您现在的位置是:主页 > news > 网站主机 分为/贵阳网站建设公司
网站主机 分为/贵阳网站建设公司
![]() admin2025/6/19 15:46:24【news】
admin2025/6/19 15:46:24【news】
简介网站主机 分为,贵阳网站建设公司,深圳手机端网站建设模板,高端房产网站建设作者:Yves Trudeau前言作为 Percona 的首席架构师,我的主要职责之一是对客户的数据库进行性能方面的优化,这使得工作复杂且非常有趣。在这篇文章中,我想讨论一个最重要的问题:选择最佳的 InnoDB 主键。InnoDB 主键有什…
前言作为 Percona 的首席架构师,我的主要职责之一是对客户的数据库进行性能方面的优化,这使得工作复杂且非常有趣。在这篇文章中,我想讨论一个最重要的问题:选择最佳的 InnoDB 主键。InnoDB 主键有什么特别之处?InnoDB 被称为索引组织型的存储引擎。主键使用的 B-Tree 来存储数据,即表行。这意味着 InnoDB 必须使用主键。如果表没有主键,InnoDB 会向表中添加一个隐藏的自动递增的 6 字节计数器,并使用该隐藏计数器作为主键。InnoDB 的隐藏主键存在一些问题。您应该始终在表上定义显式主键,并通过主键值访问所有 InnoDB 行。InnoDB 的二级索引也是一个B-Tree。搜索关键字由索引列组成,存储的值是匹配行的主键。通过二级索引进行搜索通常会导致主键的隐式搜索。什么是 B-Tree?一个 B-Tree 是一种针对在块设备上优化操作的数据结构。块设备或磁盘有相当重要的数据访问延迟,尤其是机械硬盘。在随机位置检索单个字节并不比检索更大的数据花费的时间更少。这是 B-Tree 的基本原理,InnoDB 使用的数据页为 16KB。让我们尝试简化 B-Tree 的描述。B-Tree 是围绕这键来组织的数据结构。键用于搜索 B-Tree 内的数据。B-Tree 通常有多个级别。数据仅存储在最底层,即叶子节点。其他级别的页面(节点)仅包含下一级别的页面的键和指针。如果要访问键值的数据,则从顶级节点-根节点开始,将其包含的键与搜索值进行比较,并找到要在下一级访问的页面。重复这个过程,直到你达到最后一个级别,即叶子节点。理论上,每个 B-Tree 级别的读取都需要一次磁盘读取操作。在实践中,总是有内存缓存节点,因为它们数量较少且经常访问,因此适合缓存。作者:Yves Trudeau
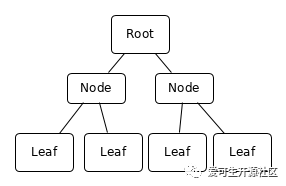 一个简单的三级 B-Tree 结构有序的插入示例让我们考虑以下 sysbench 表:
一个简单的三级 B-Tree 结构有序的插入示例让我们考虑以下 sysbench 表:mysql> show create table sbtest1\G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=3000001 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
mysql> show table status like 'sbtest1'\G
*************************** 1. row ***************************
Name: sbtest1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 2882954
Avg_row_length: 234
Data_length: 675282944
Max_data_length: 0
Index_length: 47775744
Data_free: 3145728
Auto_increment: 3000001
Create_time: 2018-07-13 18:27:09
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
innodb_fill_factor设为 100,InnoDB 最多使用 15KB 的数据填充空间。这导致在初始插入数据之后,需要拆分页面。页面中还有一些页眉和页脚。如果页面太满且无法添加更多数据,则页面将拆分为两个。同样,如果两个相邻页面的填充率低于 50%,InnoDB 将合并它们。例如,这是以 ID 顺序插入的 sysbench 表:mysql> select count(*), TABLE_NAME,INDEX_NAME, avg(NUMBER_RECORDS), avg(DATA_SIZE) from information_schema.INNODB_BUFFER_PAGE
-> WHERE TABLE_NAME='`sbtest`.`sbtest1`' group by TABLE_NAME,INDEX_NAME order by count(*) desc;
+----------+--------------------+------------+---------------------+----------------+
| count(*) | TABLE_NAME | INDEX_NAME | avg(NUMBER_RECORDS) | avg(DATA_SIZE) |
+----------+--------------------+------------+---------------------+----------------+
| 13643 | `sbtest`.`sbtest1` | PRIMARY | 75.0709 | 15035.8929 |
| 44 | `sbtest`.`sbtest1` | k_1 | 1150.3864 | 15182.0227 |
+----------+--------------------+------------+---------------------+----------------+
2 rows in set (0.09 sec)
mysql> select PAGE_NUMBER,NUMBER_RECORDS,DATA_SIZE,INDEX_NAME,TABLE_NAME from information_schema.INNODB_BUFFER_PAGE
-> WHERE TABLE_NAME='`sbtest`.`sbtest1`' order by PAGE_NUMBER limit 1;
+-------------+----------------+-----------+------------+--------------------+
| PAGE_NUMBER | NUMBER_RECORDS | DATA_SIZE | INDEX_NAME | TABLE_NAME |
+-------------+----------------+-----------+------------+--------------------+
| 3 | 35 | 455 | PRIMARY | `sbtest`.`sbtest1` |
+-------------+----------------+-----------+------------+--------------------+
1 row in set (0.04 sec)
mysql> select PAGE_NUMBER,NUMBER_RECORDS,DATA_SIZE,INDEX_NAME,TABLE_NAME from information_schema.INNODB_BUFFER_PAGE
-> WHERE TABLE_NAME='`sbtest`.`sbtest1`' order by NUMBER_RECORDS desc limit 3;
+-------------+----------------+-----------+------------+--------------------+
| PAGE_NUMBER | NUMBER_RECORDS | DATA_SIZE | INDEX_NAME | TABLE_NAME |
+-------------+----------------+-----------+------------+--------------------+
| 39 | 1203 | 15639 | PRIMARY | `sbtest`.`sbtest1` |
| 61 | 1203 | 15639 | PRIMARY | `sbtest`.`sbtest1` |
| 37 | 1203 | 15639 | PRIMARY | `sbtest`.`sbtest1` |
+-------------+----------------+-----------+------------+--------------------+
3 rows in set (0.03 sec)
mysql> show table status like 'sbtest1'\G
*************************** 1. row ***************************
Name: sbtest1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 3137367
Avg_row_length: 346
Data_length: 1088405504
Max_data_length: 0
Index_length: 47775744
Data_free: 15728640
Auto_increment: NULL
Create_time: 2018-07-19 19:10:36
Update_time: 2018-07-19 19:09:01
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
mysql> select count(*), TABLE_NAME,INDEX_NAME, avg(NUMBER_RECORDS), avg(DATA_SIZE) from information_schema.INNODB_BUFFER_PAGE
-> WHERE TABLE_NAME='`sbtestrandom`.`sbtest1`'group by TABLE_NAME,INDEX_NAME order by count(*) desc;
+----------+--------------------------+------------+---------------------+----------------+
| count(*) | TABLE_NAME | INDEX_NAME | avg(NUMBER_RECORDS) | avg(DATA_SIZE) |
+----------+--------------------------+------------+---------------------+----------------+
| 4022 | `sbtestrandom`.`sbtest1` | PRIMARY | 66.4441 | 10901.5962 |
| 2499 | `sbtestrandom`.`sbtest1` | k_1 | 1201.5702 | 15624.4146 |
+----------+--------------------------+------------+---------------------+----------------+
2 rows in set (0.06 sec)
# Query 1: 2.62 QPS, 0.00x concurrency, ID 0x019AC6AF303E539E758259537C5258A2 at byte 19976
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: 2018-07-19T20:28:02 to 2018-07-19T20:28:23
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 48 55
# Exec time 76 93ms 637us 3ms 2ms 2ms 458us 2ms
# Lock time 100 10ms 72us 297us 182us 247us 47us 176us
# Rows sent 100 1.34k 16 36 25.04 31.70 4.22 24.84
# Rows examine 100 1.34k 16 36 25.04 31.70 4.22 24.84
# Rows affecte 0 0 0 0 0 0 0 0
# InnoDB:
# IO r bytes 0 0 0 0 0 0 0 0
# IO r ops 0 0 0 0 0 0 0 0
# IO r wait 0 0 0 0 0 0 0 0
# pages distin 100 1.36k 18 35 25.31 31.70 3.70 24.84
# EXPLAIN /*!50100 PARTITIONS*/
select * from friends where user_id = 1234\G
CREATE TABLE `friends` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL,
`friend_user_id` int(10) unsigned NOT NULL,
`created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`active` tinyint(4) NOT NULL DEFAULT '1',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_id_friend` (`user_id`,`friend_user_id`),
KEY `idx_friend` (`friend_user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=144002 DEFAULT CHARSET=latin1
mysql> select * from friends where user_id = 1234 order by id limit 10;
+-------+---------+----------------+---------------------+--------+
| id | user_id | friend_user_id | created | active |
+-------+---------+----------------+---------------------+--------+
| 257 | 1234 | 43 | 2018-07-19 20:14:47 | 1 |
| 7400 | 1234 | 1503 | 2018-07-19 20:14:49 | 1 |
| 13361 | 1234 | 814 | 2018-07-19 20:15:46 | 1 |
| 13793 | 1234 | 668 | 2018-07-19 20:15:47 | 1 |
| 14486 | 1234 | 1588 | 2018-07-19 20:15:47 | 1 |
| 30752 | 1234 | 1938 | 2018-07-19 20:16:27 | 1 |
| 31502 | 1234 | 733 | 2018-07-19 20:16:28 | 1 |
| 32987 | 1234 | 1907 | 2018-07-19 20:16:29 | 1 |
| 35867 | 1234 | 1068 | 2018-07-19 20:16:30 | 1 |
| 41471 | 1234 | 751 | 2018-07-19 20:16:32 | 1 |
+-------+---------+----------------+---------------------+--------+
10 rows in set (0.00 sec)
93% 访问 userid
5% 访问 friendid
- 2% 访问 id
CREATE TABLE `friends` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL,
`friend_user_id` int(10) unsigned NOT NULL,
`created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`active` tinyint(4) NOT NULL DEFAULT '1',
PRIMARY KEY (`user_id`,`friend_user_id`),
KEY `idx_friend` (`friend_user_id`),
KEY `idx_id` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=144002 DEFAULT CHARSET=latin1
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Rows examine 100 1.23k 16 34 23.72 30.19 4.19 22.53
# pages distin 100 111 2 5 2.09 1.96 0.44 1.96
游戏排行榜(按用户)
用户偏好(按用户)
消息应用程序(来自或来自)
用户对象存储(按用户)
喜欢物品(按项目)
- 项目评论(按项目)
当您没有显性访问模式时,您可以做些什么?一种选择是使用覆盖指数。覆盖索引需要涵盖所有必需的列。列的顺序也很重要,因为第一个必须是分组值。另一种选择是使用分区在数据集中创建易于缓存的热点。
我们在本文中看到了用于解决读密集型工作负载的常用策略。此策略不能始终有效 - 您必须通过通用模式访问数据。但是当它工作时,你选择了好的 InnoDB 主键,你就成了此刻的英雄!
社区近期动态
No.1
Mycat 问题免费诊断
诊断范围支持:
Mycat 的故障诊断、源码分析、性能优化
服务支持渠道:
技术交流群,进群后可提问
QQ群(669663113)
社区通道,邮件&电话
osc@actionsky.com
现场拜访,线下实地,1天免费拜访
关注“爱可生开源社区”公众号,回复关键字“Mycat”,获取活动详情。
No.2
社区技术内容征稿
征稿内容:
格式:.md/.doc/.txt
主题:MySQL、分布式中间件DBLE、数据传输组件DTLE相关技术内容
要求:原创且未发布过
奖励:作者署名;200元京东E卡+社区周边
投稿方式:
邮箱:osc@actionsky.com
格式:[投稿]姓名+文章标题
以附件形式发送,正文需注明姓名、手机号、微信号,以便小编及时联系

喜欢点“分享”,不行就“在看








