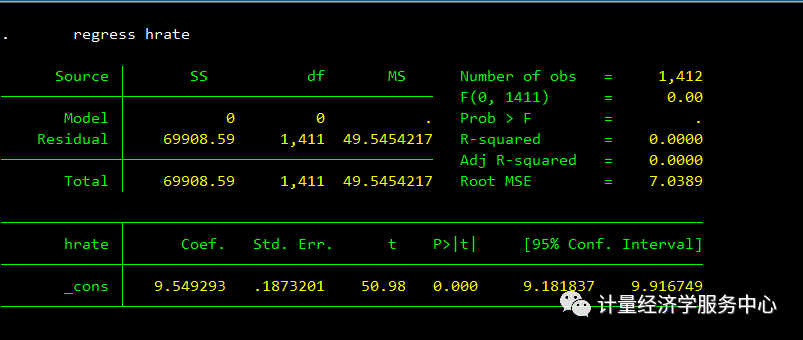
回归分析regress ,代码为:
regress hrate结果为:
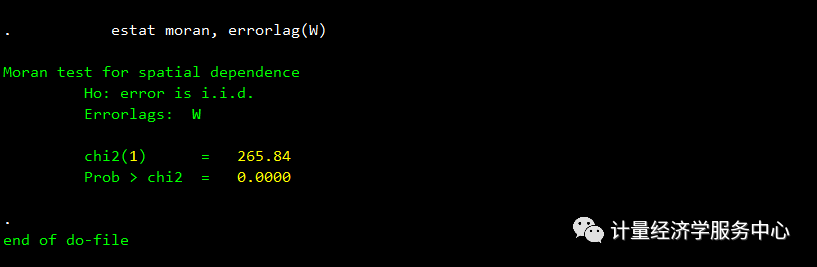
检验空间相关性,代码为:
estat moran, errorlag(W)结果为:
建立SAR模型,代码为:
spregress hrate ln_population ln_pdensity gini, gs2sls dvarlag(W)结果为:
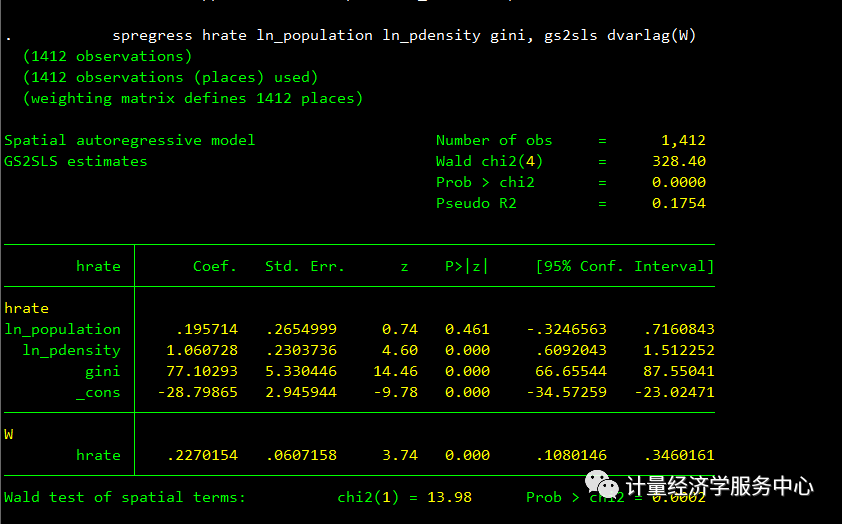
hrate空间滞后的估计系数为0.23,说明一个县的凶杀率与邻近县的凶杀率正相关。我们可以使用estat impact来解释结果,但首先我们将说明如何适用于其他SAR模型。
我们现在通过添加errorlag(W)来包含一个空间自回归误差项。代码为:
spregress hrate ln_population ln_pdensity gini, gs2sls dvarlag(W) errorlag(W结果为:
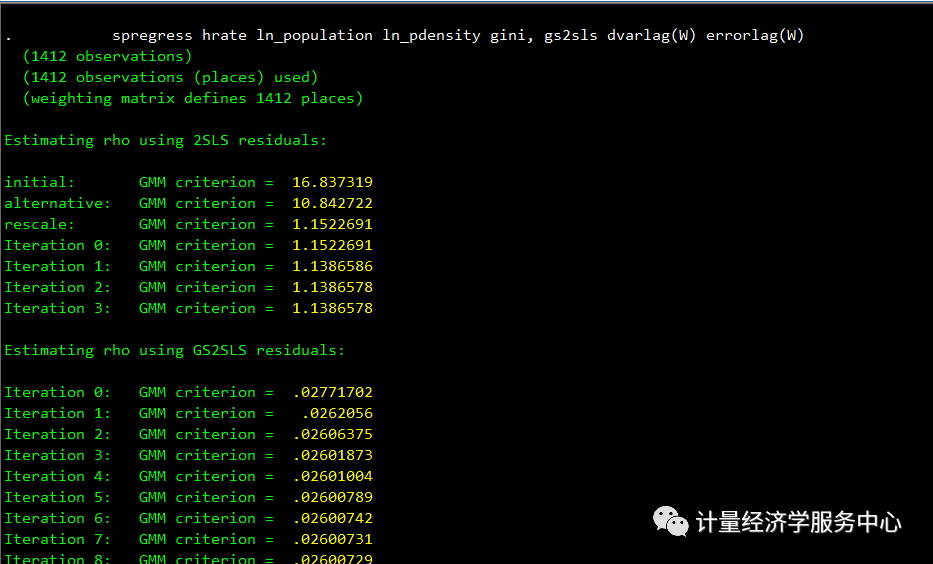
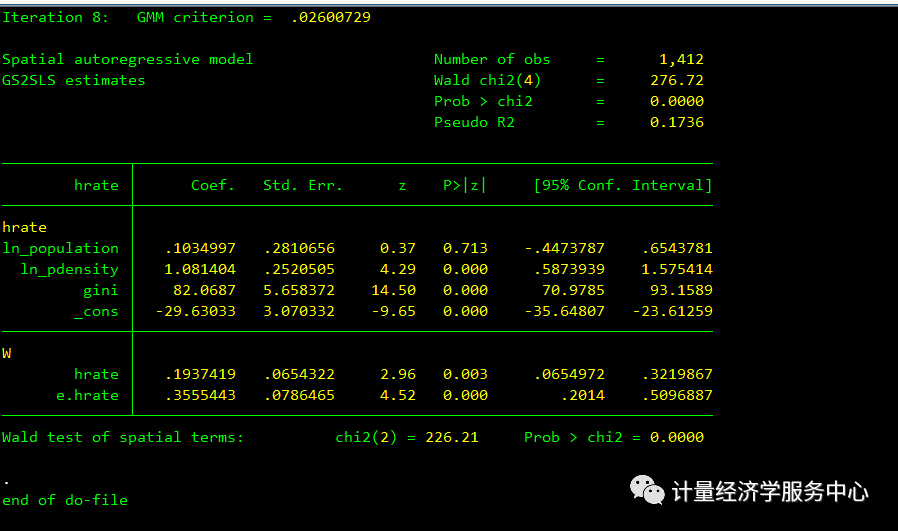
注意,当包含自回归误差项时,估计过程成为迭代广义矩法。
3
A spatial autoregressive model
我们保留SAR误差项e.hrate在我们的模型中,并使用ivarlag(W:::::)加入表示独立变量的空间滞后项。
代码为:
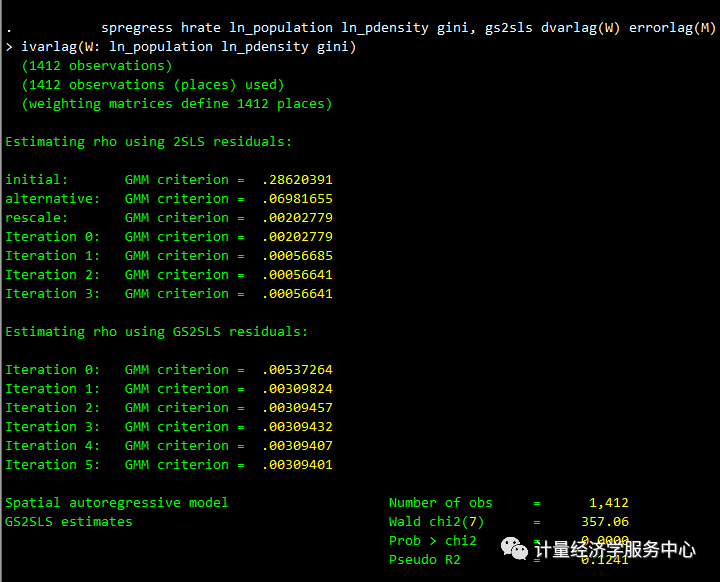
spregress hrate ln_population ln_pdensity gini, gs2sls dvarlag(W) errorlag(W) ivarlag(W: ln_population ln_pdensity gini)结果为:
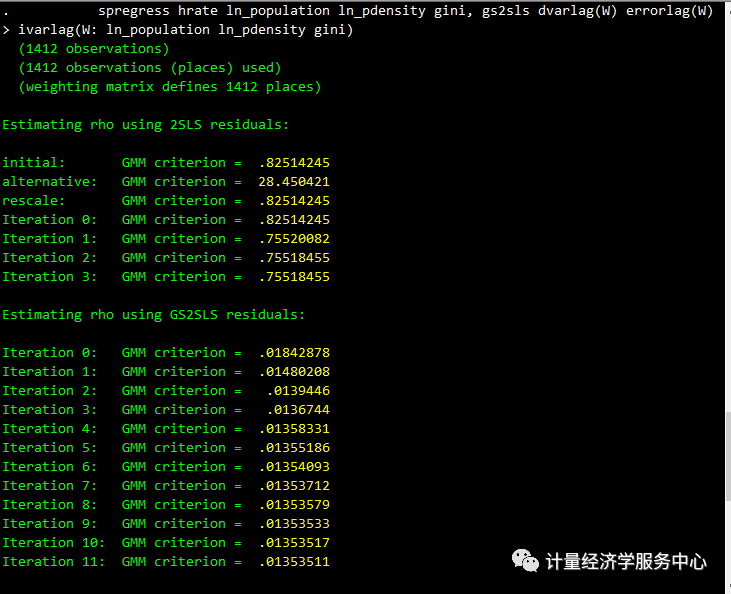
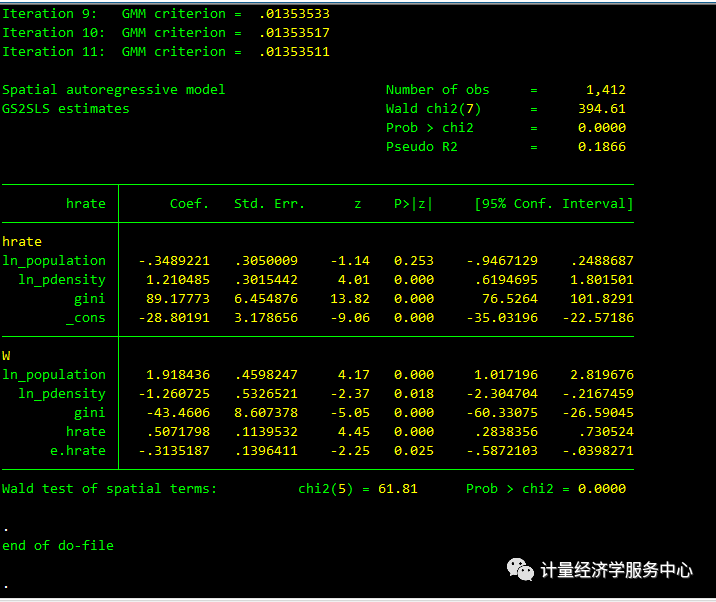
滞后变量和自回归误差项的系数显著。
我们常常不确定应该使用哪个空间加权矩阵来计算空间滞后。许多研究人员使用一个空间加权矩阵,其(i;j)第一个元素是单位i与单位j之间距离的倒数,这个逆距离矩阵具有许多优良的性质,在空间分析中有着悠久的历史。
使用GS2SLS估计,我们可以使用两个空间加权矩阵包含空间滞后,在这种情况下,我们可以将它们视为一起提供了对真实空间过程的“高阶”近似。在我们的模型中,仅使用连续矩阵,因变量存在空间滞后。现在,我们将包括它和另一个滞后的因变量使用逆距离矩阵。 我们使用默认的标准归一化创建反距离矩阵M,并使用spmatrix dir列出我们的Sp矩阵。
代码为:
spmatrix create idistance M spmatrix dir结果为:
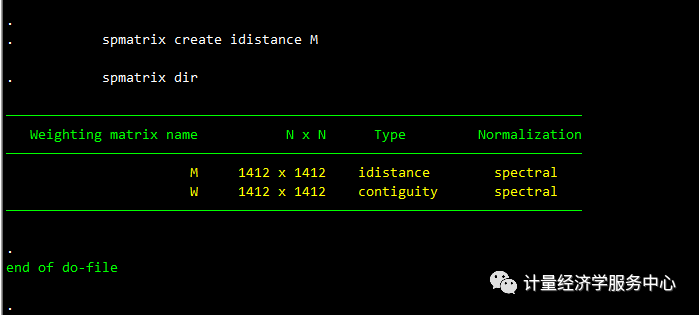
现在,我们将dvarlag(M)添加到模型中。
代码为:
spregress hrate ln_population ln_pdensity gini, gs2sls dvarlag(W) errorlag(W) ivarlag(W: ln_population ln_pdensity gini) dvarlag(M) 结果为:
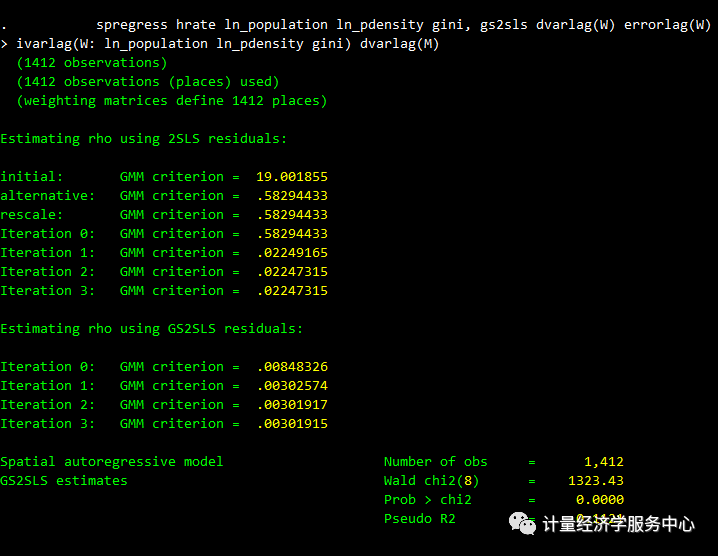
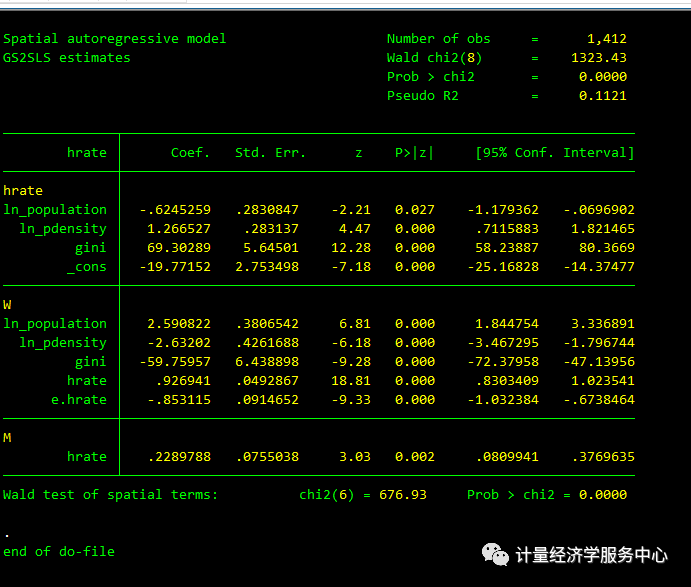
除了权重矩阵w,权重矩阵M设定的hrate滞后都是显著的,想要在我们的最终模型中包含两者。
我们可以重复这个过程,在errorlag(W)之外再拟合一个带有errorlag(M)的模型,在ivarlag(W::::)之外再拟合一个带有ivarlag(M::::)的模型。一个问题是,在这个例子中,我们“只有”N = 1412个空间单位(观测值)。为了适应高阶滞后,我们需要大量的空间单元,所以我们需要像在其他模型构建过程中一样进行判断。在我们的最后一个模型中,每一项都有一个加权矩阵。我们将W用于dvarlag()和 ivarlag(),但是M表示errorlag()。
代码为:
spregress hrate ln_population ln_pdensity gini, gs2sls dvarlag(W) errorlag(M) ivarlag(W: ln_population ln_pdensity gini)结果为:
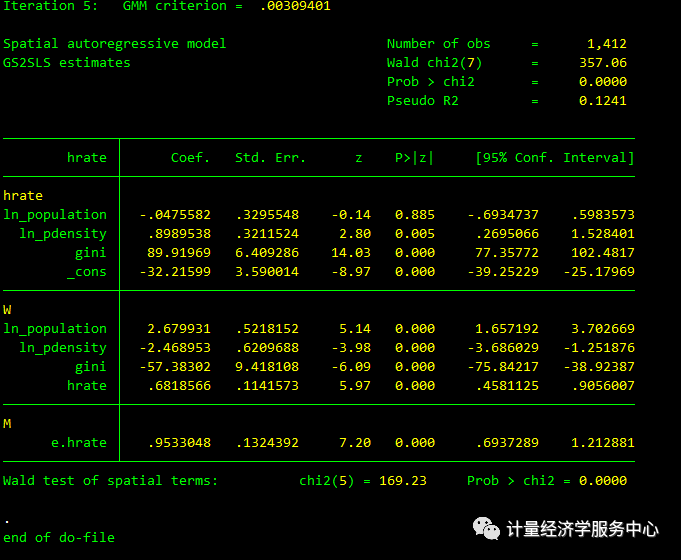
我们注意到,当模型中存在依赖变量滞后或独立变量滞后时,基于系数估计来解释协变量效应是困难的。
hrate高速率的空间滞后改变了协变量效应。一个县的基尼系数的变化会改变该县的条件均值,而这个变化会改变所有相邻县的条件均值。这些县的hrate的变化进而影响所有相邻县的hrate,依此类推,直到所有由相邻县链连接的县都受到影响。
由于hrate的空间滞后是如何改变协变量效应的,所以协变量的影响在不同的县是不同的。协变量的影响和空间单位一样多。正如LeSage和Pace(2009,第2.7节)所讨论的,我们将这些空间单元级效应的平均值定义为协变量效应。
在其他国家,基尼系数对hrate条件均值的影响称为间接或溢出效应。由于模型中包含了基尼系数的空间滞后,因此存在第二个间接影响。hrate方程中包含了邻县的基尼系数,所以一个县的基尼系数的变化会改变邻县hrate的条件均值。在同一县,基尼系数对hrate条件均值的影响称为直接或间接影响的效果。直接和间接影响的总和称为总影响。
我们使用estat影响来估计这些影响的大小。
代码为:
spregress hrate ln_population ln_pdensity gini, gs2sls dvarlag(W) errorlag(M) ivarlag(W: ln_population ln_pdensity gini)结果为:
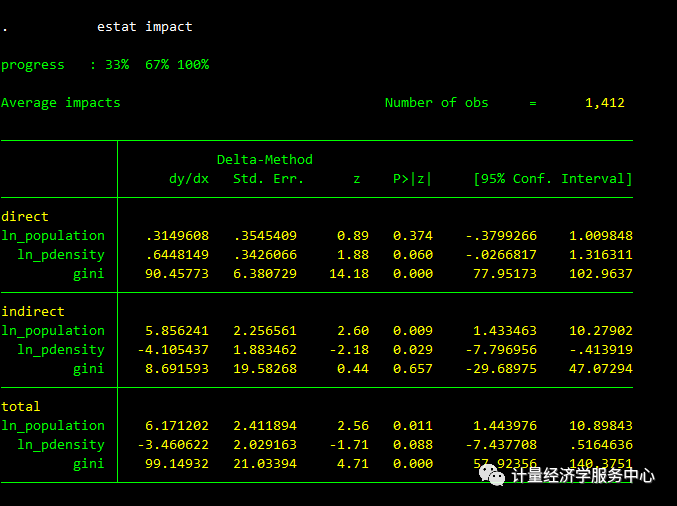
看到输出顶部的百分比了吗?对于大型数据集,计算效果的标准误差可能很耗时,因此estat impact在计算过程中报告其进度。
由于基尼系数是正的,所以基尼系数的直接影响是正的。由于相关变量滞后系数为正,且基尼系数为正,因此hrate的空间滞后对基尼系数的间接影响为正。由于基尼系数的空间滞后,其间接效应为负。estat的影响表明,基尼系数和的两个间接影响对净正间接影响,虽然总和与0无显著差异。
注意,W的归一化影响协变量的滞后系数估计值的大小。对于GS2SLS估计,W的归一化(行归一化除外)并不影响协变量效应的渐近估计。在有限样本中,这意味着W的归一化可能对estat影响产生的估计值产生很小的影响—与影响的标准误差相比很小。对于ML估计量,标准化并不影响estat impact显示的估计效果的大小。参见选择权重矩阵及其标准化。
在回归后运行estat impact对正确解释模型至关重要。estat impact影响的输出可以直接读取为所有空间单位(观测值)的协变量平均每增量变化的因变量度量的变化。
estat impact显示边际(增量变化)效应。我们可能想看看协变量中离散变化的总体影响。在这个例子中,因变量的期望在协变量中是线性的。我们没有拟合多项式或其他非线性项。我们可以把增量变化乘以协变量的离散变化。或者,我们可以使用margin命令,它既适用于线性项,也适用于非线性项。
4
spregress, gs2sls heteroskedastic
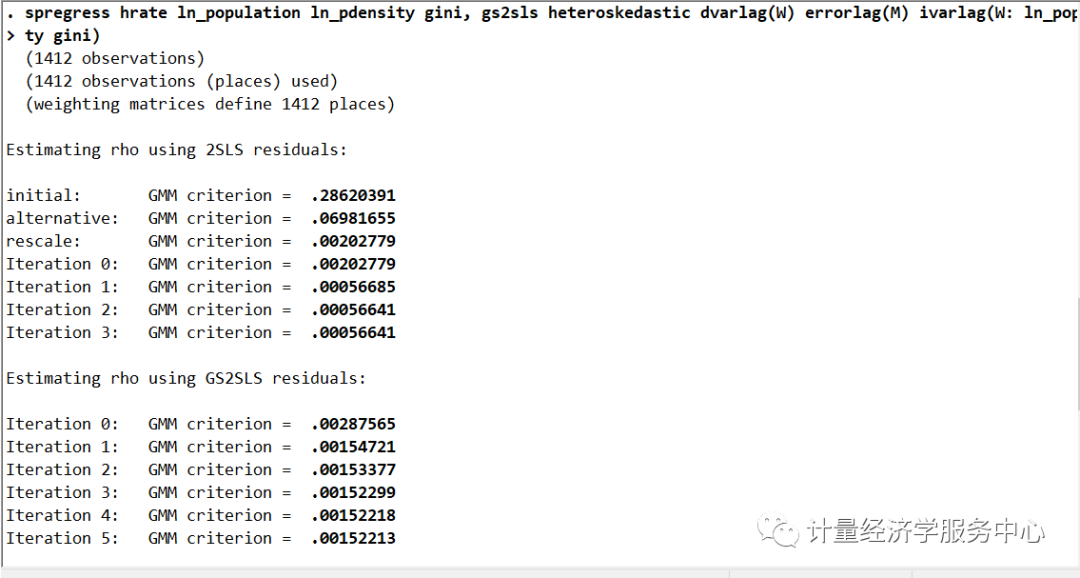
spregress, gs2sls命令有一个异方差选项,要求误差是独立的,但不一定是同分布的。实际上,这个选项会导致空间自回归误差相关系数和标准误差的估计值发生变化。在没有空间自回归误差的模型中,只有标准误差会改变。
如果我们将异方差选项添加到模型中,我们得到
代码为:
spregress hrate ln_population ln_pdensity gini, gs2sls heteroskedastic dvarlag(W) errorlag(M) ivarlag(W: ln_population ln_pdensity gini)结果为:
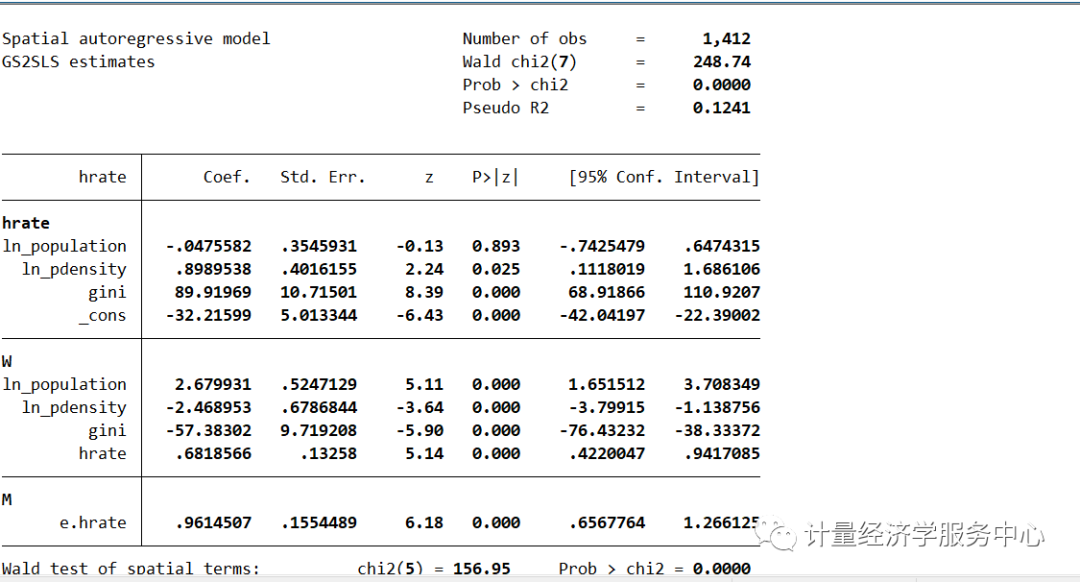
5
spregress, ml
SAR模型可以使用ML估计进行拟合。这是我们在例1中使用ml代替gs2sls估计的第二个模型。
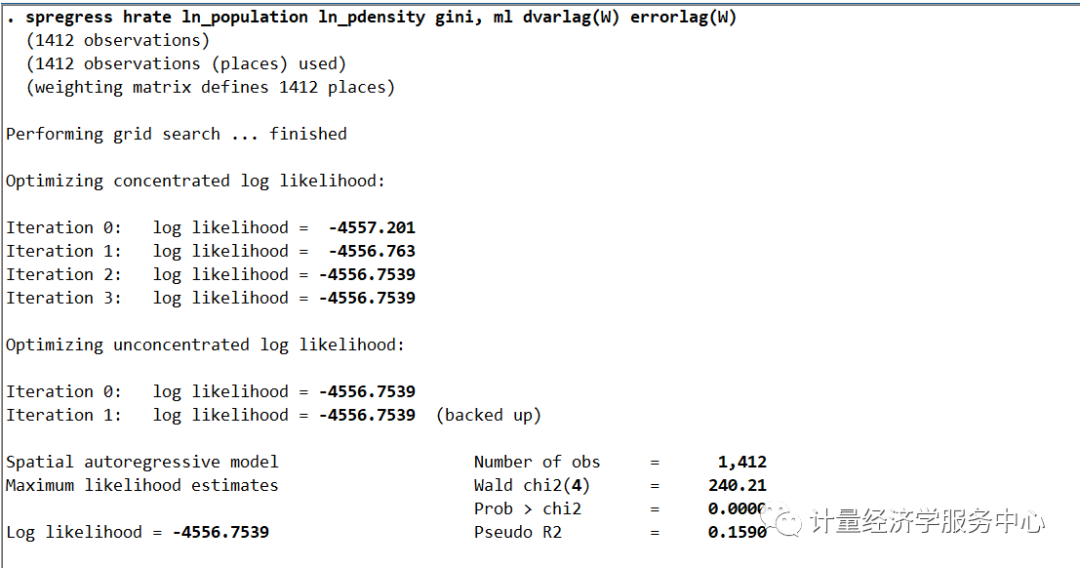
代码为:
spregress hrate ln_population ln_pdensity gini, ml dvarlag(W) errorlag(W)结果为:
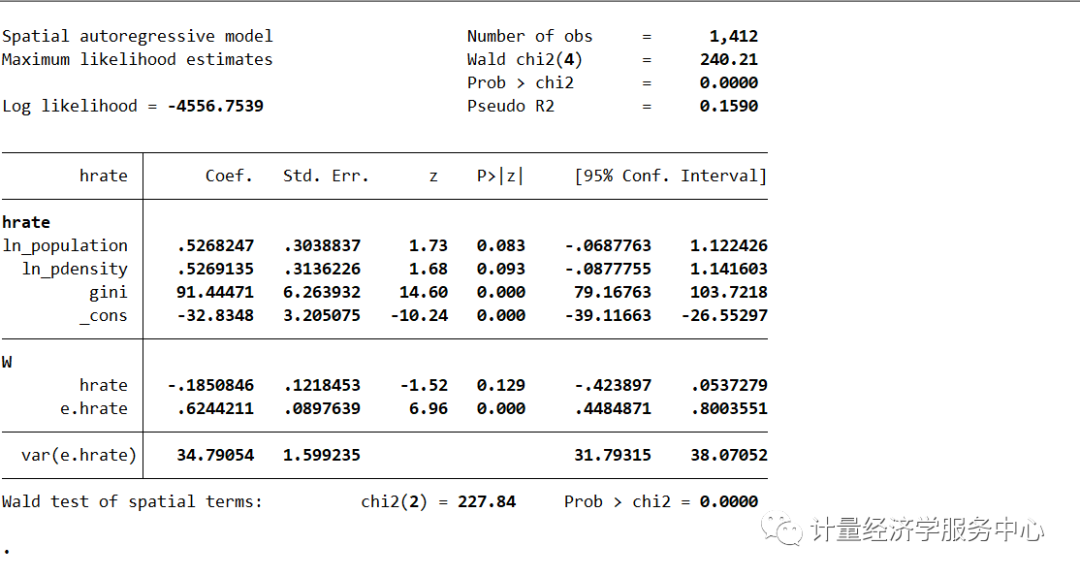
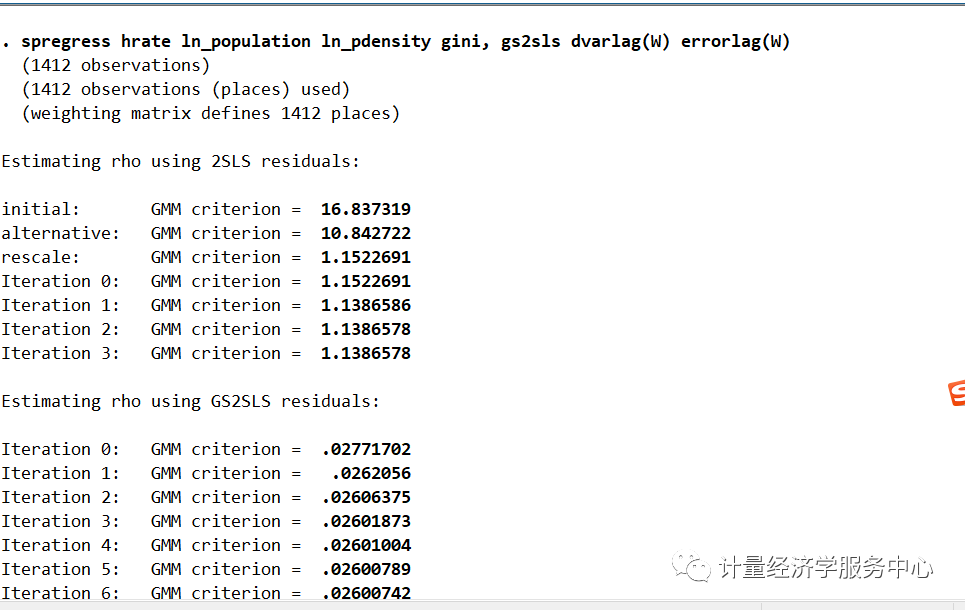
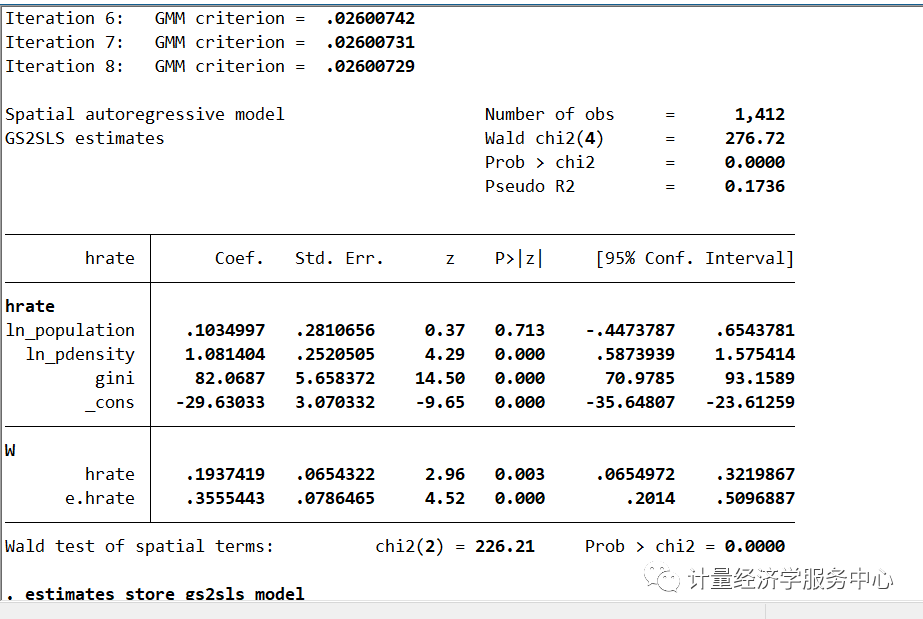
我们使用estimate store存储估计结果,就像使用与gs2sls相同的模型一样,现在我们使用estimate表来比较系数估计及其标准误差。
代码为:
estimates table gs2sls_model ml_model, b(%6.3f) se(%6.3f)结果为:
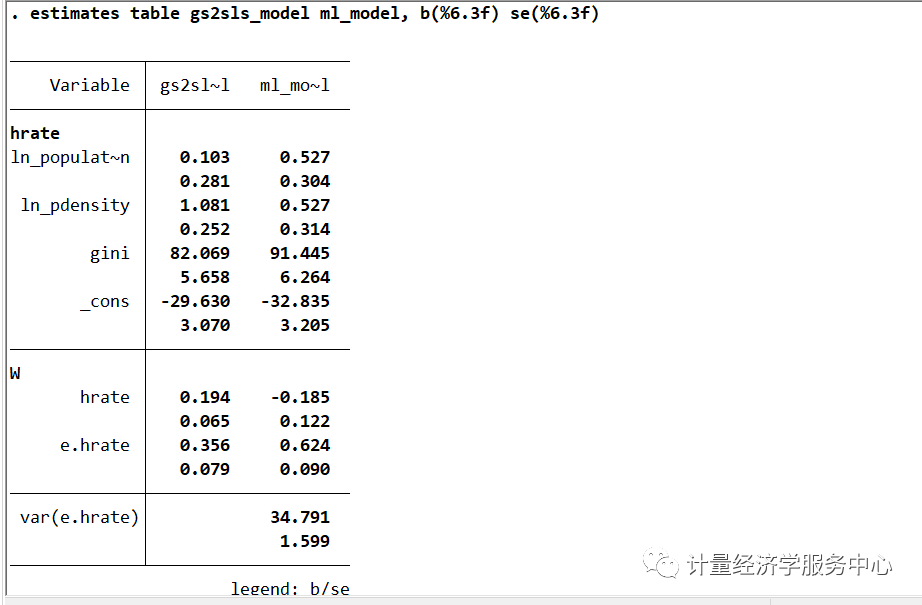
结果有明显的不同。ln pdensity系数在GS2SLS模型中显著,而在ML模型中不显著。然而,基尼系数估计是相似的,它们的标准误差也是相似的。hrate 滞后期的系数在ML模型中变成负的,SAR模型中误差相关性由0.36增加到0.62。我们注意到ML估计量在异方差性下是不一致的;为了一致性,误差分布需要被i.i.d。
◆◆◆◆
精彩回顾

点击上图查看:
《零基础|轻松搞定空间计量:空间计量及GeoDa、Stata应用》

点击上图查看:
空间计量第二部:空间计量及Matlab应用课程

点击上图查看:
空间计量第三部:空间计量及Matlab应用课程(SPATIAL AUTOREGRESSIVE MODELS USING STATA)








