您现在的位置是:主页 > news > 网站怎么做微博认证/线上推广外包公司
网站怎么做微博认证/线上推广外包公司
![]() admin2025/6/20 9:42:27【news】
admin2025/6/20 9:42:27【news】
简介网站怎么做微博认证,线上推广外包公司,上海工作网站,wordpress 定制 价钱原作者:张威翻译:雷萧萧原文链接:https://dark417.github.io/MachineLearning/sv_discriminative_model_ch/dark417.github.io最新的版本在原文链接里可以找到。原博客会不断更新。这篇笔记主要梳理了吴恩达教授在斯坦福的CS229课程的内容&…

原作者:张威
翻译:雷萧萧
原文链接:
https://dark417.github.io/MachineLearning/sv_discriminative_model_ch/dark417.github.io最新的版本在原文链接里可以找到。原博客会不断更新。这篇笔记主要梳理了吴恩达教授在斯坦福的CS229课程的内容,并结合了哥伦比亚大学几个教授相关笔记内容一并总结。
请注意: 本文是翻译的一份学习资料,英文原版请点击Wei的学习笔记:
Discriminative Algorithmwei2624.github.io
中文版将不断和原作者的英文笔记同步内容,定期更新和维护。
一类经典的学习模式叫做监督学习(supervised learning)。在这种模式下,我们有输入模块,叫特征(features),和输出模块,叫目标(target)。学习的目的是基于给定的输入和对应的标签训练模型,然后用训练好的模型对给定的新输入来预测输出。
为此,我们收集一个训练数据集(training set),在这个数据集中,我们有许多成对的训练样本,每对样本包含特征向量(feature vector)作为输入(用符号X表示所有的特征向量)及其相应的目标(output)作为输出(用符号Y表示所有的目标值)。 由于每一个输入都有来自事实对应的标签,我们将这种学习称为监督学习(supervised learning)(有对应标签),同时将训练好的模型称为假设(hypothesis)。 下表是一个例子。
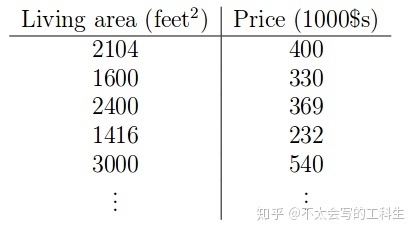
在这种情况下,我们将房子的居住面积作为特征,把价格作为目标。学习任务为给定一个新房子居住面积作为输入,用训练好的模型预测新房子的价格。
当目标输出处于连续空间时,我们将其称为回归问题(regression problem)。 当目标输出处于离散空间时,我们将其称为**分类问题(classification problem)**。
1 线性回归 Linear Regression
线性回归问题可以通过以下公式来建模:
我们以
为了训练模型,我们定义以下**代价函数(cost function)**,并试图将它最小化:
训练的目的是找到最小化代价的
1.1 最小均方算法Least Mean Square(LMS) algorithm
LMS算法主要使用**梯度下降(gradient descent)**来找到**局部最小值(local minimum)**。 为了实现它,我们将参数初始化为0,即
其中j可以遍历特征向量中的所有维度。 alpha 被称为**学习率(learning rate)**,它控制模型学习/训练的速度。这种一步步更新来找到最小值叫**迭代算法(iterative algorithm)**。
现在,我们根据一个样本求偏导数:
**数学解释**:第二行是求导数的**链式规则(chain rule)**。在第三行,我根据定义扩展
所以,所有样本的更新是:
其中m是训练样本的数量,j可以跨越特征向量的维度。 该算法从每个训练样本中获取对应梯度信息。 我们称之为**批量梯度下降(batch gradient descent)**。 该方法对**局部最小值**(即可能到达的**鞍点(saddle point)**)敏感,而我们通常假设代价函数仅有**全局最小值(global minimum)(J是凸函数(convex function))**, 这也是这个例子的情况 。梯度变化如下图所示:
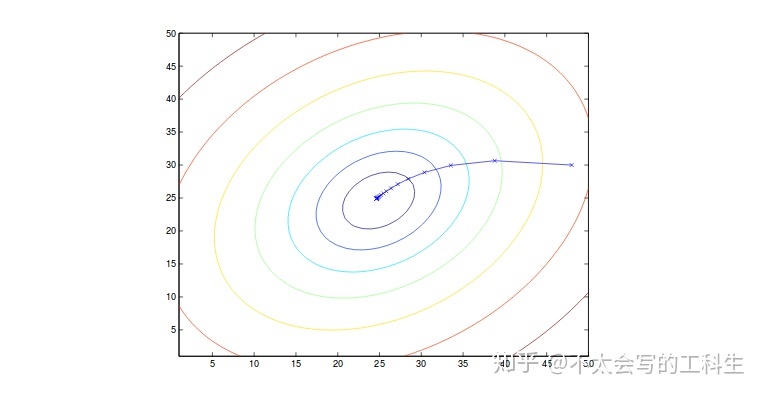
请注意,在更新过程中,我们会遍历所有样本以向局部最小值前进一步。如果m非常大,则该算法每一次迭代计算量十分巨大。 因此,在这种情况下,我们引入了一个类似算法,称为**随机梯度下降(stochastic gradient descent)**。其中每次算法只会从一小部分样本中计算代价和梯度。 尽管它可能会在最小值处振荡(并没有严格到达最小),但这样做使模型可以更快收敛。因此,我们经常在现实中使用它。
当不能直接计算或者很难计算使目标函数的导数并设为0的求参数时,我们会用以上的迭代算法。如果可以直接计算使导数为0的参数,我们可以通过下面的正则方程直接计算。
2 正则方程 Normal Equations
回想一下求函数最值的方法,我们可以设函数的导数为0来求得函数的最值,这样我们可以直接地计算局部最小值,而不是通过多次迭代。首先让我们来复习一下数学!
2.1 矩阵导数
一些相关概念在其他页面中有所讨论,你可以在
https://wei2624.github.io/math/Useful-Formulas-for-Math/wei2624.github.io查看。
在本小节中,我将讨论线性代数中矩阵的迹(trace)的计算,迹被定义为:
其中A必须是方矩阵。现在我将列出迹的属性和对应证明。
**证明**:
**证明**:
另一个证明类似。 请注意,由于矩阵维度约束,你无法随机调整每个矩阵的顺序。
**证明**:与上面类似
**证明**:
**证明**:与上面类似。
**证明**:与上面类似。
**证明**:
我们知道:
带入可得:
**证明**:假设
**证明**:trace只存在于方矩阵,,因此可得
2.2 再看Least Square
因此,现在我们不是迭代地找到解决方案,而是明确地直接计算代价函数对于
我们定义训练集输入为:
输出为:
定义模型为
因此,
现在我们需要找到J对于
我们知道标量的迹是它自己,因此:
**数学解释**:标量
我们将它设为0,可得正则方程,即:
因此我们可算出使矩阵导数为0的
3 概率解释
正则方程是找到解的一种确定性方法,让我们看看如何从随机性的角度解释它。随机性解释下最终应该得到相同的结果。
我们知道输入和输出的关系为:
其中
当x已知并具有固定参数
我们需要找到满足以下条件的
对于
4 局部加权线性回归
在上面讨论的回归方法中,我们平等对待在每个训练样本产生的代价。 但是每个样本所带来的代价是不一样的,尤其是一些**异常值(outlier)**会增加很多代价,我们应该减少它们权重。因此我们根据**查询点(querying point)**来计算每个样本的权重。 例如,这样的权重可以是:
虽然这个表达式看似于高斯,但它们无关。 x是查询点。 我们需要保留所有训练数据以进行新的预测。
5 分类与逻辑回归
我们可以将分类问题当做一个特殊的回归问题,我们只回归到一组二进制值0和1。有时,我们也使用-1和1表示法,我们分别称它为负类和正类。
然而,如果我们在这里应用线性回归模型,那么我们预测0和1以外的任何值是没有意义的。因此,我们将假设函数修改为:
其中g称为**逻辑函数**或**sigmoid函数**,如图所示:
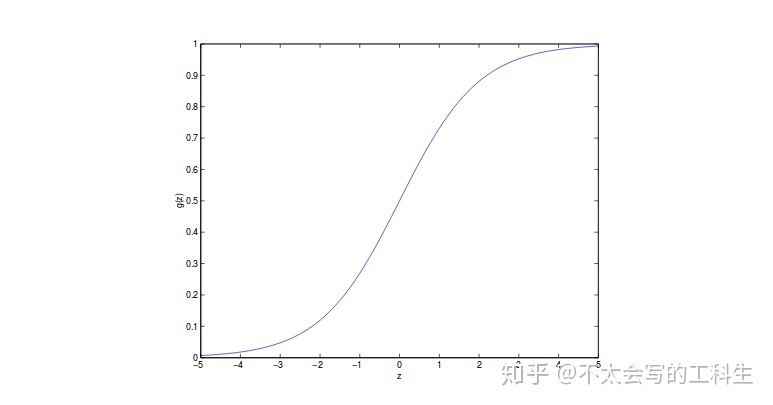
输出范围从0到1。这直观地解释了为什么我们将其称为回归,因为它在连续的空间中输出。 但是,该值表示属于某一类的概率。 所以基本上它是一个分类器。
让我们来看看逻辑函数的导数会是什么:
有了这个知识,接下来的问题是如何找到
我们认为:
其中y应为1或0。 假设样本是独立同分布,我们有似然函数:
使用log函数,可得:
然后,我们可以使用梯度下降来优化代价函数。 在更新中,我们应该有
从第一行到第二行,我们使用上面导出的逻辑函数的导数。 这为我们提供了特征向量上每个维度的更新规则。 虽然在这种情况下我们有与LMS相同的算法,但在这种情况下的假设函数是不同的。 当我们谈论广义线性化模型时,使用相同的等式并不是偶然。
6 插话:感知器学习算法
我们在之后的学习理论中会继续讨论,简单来讲,我们把假设函数调整为:
之前的更新方程保持不变,这就是**感知器学习算法**。
7 牛顿最大化方法
想象一下,我们想要找到函数f的根。 牛顿法允许我们以二次速度完成这项任务。 这个想法是:随机初始化 x_0 并找到 f(x_0) 的切线,标记为 f^{prime}(x_0) 。 我们使用 f^{prime}(x_0) 的根作为新x。 我们还将新x和旧x之间的距离定义为 Delta 。 下图可以展示这个过程:
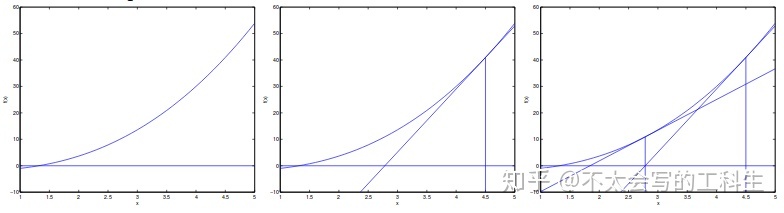
所以我们得到:
从这个想法得出,我们可以让
如果
简而言之,为了更新,我们有:
虽然它也可以二次收敛,但是计算起来可比梯度下降麻烦得多。
8 广义线性模型和指数族
在我们更新逻辑回归和最小均方回归时形式一样,这看似巧合。主要是因为它们是大家族广义线性模型中的特殊情况。 它被称为线性的原因是该族中的每个分布中的变量和它们的权重之间存在线性关系。
在进入广义线性模型之前,我们讨论指数族分布作为它的基础。 如果可以以下面的形式来表示一个分布,我们定义在指数族中的一类分布:
其中
T,a和b是固定参数,我们可以通过改变
伯努利:
其中:
高斯:
其中
其他指数分布:多项分布,泊松分布,伽马分布和指数分布,贝塔分布和狄利克雷分布。 由于它们都处于指数族,我们能做的是研究一般形式的指数族,并改变
9 构建广义线性模型
如上所述,一旦我们知道了T,a和b,就已经确定了分布族。 我们只需要找到
例如,假设我们想要基于给定的x预测y。 在继续推导出这个回归问题的构建广义线性模型之前,我们对此做出三个主要假设:
**(1)**我们总是假设
**(2)**通常,我们想要预测给定x的T(y)的期望值。 最有可能的是,我们有 T(y) = y 。定义上,我们有
**(3)**输入和自然参数关联为:
9.1 普通最小二乘法
在这种情况下,我们有
其中第一个等式来自假设(2); 第二个是定义; 第三个来自之前的推导; 最后一个是假设(3)。
9.2 逻辑回归
在此设置中,我们预测类标签为1或0。 回想一下,在伯努利中,我们有
这部分解释了为什么我们得出了sigmoid函数这样的形式。 因为我们假设当给定x,y是伯努利分布,所以由指数族来产生sigmoid函数是很自然的事。 为了预测,我们认为 T(y) 是相对于
。 通常,响应函数是
9.3 Softmax回归
在更广泛的情况下,我们可以有多个类而不是上面的二项类。 将其建模为多项分布是很自然的,它也属于可以从广义线性模型导出的指数族。
在多项分布中,我们可以将
我们首先定义
注意,对于 T(k) ,我们在向量中只有全零,因为向量的长度是k-1。 我们让
现在,我们展示了将多项式推导为指数族的步骤:
其中
并且,
这将多项式表示为指数族。 我们现在可以将链接函数视为:
为了得到响应函数,我们改变链式函数:
因此我们得到响应函数为:
这个响应函数就是我们的**softmax函数**。
根据广义线性模型中的假设(3),我们知道对于对于
这个模型就叫做**softmax回归**,是逻辑回归的广泛形式。因此,假设函数成为:
现在,我们需要优化
我们可以用梯度下降或者牛顿方法来找到最大值。
**记住**:逻辑回归是softmax回归的二项形式。sigmoid函数是softmax函数的二项形式˙








