您现在的位置是:主页 > news > 定制营销的成功案例/网站seo推广优化
定制营销的成功案例/网站seo推广优化
![]() admin2025/6/22 5:46:57【news】
admin2025/6/22 5:46:57【news】
简介定制营销的成功案例,网站seo推广优化,成都疫情源头终于找到了,建设产品信息网站文章目录0. 算法基础1. 判定问题与优化问题[^1]:1. 状态空间**斐波那契数列:****拨转开关问题:****埃及分数问题:****八数码问题:**数字三角形:一维递推问题: 爬楼梯(求和形式)一维递推问题: 最长上升子序列(最值形式)二维问题: 区间问题 - 最长回文子序列二维问题: 区间问题 -…
文章目录
- 0. 算法基础
- 1. 判定问题与优化问题[^1]:
- 1. 状态空间
- **斐波那契数列:**
- **拨转开关问题:**
- **埃及分数问题:**
- **八数码问题:**
- 数字三角形:
- 一维递推问题: 爬楼梯(求和形式)
- 一维递推问题: 最长上升子序列(最值形式)
- 二维问题: 区间问题 - 最长回文子序列
- 二维问题: 区间问题 - 回文子序列的个数
- 二维问题: 区间问题 - 最优链乘法
- 二维问题:区间问题 -- 区间最值查询
- 二维问题:区间问题 -- 序列间比较问题
- 树与图上的问题
- 2. 经典算法问题:
- 2.1 归并排序
- 2.2 逆序对个数
- 2.3 快速排序
- 2.4 第k大数
- 2.5 矩阵快速幂
- 2.6 Strassen矩阵乘法
- 2.7 主定理
- 3. 分治: 一维线性插值
- 3.1 一维数值积分:
- 自适应辛普森算法:
- 4. 贪心
- 4.1 二分查找
- 4.2 砍木头
- 5. 随机算法
- 5.0 两类算法之间的转化:
- 5.1 二项分布的期望计算(使用期望的线性性质):
- 5.2 快速排序的算法期望:
- 5.3 最小割(Min Cut): Karger
- 5.4 博弈树:
- 6. 作业习题
- 6.1 取快递:
- 输入
- 输出
- 6.2 确实是凉菜:
- **输入**
- **输出**
- 6.3 紧急封城:
- 输入
- 输出
- 6.4 等你下课
- **输入**
- **输出**
- 7. 模块题型:
- 7.1 n个盘子m个球:
- 7.1.1 球同, 盒不同, 不能空:
- 7.1.2 球同, 盒不同, 能空:
- 7.1.3 球不同, 盒同, 不能空:
- 7.1.4 球不同, 盒同, 可以空:
- 7.1.5 球不同, 盒不同, 不能为空:
- 7.1.6 球不同, 盒不同, 可以为空:
- 7.1.7 球同, 盒同, 可以为空:
- 7.1.8 球同, 盒同, 不可以为空:
- 7.1.9 全错位排列递推:
- 7.1.10 排列组合公式:
0. 算法基础
1. 判定问题与优化问题1:
Decision problem | Optimization problem
- 优化问题:
在计算机科学中, 优化问题是在可行解中找到最优解
| 优化问题分类 | 说明 |
|---|---|
| 连续优化问题 | 诸如连续函数的优化 |
| 组合优化问题 | 对于离散变量的优化 |
NP和NP-Hard问题2:
-
NP问题: NP →\rightarrow→ Non-deterministic, 在非确定性图灵机上可以被多项式时间内求解的决策问题. — 即多项式时间内可以验证解是否正确.
-
NP-Hard问题: 如果一个判定问题是NP问题, 且所有NP问题都可以约化(reduce)到它. 注意NP-Hard问题不一定是NP问题.(NP-Hard比NPC问题更广)
越想越头疼, 先跳过…
1. 状态空间
状态(state)
状态转移(state transition)
状态空间(state space)
状态变量(state variable)
价值函数(cost function)
斐波那契数列:
F1=F2=1Fn=Fn−1+Fn−2(n>2)F_1 = F_2 = 1 \\ F_n = F_{n-1}+F_{n-2}(n > 2) F1=F2=1Fn=Fn−1+Fn−2(n>2)
复杂度为O(n)O(n)O(n)
如果使用矩阵快速幂:
(FnFn−1)=(1110)(Fn−1Fn−2)=(1110)(n−1)(F1F0)\begin{pmatrix} F_n \\ F_{n-1} \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \\ \end{pmatrix} \begin{pmatrix} F_{n-1} \\ F_{n-2} \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \\ \end{pmatrix}^{(n-1)} \begin{pmatrix} F_1 \\ F_0 \end{pmatrix} (FnFn−1)=(1110)(Fn−1Fn−2)=(1110)(n−1)(F1F0)
矩阵(1110)\begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix}(1110) 的n-1次幂使用快速幂: T(n)=T(n2)+O(1)T(n)=T(\frac{n}{2})+O(1)T(n)=T(2n)+O(1), 因此T(n)=O(log2n)T(n)=O(log_2n)T(n)=O(log2n)
拨转开关问题:
有一个4$\times$4的灯阵, 每个灯上均有一个开关, 每次拨动开关会使当前灯和相邻灯的开关状态改变, 判断给出某个开关图案是否可以通过操作开关使全部灯都打开?
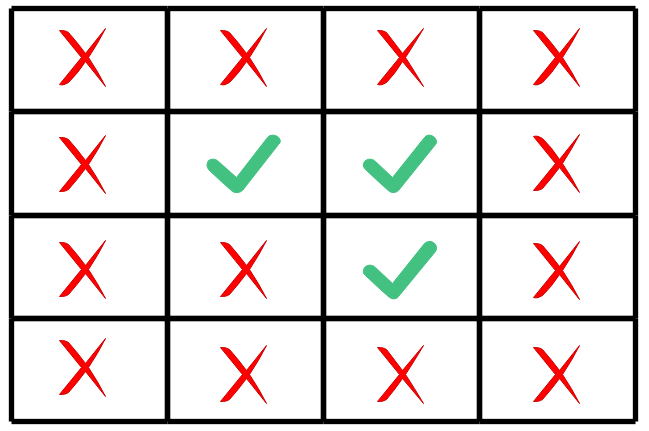
4$\times$4灯阵的每一种开关状态都对应一个状态, 如果用一个二维矩阵来存储一个状态, 空间开销是 216×162^{16}\times 16216×16, 对于一个4×44\times 44×4的灯阵来说似乎还可以接受, 但是空间复杂度是指数增长的.
- 状态压缩: 使用16个二进制位来表示
- 状态哈希: H:X→YH: X \rightarrow YH:X→Y
埃及分数问题:
古埃及数学的分数表示十分特殊, 不允许分子不为1的分数存在, 比如23\frac{2}{3}32在古埃及数学中只能表示为12+16\frac{1}{2} + \frac{1}{6}21+61, 请设计算法, 对给定的真分数$\frac{a}{b} $, 请计算出满足以下条件的埃及分数表示:
- 和式中分数互不相同
- 和式中分数个数最少
- 满足条件2的情况下, 保留和式中最小分数的最大情况下的解 .
例如: 1945=15+16+118\frac{19}{45}=\frac{1}{5} + \frac{1}{6} + \frac{1}{18}4519=51+61+181
定义状态: a′b′=ab−1x\frac{a'}{b'}=\frac{a}{b}-\frac{1}{x}b′a′=ba−x1
{广度优先?:x∈[1,+∞]深度优先?:x可以无穷大,可以永远递归下去!现在还是优化问题!→每一步都没有界,导致无法找到一个判定准则.\begin{cases} 广度优先?: x\in [1, +\infin] \\ 深度优先?: x可以无穷大, 可以永远递归下去! 现在还是优化问题!\rightarrow 每一步都没有界, 导致无法找到一个判定准则. \end{cases} {广度优先?:x∈[1,+∞]深度优先?:x可以无穷大,可以永远递归下去!现在还是优化问题!→每一步都没有界,导致无法找到一个判定准则.
- 迭代加深搜索(Iteratively Deepening DFS): 搜索深度也作为状态的一部分, 优化问题转化为判定问题.
- 必须要注意, 这个深度是迭代深度
洛谷-埃及分数
埃及分数思路
这里还待优化, 有三个TLE
#include<iostream>
#include<vector>
#include<utility>using namespace std;vector<int> print_vec;inline bool operator<(vector<int> a, vector<int> b) {if (a.size() != b.size()) {return a.size() > b.size();} else {return a[a.size() - 1] > b[b.size() - 1];}
}inline bool operator>(vector<int> a, vector<int> b) {return !(move(a) < move(b));
}inline pair<int, int> sub(int numerator, int denominator, int v) {numerator = numerator * v - denominator;denominator = denominator * v;return pair<int, int>(numerator, denominator);
}inline int gcd(int a, int b) {if (b == 0) return a;return gcd(b, a % b);
}inline void yuefen(int &numerator, int &denominator) {int GCD = gcd(numerator, denominator);numerator /= GCD;denominator /= GCD;
}inline int dfs(int numerator, int denominator, int last_denominator, int depth, int max_depth, vector<int> result) {if (numerator == 0) {return 1;} else if (depth > max_depth){return 0;}yuefen(numerator, denominator);int bingo = 0;for (int i = last_denominator + 1; i <= min(denominator / numerator * (max_depth - depth + 1), 10000000); i++) {if (numerator * i - denominator >= 0) {pair<int, int> res = sub(numerator, denominator, i);int _numerator = res.first;int _denominator = res.second;result.push_back(i);int finish = dfs(_numerator, _denominator, i, depth + 1, max_depth, result);if (finish) {bingo = finish;}if (depth == max_depth && finish) {if (print_vec.empty() || result > print_vec) {print_vec.swap(result);}break;}result.pop_back();}}return bingo;
}int main() {int numerator, denominator;cin >> numerator >> denominator;int MAX = 1;int last = 1;vector<int> result;while (!dfs(numerator, denominator, last, 1, MAX, result)) {MAX++;}
// for (int i = print_vec.size() - 1; i >= 0; i--) {
// cout << print_vec[i] << ' ';
// }for(auto item : print_vec) {cout<<item<<' ';}cout << endl;return 0;
}八数码问题:
九个格子中放入了数字1~8方块, 利用空位移动方块, 问使数字恢复顺序所需最少移动次数?
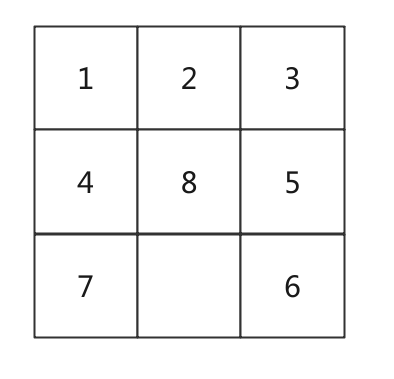
如果用一个二维数组来存储状态的转移, 则共有999^999种状态… 广度优先搜索内存必然不够
- 双向广度优先搜索(Bidirectional BFS, Meet-in-the-mid):
- 初始状态和结束状态都是已知的
- 可以从初始状态和结束状态同时进行广度优先搜索
- Meet-in-the-middle: https://www.geeksforgeeks.org/meet-in-the-middle/
数字三角形:
如图所示,请找出一条自顶向下路径,使得该路径上所有数字之和最大。
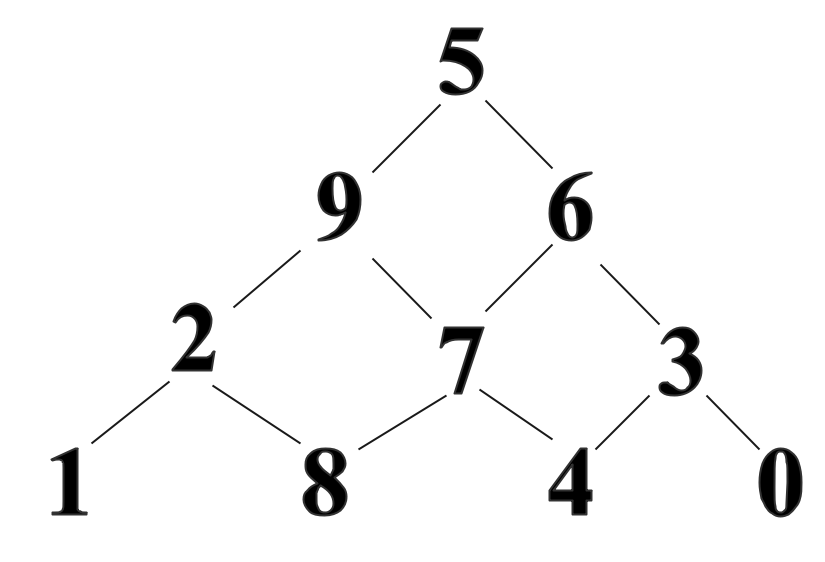
-
记忆化搜索:
- 状态变量:(i,j)(i,j)(i,j)表示路径自上而下走到了第iii行第jjj列
- 有些路径都会重复经过同一个节点
在搜索过程中, 对于已经搜索过、且价值函数的值不会再度更新(或者更优)的状态,可以使用记忆化搜索的方式,规避重复搜索。 -
动态规划算法适用问题的必要条件:
- 最优子结构: 最优解可以由子问题的最优解构造出来 – 分而治之
- 重叠子问题: 一些子问题在搜索过程中会重复遇到 – 具有优化空间
- 无后效性: 子问题最优解一旦确定就不会被更新
-
动态规划算法设计的三个关键环节:
- 定义状态和价值函数(建模)
- 确定初始状态和对应价值(边界)
- 确定状态转移中的价值更新方式(状态转移方程)
-
动态规划的两种实现:
- 记忆化搜索(Memorization): 自顶向下
- 打表法(Tabulation): 自底向上
https://www.luogu.com.cn/problem/P1216
#include<iostream>using namespace std;int main() {int n;cin >> n;int a[n][n];int dp[n][n];for (int i = 0; i < n; i++) {for (int j = 0; j < i + 1; j++) {cin >> a[i][j];}}for (int i = n - 1; i >= 0; i--) {for (int j = 0; j < i + 1; j++) {if (i == n - 1) {dp[i][j] = a[i][j];} else {dp[i][j] = max(dp[i+1][j], dp[i+1][j+1]) + a[i][j];}}}cout<<dp[0][0]<<endl;return 0;
}
一维递推问题: 爬楼梯(求和形式)
一个有n级台阶的楼梯,每步可以迈1、2、3级,问爬完这段楼梯有几种不同的方式?
F(n)=∑i=13F(n−i)F(n)=\sum_{i=1}^3 F(n-i) F(n)=i=1∑3F(n−i)
https://www.luogu.com.cn/problem/P1255
#include<iostream>using namespace std;int main() {int n;cin>>n;unsigned long long dp[n+1];for (int i = 0; i <= n; i++) {if (i == 0 || i == 1) {dp[i] = 1ll;} else {dp[i] = dp[i-1] + dp[i-2];}}cout<<dp[n]<<endl;return 0;
}
一维递推问题: 最长上升子序列(最值形式)
给一个数组,请找出这个数组中的一个最长的单调递增子序列(可以不连续)
F(i)=max1≤j<i{I(aj<ai)F(j)}+1边界:F(0)=0答案:F(n)=max1≤j<i{F(i)},答案可以在构建时不断维护更新!F(i)表示以a[i]为子序列结束字符的最长上升子序列长度,这一点非常重要F(i)=\underset{1\le j\lt i}{max} \{\mathbb{I}(a_j < a_i)F(j)\} + 1 \\ 边界:F(0)= 0 \\ 答案: F(n)=\underset{1\le j \lt i}{max}\{F(i) \}, 答案可以在构建时不断维护更新! \\ F(i)表示以a[i]为子序列结束字符的最长上升子序列长度, 这一点非常重要 F(i)=1≤j<imax{I(aj<ai)F(j)}+1边界:F(0)=0答案:F(n)=1≤j<imax{F(i)},答案可以在构建时不断维护更新!F(i)表示以a[i]为子序列结束字符的最长上升子序列长度,这一点非常重要
https://leetcode-cn.com/problems/longest-increasing-subsequence/
class Solution {
public:int lengthOfLIS(vector<int>& nums) {int len = nums.size();int dp[len];int res = 0;dp[0] = 1;for (int i = 0; i < len; i++) {int tmp = 0;for (int j = 0; j < i; j++) {tmp = max(tmp, (nums[i] > nums[j] ? dp[j] : 0));}dp[i] = tmp + 1;res = max(res, dp[i]);}return res;}
};
二维问题: 区间问题 - 最长回文子序列
f(i,j)→区间[i,j]内的最长回文子序列长度f(i,j)=max{f(i+1,j),f(i,j−1),f(i+1,j−1)+2I(ai=aj)}答案:f(1,n)边界:f(i,i)=1f(i,j)\rightarrow 区间[i,j]内的最长回文子序列长度 \\ f(i,j) = max\{ f(i+1, j), f(i,j-1), f(i+1, j-1) + 2\mathbb{I}(a_i=a_j) \} \\ 答案: f(1, n) \\ 边界: f(i, i) = 1 \\ f(i,j)→区间[i,j]内的最长回文子序列长度f(i,j)=max{f(i+1,j),f(i,j−1),f(i+1,j−1)+2I(ai=aj)}答案:f(1,n)边界:f(i,i)=1
https://leetcode-cn.com/problems/longest-palindromic-subsequence/
class Solution {
public:int longestPalindromeSubseq(string s) {int len = s.size();int dp[len][len];for(int w = 0; w < len; w++) {for(int i = 0; i + w < len; i++) {if (w == 0) {dp[i][i+w] = 1;} else if(w == 1){dp[i][i+w] = max(dp[i+1][i+w], dp[i][i+w-1]) + (s[i] == s[i+w] ? 1 : 0);} else {dp[i][i+w] = max(dp[i+1][i+w], dp[i][i+w-1]);dp[i][i+w] = max(dp[i][i+w], dp[i+1][i+w-1] + (s[i] == s[i+w] ? 2 : 0));}}}return dp[0][len-1];}
};
二维问题: 区间问题 - 回文子序列的个数
求字符串中回文子序列的个数,位置不同的相同序列需要重复计数.
{如果ai≠aj,那么f(i,j)就该等于f(i+1,j)+f(i,j−1)−f(i+1,j−1),第三项重复减了!!!如果ai=aj,那么f(i,j)就该等于f(i+1,j)+f(i,j−1)+1\begin{cases} 如果a_i \ne a_j, 那么f(i,j)就该等于f(i+1, j) + f(i, j-1) - f(i+1, j-1), 第三项重复减了!!! \\ 如果a_i = a_j, 那么f(i,j)就该等于f(i+1, j) + f(i,j-1) + 1 \end{cases} {如果ai=aj,那么f(i,j)就该等于f(i+1,j)+f(i,j−1)−f(i+1,j−1),第三项重复减了!!!如果ai=aj,那么f(i,j)就该等于f(i+1,j)+f(i,j−1)+1
注意, 第二种情况中的 +1+1+1其实包含了: f(i+1,j−1)+1f(i+1,j-1) + 1f(i+1,j−1)+1, 因为f(i+1,j)+f(i,j−1)f(i+1, j) + f(i, j-1)f(i+1,j)+f(i,j−1)包含了两个f(i+1,j−1)f(i+1, j-1)f(i+1,j−1). f(i+1,j−1)+1f(i+1,j-1)+1f(i+1,j−1)+1的意义在于, 当ai=aja_i = a_jai=aj时, f(i+1,j−1)f(i+1,j-1)f(i+1,j−1)有多少个元素, 以aia_iai和aja_jaj为边界的回文子序列就有多少个(再包括aiaja_ia_jaiaj本身的一个)
综合如上可以得到:f(i,j)=f(i+1,j)+f(i,j−1)−I(ai≠aj)f(i+1,j−1)+I(ai=aj)综合如上可以得到: f(i,j)=f(i+1, j) + f(i,j-1) - \mathbb{I}(a_i\ne a_j)f(i+1, j-1) + \mathbb{I}(a_i=a_j) 综合如上可以得到:f(i,j)=f(i+1,j)+f(i,j−1)−I(ai=aj)f(i+1,j−1)+I(ai=aj)
二维问题: 区间问题 - 最优链乘法
nnn个矩阵连续相乘,第iii个矩阵的维度为ri×cir_i\times c_iri×ci,问如何通过加括号的方式最快完成矩阵乘法。
总是可以将矩阵链乘转化为两个矩阵结果的乘积, 因此基本思想是分治思想, 但是由于有重叠子问题, 因此为动态规划f(i,j)表示第i个到第j个矩阵区间链乘最优结果→f(i,j)=maxk∈[i,j]{f(i,k)+f(k+1,j)+}\text{总是可以将矩阵链乘转化为两个矩阵结果的乘积, 因此基本思想是分治思想, 但是由于有重叠子问题, 因此为动态规划} \\ f(i, j) 表示第i个到第j个矩阵区间链乘最优结果 \\ \rightarrow f(i,j)=\underset{k\in [i,j]}{max}\{ f(i,k) + f(k+1, j) + \} 总是可以将矩阵链乘转化为两个矩阵结果的乘积, 因此基本思想是分治思想, 但是由于有重叠子问题, 因此为动态规划f(i,j)表示第i个到第j个矩阵区间链乘最优结果→f(i,j)=k∈[i,j]max{f(i,k)+f(k+1,j)+}
http://poj.org/problem?id=1651
#include<iostream>using namespace std;int main() {int n;cin>>n;int a[n];for (int i = 0; i < n; i++) {cin>>a[i];}long long dp[n][n];// O(n^2)for(int wnd = 0; wnd < n-1; wnd++) {for(int i = 0; i < n-1; i++) {if (wnd == 0){dp[i][i+wnd] = 0;}else{dp[i][i+wnd] = dp[i][i+wnd-1] + a[i] * a[i+wnd] * a[i+wnd+1];}}}// O(n^3)for(int i = 0; i < n-1; i++) {for (int j = i; j < n - 1; j++) {for (int k = i; k < j; k++) {int tail = a[i] * a[k+1] * a[j + 1];dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j] + tail);}}}cout<<dp[0][n-2]<<endl;return 0;
}
二维问题:区间问题 – 区间最值查询
区间最值查询(Range Minimum/Maximum Query, RMQ): 给出长度为nnn的数组和mmm次询问,每次询问要求l,rl,rl,r区间内最值.
- 倍增思想: f(i,j):以i为起点,长度为2j的区间的最值f(i,j): 以i为起点, 长度为2^j的区间的最值f(i,j):以i为起点,长度为2j的区间的最值
为什么要倍增?如果不倍增,状态转移是这样的:f(i,j)表示区间[i,j)内的最值f(i,j)=M{f(i,mid),f(mid,j)},T(n)=∑i=1n∑j=1iT(j)=O(n2)\text{为什么要倍增?} \\ 如果不倍增, 状态转移是这样的:f(i,j)表示区间[i, j)内的最值 \\ f(i,j) = \mathbb{M}\{f(i, mid), f(mid,j)\}, T(n) = \sum_{i=1}^{n}\sum_{j=1}^{i}T(j)=O(n^2) 为什么要倍增?如果不倍增,状态转移是这样的:f(i,j)表示区间[i,j)内的最值f(i,j)=M{f(i,mid),f(mid,j)},T(n)=i=1∑nj=1∑iT(j)=O(n2)
如果使用倍增:f(i,j)=M{f(i,j−1),f(i+2j−1,j−1)}T(n)=∑i=1n∑j=1logiT(j)+mO(1)=O(nlogn+m)如果使用倍增: \\ f(i,j) = \mathbb{M}\{f(i,j-1), f(i + 2^{j-1},j-1) \} \\ T(n) = \sum_{i=1}^{n}\sum_{j=1}^{logi}T(j) + mO(1)=O(nlogn+m) 如果使用倍增:f(i,j)=M{f(i,j−1),f(i+2j−1,j−1)}T(n)=i=1∑nj=1∑logiT(j)+mO(1)=O(nlogn+m)
二维问题:区间问题 – 序列间比较问题
编辑距离(edit distance): 给出字符串AAA和BBB, 对AAA进行三种操作: 插入、删除或替换一个字符。问由A修改为B至少要几步。
| Q | A |
|---|---|
| 为什么是二维? | 需要两个状态变量, 一个变量记录一个字符串当前跟踪的位置 |
| 第一维状态变量含义 | 表示对照字符串的当前跟踪状态 |
| 第二维状态变量含义 | 表示待修改字符串的当前跟踪状态 |
f(i,j)=min{f(i,j−1)+1,删除一个f(i−1,j−1)+1,替换一个f(i−1,j)+1,增加一个与ai相同的字符等价于删除aif(i−1,j−1),ai与bi相匹配,状态前移(可以看到第四种情况可以与第二种情况用指示器合并)f(i,j)=min\begin{cases} f(i, j-1) + 1,删除一个 \\ f(i-1,j-1) + 1, 替换一个 \\ f(i-1, j) + 1, 增加一个与a_i相同的字符等价于删除a_i \\ f(i-1, j-1), a_i与b_i相匹配, 状态前移 (可以看到第四种情况可以与第二种情况用指示器合并) \end{cases} f(i,j)=min⎩⎪⎪⎪⎨⎪⎪⎪⎧f(i,j−1)+1,删除一个f(i−1,j−1)+1,替换一个f(i−1,j)+1,增加一个与ai相同的字符等价于删除aif(i−1,j−1),ai与bi相匹配,状态前移(可以看到第四种情况可以与第二种情况用指示器合并)
{边界条件:f(i,0)=i,f(0,j)=j结果:f(LB,LA)时间复杂度:O(n2)−建表嘛,表多大复杂度多大\begin{cases} 边界条件: f(i, 0) =i, f(0, j) = j \\ 结果: f(L_B, L_A) \\ 时间复杂度: O(n^2) - 建表嘛, 表多大复杂度多大 \end{cases} ⎩⎪⎨⎪⎧边界条件:f(i,0)=i,f(0,j)=j结果:f(LB,LA)时间复杂度:O(n2)−建表嘛,表多大复杂度多大
https://www.luogu.com.cn/problem/P2758
#include<iostream>
#include<string>
using namespace std;int main() {string a, b;cin>>a>>b;int len_a = a.size(), len_b = b.size();int dp[len_a+1][len_b+1];for (int i = 0; i <= len_a; i++) {for (int j = 0; j <= len_b; j++) {if (i == 0 ) {dp[i][j] = j;} else if (j == 0) {dp[i][j] = i;} else {int x = dp[i-1][j] + 1;int y = dp[i][j-1] + 1;int z = dp[i-1][j-1] + (a[i-1] == b[j-1] ? 0 : 1);dp[i][j] = min(min(x, y), z);}}}cout<<dp[len_a][len_b]<<endl;return 0;
}
树与图上的问题
快乐聚会: 某公司中有明确的上下属关系,可用有根树表示。现举办聚会,每个人都有一个快乐指数aia_iai, 但如果一个人的上属参加了聚会,那么此人就不会再参会。求聚会最大快乐指数和?
f(x,0)=∑y∈Child(x)max{f(y,0),f(y,1)}f(x,1)=∑y∈Child(x)f(y,0)+axf(x, 0) = \sum_{y\in Child(x)} max\{ f(y,0),f(y,1) \} \\ f(x,1) = \sum_{y\in Child(x)} f(y,0) + a_x f(x,0)=y∈Child(x)∑max{f(y,0),f(y,1)}f(x,1)=y∈Child(x)∑f(y,0)+ax
{边界条件:f(leaf,0)=0,f(leaf,1)=aleaf答案为:max{f(root,0),f(root,1)}时间复杂度为:O(n)\begin{cases} 边界条件: f(leaf, 0) = 0, f(leaf, 1) = a_{leaf} \\ 答案为: \text{max}\{ f(root, 0), f(root,1)\} \\ 时间复杂度为:O(n) \end{cases} ⎩⎪⎨⎪⎧边界条件:f(leaf,0)=0,f(leaf,1)=aleaf答案为:max{f(root,0),f(root,1)}时间复杂度为:O(n)
https://www.luogu.com.cn/problem/P1352
注意, 传比较大对象譬如向量, 最好用常引用, 否则会爆内存.
#include <iostream>
#include<vector>
#include<map>
#include<utility>
using namespace std;
map<pair<int, int>, int> mem;vector<int> get_child(const vector<vector<char> > &a, int n, int parent) {vector<int> result;for (int i = 0; i < n; i++) {if(a[parent][i] == 1) {result.push_back(i);}}return result;
}int dp(int* happy, const vector<vector<char> > &a, int n, int root, int go) {pair<int, int> key = pair<int, int>(root, go);if (mem[key] != 0) {return mem[key];}vector<int> children = get_child(a, n, root);int res = 0;for (auto ch : children) {if (go == 1) {res += dp(happy, a, n, ch, 0);} else {int tmp = max(dp(happy, a, n, ch, 1), dp(happy, a, n, ch, 0));res += tmp;}}if (go == 1) {res += happy[root];}mem[key] = res;return res;
}int main() {int n;cin>>n;int happy[n];vector<vector<char> > r(n);for(int i = 0; i < n; i++) {r[i].resize(n, 0);cin>>happy[i];}for(int i = 0; i < n - 1; i++) {int a, b;cin>>a>>b;r[b-1][a-1] = 1;}// get the root nodeint root = -1;for (int i = 0; i < n; i++) {int no_parent = 1;for(int j = 0; j < n; j++) {if(r[j][i] == 1) {no_parent = 0;break;}}if (no_parent == 1) {root = i;break;}}// DPcout<<max(dp(happy, r, n, root, 1), dp(happy, r, n, root, 0))<<endl;return 0;
}2. 经典算法问题:
2.1 归并排序
用两个子状态的解构造(按序拼接)当前状态的解
分治算法, 时间复杂度O(nlogn)O(nlogn)O(nlogn)
相关知识: 原地归并排序(in-place)
2.2 逆序对个数
用两个子状态的解构造(统计个数)当前状态的解
分治算法, 时间复杂度O(nlogn)O(nlogn)O(nlogn)
使用归并排序的中间过程统计逆序对个数, 每次合并时, 统计两个子串之间逆序个数(子串内部的逆序数在合并子串时已经统计完毕)
2.3 快速排序
需要用两个子状态的解构造(按序拼接)当前状态的解
分治算法, 期望时间复杂度O(nlogn)
洛谷上的quick sort : 有一个超时
#include<iostream>
#include<vector>using namespace std;int partition(vector<int> &a, int l, int r) {int mid = (l + r) / 2;swap(a[l], a[mid]);int pivot = a[l];int p1 = l, p2 = r-1;while (p1 < p2) {while(a[p2] >= pivot && p1 < p2) {p2--;}a[p1] = a[p2];while(a[p1] <= pivot && p1 < p2) {p1++;}a[p2] = a[p1];}a[p1] = pivot;return p1;
}void quick_sort(vector<int> &a, int l, int r) {if (r - l <= 1) {return;} else if (r - l < 5) {for (int i = l; i < r; i++) {for (int j = i+1; j < r; j++) {if (a[j] < a[i]) {swap(a[i], a[j]);}}}return;}int mid = partition(a, l, r);quick_sort(a, l, mid);quick_sort(a, mid+1, r); // 注意这里要mid+1, 否则运行时间会长很多
}int main() {int n;cin>>n;vector<int> a(n);for (int i = 0; i < n; i++) {cin>>a[i];}quick_sort(a, 0, n);for(auto i : a) {cout<<i<<' ';}cout<<endl;return 0;
}
2.4 第k大数
仅需某一个子状态的解即可
贪心算法, 期望时间复杂度O(n)
使用快速排序的中间步骤求第K大的数: pivot左边有多少个, 右边有多少个, 可以通过减半确定第K大数的区间
T(n)=T(n2)+O(n)O(n)是用来划分Pivot的,用注定里可以知道T(n)=O(n)T(n) = T(\frac{n}{2}) + O(n) \\ O(n)是用来划分Pivot的, 用注定里可以知道T(n)=O(n) T(n)=T(2n)+O(n)O(n)是用来划分Pivot的,用注定里可以知道T(n)=O(n)
2.5 矩阵快速幂
两个子状态的解相同
贪心算法, 时间复杂度O(logn)
2.6 Strassen矩阵乘法
- 普通矩阵乘法: O(n3)O(n^3)O(n3)
- Strassen矩阵乘法: O(n2.81)O(n^{2.81})O(n2.81)
- 10次加法 + 7次乘法 + 8次加法
T(n)=7T(n2)+O(n2)=O(nlog27)=O(n2.81)T(n) = 7T(\frac{n}{2}) + O(n^2) = O(n^{log_27})=O(n^{2.81}) T(n)=7T(2n)+O(n2)=O(nlog27)=O(n2.81)
- 核心(考点): 用加法来替换乘法(原先8次乘法, 四次加法)
2.7 主定理
分治算法的时间复杂度: T(n)=aT(nb)+O(nd)T(n)=aT(\frac{n}{b})+O(n^d)T(n)=aT(bn)+O(nd)
- 如果d>logbad>log_bad>logba, T(n)=O(nd)T(n)=O(n^d)T(n)=O(nd)
- 如果d=logbad = log_bad=logba, T(n)=O(ndlogn)T(n) = O(n^dlogn)T(n)=O(ndlogn)
- 如果d<logbad<log_bad<logba, T(n)=O(nlogba)T(n) = O(n^{log_ba})T(n)=O(nlogba)
3. 分治: 一维线性插值
拉格朗日插值法:n个不同的点(xi,yi),可确定n−1阶多项式函数的全部系数:A(x)=∑i=0n−1f(xi)∏j≠ix−xjxi−xj拉格朗日插值法:n个不同的点(x_i,y_i),可确定n-1阶多项式函数的全部系数: \\ A(x) = \sum_{i=0}^{n-1} f(x_i)\prod_{j\ne i} \frac{x - x_j}{x_i-x_j} 拉格朗日插值法:n个不同的点(xi,yi),可确定n−1阶多项式函数的全部系数:A(x)=i=0∑n−1f(xi)j=i∏xi−xjx−xj
3.1 一维数值积分:
给出一维函数f(x)f(x)f(x), 计算∫abf(x)dx\int_a^bf(x)dx∫abf(x)dx
- 梯形近似法: 将区间等分n份, 求n个梯形的面积和
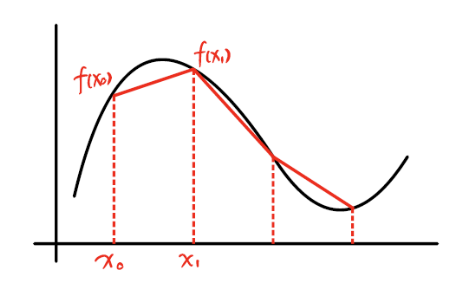
对于区间(x0,x1)(x_0,x_1)(x0,x1), 其面积近似等价于线性函数P(x)P(x)P(x)的积分 ∫x0x1P(x)dx\int_{x_0}^{x_1}P(x)dx∫x0x1P(x)dx
- 使用两个点(一次插值)得到的函数:
P(x)=f(x0)x−x1x0−x1+f(x1)x−x0x1−x0∫x0x1P(x)dx=x1−x02(f(x0)+f(x1))P(x)=f(x_0)\frac{x - x_1}{x_0 - x_1} + f(x_1) \frac{x-x_0}{x_1-x_0} \\ \int_{x_0}^{x_1} P(x)dx = \frac{x_1 - x_0}{2}(f(x_0)+f(x_1)) P(x)=f(x0)x0−x1x−x1+f(x1)x1−x0x−x0∫x0x1P(x)dx=2x1−x0(f(x0)+f(x1))
- 使用三个点(二次差值)得到的函数: x0=a,x1=a+b2,x2=bx_0=a, x_1=\frac{a+b}{2}, x_2=bx0=a,x1=2a+b,x2=b
P(x)=f(x0)x−x1x0−x1x−x2x0−x2+f(x1)x−x0x1−x0x−x2x1−x2+f(x2)x−x0x2−x0x−x1x2−x1辛普森积分法:∫x0x1P(x)dx=b−a6(f(a)+4f(a+b2)+f(b))P(x) = f(x_0)\frac{x-x_1}{x_0-x_1}\frac{x-x_2}{x_0-x_2} + f(x_1)\frac{x-x_0}{x_1-x_0}\frac{x-x_2}{x_1-x_2}+f(x_2)\frac{x-x_0}{x_2-x_0}\frac{x-x_1}{x_2-x_1} \\ \color{red}{\mathbf{辛普森积分法:}} \color{black} \int_{x_0}^{x_1}P(x)dx = \frac{b-a}{6}(f(a)+4f(\frac{a+b}{2})+f(b)) P(x)=f(x0)x0−x1x−x1x0−x2x−x2+f(x1)x1−x0x−x0x1−x2x−x2+f(x2)x2−x0x−x0x2−x1x−x1辛普森积分法:∫x0x1P(x)dx=6b−a(f(a)+4f(2a+b)+f(b))
- 划分区间时, 该如何确定区间长度? 太长了不够精确, 区间太小复杂度太高.

在曲线比较平滑的地方, 完全可以把区间分大一点, 曲线比较陡峭的地方区间划分的小一些, 由此得到了自适应辛普森算法: 根据曲线陡峭程度划分区间, 从而使得每段区间近似结果的误差小于ϵ\epsilonϵ
自适应辛普森算法:
S(⋅)为辛普森函数S(\cdot)为辛普森函数S(⋅)为辛普森函数
AdaSimp(a,b,S(a,b,f)):AdaSimp(a, b, S(a, b, f)): AdaSimp(a,b,S(a,b,f)):
4. 贪心
4.1 二分查找
c++:
- lower_bound 返回第一个大于等于目标值的位置
- upper_bound 返回第一个大于目标值的位置
4.2 砍木头
将n根长度不同木头砍成至少mmm段,要求砍完之后每段木头长度相等,问砍完后每段木头最长有多长?
-
优化转为判定问题: 最长多长? 转而去判定长度为LiL_iLi时是否满足m段, 随后找到最大的LiL_iLi
-
从LLL为1枚举到木头的最短长度(标记为LmaxL_{max}Lmax, 意为最大可切的长度)
-
复杂度O(nlogLmax)O(nlogL_{max})O(nlogLmax), 每次找到一个长度, 都要遍历木头判断是否可行
-
如果某次找到的可以满足需求, 那么我们可以再切长一点试试, 如果不能满足, 那么只能少切一点.
-
三分搜索(爬山法)
-
割线法: 一阶导数
-
牛顿法: 二阶导数
-
黄金分割法: 无需求导
5. 随机算法
两类随机算法
- 拉斯维加斯算法
- 梦特卡洛算法
5.0 两类算法之间的转化:
-
拉斯维加斯算法→\rightarrow→蒙特卡洛算法:
- 只要让一个拉斯维加斯在指定时间停止
- 蒙特卡洛算法的错误率上界由马尔可夫不等式得到:
P(X>t)≤E(X)tP(X>t) \le \frac{\mathbb{E}(X)}{t} P(X>t)≤tE(X)
-
蒙特卡洛算法→\rightarrow→拉斯维加斯算法:
- 当存在一个快速验证解的方法时可转化(NP问题)
- 重复执行蒙特卡洛算法直到找到正确解.
5.1 二项分布的期望计算(使用期望的线性性质):
如果有一个随机变量X=ω1Y1+ω2Y2+⋯+ωnYn,那么E(X)=ω1E(Y1)+ω2E(Y2)+⋯+ωnE(Yn).因为E(Yi)=p,∴E(X)=np如果有一个随机变量X=\omega_1Y_1+\omega_2 Y_2 + \cdots + \omega_n Y_n ,那么\mathbb{E}(X)=\omega_1\mathbb{E}(Y_1)+\omega_2\mathbb{E}(Y_2)+\cdots+\omega_n \mathbb{E}(Y_n). \\ 因为\mathbb{E}(Y_i) = p, \therefore \mathbb{E}(X) = np 如果有一个随机变量X=ω1Y1+ω2Y2+⋯+ωnYn,那么E(X)=ω1E(Y1)+ω2E(Y2)+⋯+ωnE(Yn).因为E(Yi)=p,∴E(X)=np
5.2 快速排序的算法期望:
T(A)表示算法交换次数T(A)=∑i=1n−1∑j=i+1nXij,Xij表示第i大的数和第j大的数之间是否比较过.上面这个式子将快速排序看作最简单的选择排序来看,但是用指示器Xij来表示快排中是否逻辑上两者之间有比较.事实上,快排中至要与pivot相比较就行.T(\mathcal{A})表示算法交换次数 \\ T(\mathcal{A}) = \sum_{i=1}^{n-1}\sum_{j=i+1}^n X_{ij}, X_{ij}表示第i大的数和第j大的数之间是否比较过. \\ 上面这个式子将快速排序看作最简单的选择排序来看, 但是用指示器X_{ij}来表示快排中是否逻辑上两者之间有比较. \\ 事实上, 快排中至要与pivot相比较就行. T(A)表示算法交换次数T(A)=i=1∑n−1j=i+1∑nXij,Xij表示第i大的数和第j大的数之间是否比较过.上面这个式子将快速排序看作最简单的选择排序来看,但是用指示器Xij来表示快排中是否逻辑上两者之间有比较.事实上,快排中至要与pivot相比较就行.
∴E(T(A))=E(∑i=1n−1∑j=i+1nXij)=∑i=1n−1∑j=i+1nE(Xij)\therefore \mathbb{E}(T(\mathcal{A})) = \mathbb{E}(\sum_{i=1}^{n-1}\sum_{j=i+1}^n X_{ij}) =\sum_{i=1}^{n-1}\sum_{j=i+1}^n \mathbb{E}(X_{ij}) ∴E(T(A))=E(i=1∑n−1j=i+1∑nXij)=i=1∑n−1j=i+1∑nE(Xij)
Si和Sj发生交换的条件是,在快速排序过程中:[i是j的祖先]或者[j是i的祖先].对于序列:Si,Si+1,⋯,Sj,P(Xij=1)=2j−i+1只要i或者j第一个被选为父节点,则必然有交换.而每个元素等可能被选中.S_i和S_j发生交换的条件是, 在快速排序过程中: [i是j的祖先]或者[j是i的祖先]. 对于序列:S_i, S_{i+1},\cdots,S_{j},P(X_{ij}=1) = \frac{2}{j-i+1} \\ 只要i或者j第一个被选为父节点, 则必然有交换. 而每个元素等可能被选中. Si和Sj发生交换的条件是,在快速排序过程中:[i是j的祖先]或者[j是i的祖先].对于序列:Si,Si+1,⋯,Sj,P(Xij=1)=j−i+12只要i或者j第一个被选为父节点,则必然有交换.而每个元素等可能被选中.
∴E(T(A))=∑i=1n−1∑j=i+1n2j−i+1=∑i=1n−1∑k=1n−12k+1<(n−1)∑k=1n−12k=(n−1)O(lnn)=O(nlnn)\therefore \mathbb{E}(T(\mathcal{A}))=\sum_{i=1}^{n-1}\sum_{j=i+1}^n \frac{2}{j-i+1}=\sum_{i=1}^{n-1}\sum_{k=1}^{n-1}\frac{2}{k+1} < (n-1)\sum_{k=1}^{n-1}\frac{2}{k}=(n-1)O(\mathbf{ln}\ n)=O(n\mathbf{ln}n) ∴E(T(A))=i=1∑n−1j=i+1∑nj−i+12=i=1∑n−1k=1∑n−1k+12<(n−1)k=1∑n−1k2=(n−1)O(ln n)=O(nlnn)
5.3 最小割(Min Cut): Karger
在连通无向图G=(V,E)G=(V,E)G=(V,E)上, 至少删除几条边可使原图不连通
- 确定性算法: 根据最大流最小割定理, 可以用最大流算法求得有向图上, 分割源点和汇点间的最小割, 常见的算法约为O(n4)∼O(n5)O(n^4)\sim O(n^5)O(n4)∼O(n5)
- FF算法O(∣V∣∣E∣2)O(|V||E|^2)O(∣V∣∣E∣2)
- EK算法O(∣V∣∣E∣2)O(|V||E|^2)O(∣V∣∣E∣2)
- Dinic算法O(∣V∣2∣E∣)O(|V|^2|E|)O(∣V∣2∣E∣)
- SAP算法O(∣V∣2∣E∣)O(|V|^2|E|)O(∣V∣2∣E∣)
- 最小割的随机算法:
- 收缩操作(Contraction): 按照均匀分布随机从图里选择一条边, 将边上两个点缩为一个点, 并将两点间所有边删除.
- 重复步骤1, 直到图中只剩下两个点(此时图不再是简单图)
- 最终: 两点间边的个数即为最小割
最小割的随机算法分析:
对于无边权的最小割, 割的数目等于节点最小度数
该贪心策略既不保证可行, 也不保证最优
算法效率很高, 时间复杂度O(n)
有多大概率算法可以给出一个最小割?
假设图中有nnn个点, 最小割为kkk, 此时即使最小割有多种, 我们只关心其中一种, 用边集CCC表示最小割的集合(包含kkk条边), 于是, 问题转化为在n−2n-2n−2次收缩操作中, 均未选中C中边的概率.
- 图中至少有nk2\frac{nk}{2}2nk条边 (最小割即为节点最小度, 再根据握手定理)
- 令ϵi\epsilon_iϵi为第iii次收缩时没有选中CCC中的边, 那么对第一次:
P(ϵ1)≥1−kkn/2=1−2n选中的概率为:kkn/2P(\epsilon_1)\ge 1 - \frac{k}{kn/2} = 1 - \frac{2}{n} \\ 选中的概率为: \frac{k}{kn/2} P(ϵ1)≥1−kn/2k=1−n2选中的概率为:kn/2k
- 在第一次的基础上:
P(ϵ2∣ϵ1)≥1−kk(n−1)/2=1−2n−1P(\epsilon_2|\epsilon_1) \ge 1 - \frac{k}{k(n-1)/2} = 1 - \frac{2}{n-1} P(ϵ2∣ϵ1)≥1−k(n−1)/2k=1−n−12
-
第n-2次…:
P(ϵn−2∣⋂i=1n−3ϵi)≥∏i=1n−3(1−2(n−k+1))=2n(n−1)≥2n2P(\epsilon_{n-2}|\bigcap_{i=1}^{n-3} \epsilon_i) \ge \prod_{i=1}^{n-3}( 1 - \frac{2}{(n-k+1)}) = \frac{2}{n(n-1)}\ge \frac{2}{n^2} P(ϵn−2∣i=1⋂n−3ϵi)≥i=1∏n−3(1−(n−k+1)2)=n(n−1)2≥n22 -
如果要正确得到最小割, n-2次收缩过程中不能将CCC中的边收缩掉, 因此成功得到最小割的概率即为P(ϵn−2∣⋂i=1n−3ϵi)≥2n2P(\epsilon_{n-2}|\bigcap_{i=1}^{n-3}\epsilon_i) \ge \frac{2}{n^2}P(ϵn−2∣⋂i=1n−3ϵi)≥n22
-
如果独立重复执行n22\frac{n^2}{2}2n2次算法, 全部失败的概率:
P(fail)≤(1−2n2)n22<1e在O(n3)复杂度内,正确率超过1−1e.P(fail) \le (1-\frac{2}{n^2})^\frac{n^2}{2} \lt \frac{1}{e} \\ 在O(n^3)复杂度内, 正确率超过1-\frac{1}{e}. P(fail)≤(1−n22)2n2<e1在O(n3)复杂度内,正确率超过1−e1.
5.4 博弈树:
- 确定性算法: 极小化极大算法(Minimax Algorithm)
- 启发式优化: Alpha-beta剪枝
6. 作业习题
6.1 取快递:
目前,小明有 m 个快递需要取,但是他计划至多跑 n 次就将所有的快递取回来,并且绝对不拖延的小明还要保证每次取的快递数不少于之后每次取的快递数。
但是纠结的小明就在想,一共有多少种不同的取快递方式。
不过为了减少纠结,他决定只考虑每次取的快递数,也就是假设所有快递都是完全相同的。
输入
两个正整数 m 和 n,分别表示快递总数和计划最多几次取完快递。
输出
共有多少种不同的取快递的方案数(仅以每次取的快递数目做区分,即假设所有快递完全一样)
#include<iostream>
#include <vector>using namespace std;int main() {int m, n;cin>>m>>n;if (n > m) {n = m;}int dp[m+1][n+1];for (int i = 0; i <= m; i++) {for (int j = 0; j <= n; j++) {if (i == 0 || j == 0) {dp[i][j] = 1;} else if (i == 1 || j == 1) {dp[i][j] = 1;} else {if (j > i) {dp[i][j] = dp[i][i];} else {dp[i][j] = dp[i-j][j] + dp[i][j-1];}}}}cout<<dp[m][n]<<endl;return 0;
}
6.2 确实是凉菜:
小明决定自己做一份“精品”的乾隆白菜。
首先,他准备了 n 颗重量都是整数的精品白菜叶作为食材。
接下来,他需要将这些白菜叶撕成至少 m 片来完成这道菜,有强迫症的小明为了让这道菜更加精品,他要求每片菜叶的重量相同,且必须也是整数。
强迫症是可怕的,为了不让这道菜毁为白菜碎,小明还要保证每片白菜叶的重量尽可能大。
那么请问,成菜中每片白菜的最大重量会是多少?
输入
第一行两个整数 n 和 m,分别表示食材的颗数和至少需要的片数。 第二行 n 个正整数,a_i 表示食材中每颗白菜叶的重量。
输出
精品乾隆白菜中每片菜叶的重量。
6.3 紧急封城:
在疫情最严重的时候,暂时关闭城市间的道路进行隔离是很有效的防护手段。
现在有n (1 <= n <= 10000) 个城市,然后有 n-1 条道路将这些城市连接了起来(即这几个城市的交通网络是一个树结构)。
接下来,需要对这n个城市进行隔离处理,隔离的方式就是通过关闭一些道路,使得原始的城市交通树分解为几个连通的子树。但是,出于特殊政策的考虑,每个子树必须具有偶数个城市。
为了使得隔离的效果最好,我们需要在满足每个子树都有偶数个城市的情况下,删除最多的边。请编程计算最多可以删多少条边?
输入
第一行一个正整数 n (1 <= n <= 10000),表示城市的数量。 接下来 n-1 行,每行有两个整数 u, v (1<= u, v <= n),表示城市u和v间存在一条道路。 输入数据保证城市间的交通网络是一个连通的树结构。
输出
请输出在满足每个子树的城市数都是偶数的情况下,最多可以删除的边的数量。 如果不存在使每个子树的城市数都是偶数的删边方案,请输出-1.
6.4 等你下课
小明现在正在带球组织进攻,目前他附近有 n 位队友可以进行传球配合。
小明作为主力射手,他希望和队友通过 k 次传球后,球还在自己脚下,并完成射门。
请计算这其中有多少种不同的传球方式。
输入
正整数 n 和 m,分别表示小明身边的队友数和传球次数。
输出
不同的传球方式数(由于该数字可能很大,请输出总方式数对 10^9+7 的余数即可)
7. 模块题型:
7.1 n个盘子m个球:
7.1.1 球同, 盒不同, 不能空:
上面的取快递题目, 如果取快递数量没有被限制, 那么就是球同盒不同(对顺序有要求了)问题且不能为空
- 隔板法: 用n-1个板子, 放在m-1个空隙上:
Cm−1n−1C_{m-1}^{n-1} Cm−1n−1
7.1.2 球同, 盒不同, 能空:
- 等价于: 用n+m个球放在n个不同的盘子里:
Cn+m−1n−1C_{n+m-1}^{n-1} Cn+m−1n−1
7.1.3 球不同, 盒同, 不能空:
- 第二类斯特林数: 盒子本是相同, 但里面球的个数使得他看来不同
dp[m][n]=n×dp[m−1][n]+dp[m−1][n−1]dp[m][n] = n\times dp[m-1][n] + dp[m-1][n-1] dp[m][n]=n×dp[m−1][n]+dp[m−1][n−1]
7.1.4 球不同, 盒同, 可以空:
- 第二类斯特林数的第二维前缀和:
dp[m][n]=∑i=1ndp[m][i]dp[m][n] = \sum_{i=1}^{n}dp[m][i] dp[m][n]=i=1∑ndp[m][i]
7.1.5 球不同, 盒不同, 不能为空:
- 第二类斯特林数的全排列:
n!dp[m][n]n!dp[m][n] n!dp[m][n]
7.1.6 球不同, 盒不同, 可以为空:
- 每个球分配一个盒子序号, 每个球有n种可能:
nmn^m nm
7.1.7 球同, 盒同, 可以为空:
这就是取快递的题目
dp[m][n]=dp[m][n−1]+dp[m−1][n]dp[m][n]=dp[m][n-1] + dp[m-1][n] dp[m][n]=dp[m][n−1]+dp[m−1][n]
7.1.8 球同, 盒同, 不可以为空:
等价于先放n个球到盒子里面, 再考虑可以为空:
dpdp[m−n][n]dpdp[m-n][n] dpdp[m−n][n]
7.1.9 全错位排列递推:
把编号1~n的小球放到编号1~n的盘子里, 全错位排列(球和盘子的序号不能一样), 共有几种情况?
fn=(n−1)(fn−1+fn−2)f_n=(n-1)(f_{n-1} +f_{n-2}) fn=(n−1)(fn−1+fn−2)
7.1.10 排列组合公式:
- 组合数:
Cnm=n!m!(n−m)!C_n^m = \frac{n!}{m!(n-m)!} Cnm=m!(n−m)!n!
Cnm=Cn−1m+Cn−1m−1,将组合拆为:包含特定元素的排列和不包含特定元素的排列C_n^m = C_{n-1}^m + C_{n-1}^{m-1}, 将组合拆为: 包含特定元素的排列和不包含特定元素的排列 Cnm=Cn−1m+Cn−1m−1,将组合拆为:包含特定元素的排列和不包含特定元素的排列
Cnm=Cnn−m,选上已有的,等价于选没被选上的.C_n^m = C_n^{n-m}, 选上已有的, 等价于选没被选上的. Cnm=Cnn−m,选上已有的,等价于选没被选上的.
- 排列数:
Anm=n!(n−m)!A_n^m = \frac{n!}{(n-m)!} Anm=(n−m)!n!
Anm=nAn−1m−1,先安排特定位置,再安排其他位置A_n^m=nA_{n-1}^{m-1}, 先安排特定位置, 再安排其他位置 Anm=nAn−1m−1,先安排特定位置,再安排其他位置
Anm=mAn−1m−1+An−1m,所有球都不放在某个位置加上某个球固定在某个位置A_n^m = mA_{n-1}^{m-1}+A_{n-1}^{m}, 所有球都不放在某个位置加上某个球固定在某个位置 Anm=mAn−1m−1+An−1m,所有球都不放在某个位置加上某个球固定在某个位置
https://en.wikipedia.org/wiki/Optimization_problem ↩︎
https://en.wikipedia.org/wiki/NP-hardness ↩︎








