您现在的位置是:主页 > news > wordpress会影响网速吗/湖南靠谱seo优化
wordpress会影响网速吗/湖南靠谱seo优化
![]() admin2025/6/18 7:07:52【news】
admin2025/6/18 7:07:52【news】
简介wordpress会影响网速吗,湖南靠谱seo优化,WordPress 简历库,做ppt好的网站有哪些简介 本文是基于JDK7分析ConcurrentHashMap的实现原理,这个版本ConcurrentHashMap的代码实现比较清晰,代码加注释总共也就1622行,适合用来分析学习。 ConcurrentHashMap相当于多线程版本的HashMap,不会有线程安全问题,在多线程…
简介
本文是基于JDK7分析ConcurrentHashMap的实现原理,这个版本ConcurrentHashMap的代码实现比较清晰,代码加注释总共也就1622行,适合用来分析学习。
ConcurrentHashMap相当于多线程版本的HashMap,不会有线程安全问题,在多线程环境下使用HashMap可能产生死循环等问题,在这篇博客里做了很好的解释:老生常谈,HashMap的死循环,我们知道除了HashMap,还有线程安全的HashTable,HashTable的实现原理与HashMap一致,只是HashTable所有的方法都使用了synchronized来修饰确保线程安全性,这在多线程竞争激烈的环境下效率是很低的;ConcurrentHashMap通过锁分段,把整个哈希表ConcurrentHashMap分成了多个片段(segment),来确保线程安全。下面是JDK对ConcurrentHashMap的介绍:
A hash table supporting full concurrency of retrievals and high expected concurrency for updates. This class obeys the same functional specification as Hashtable, and includes versions of methods corresponding to each method of Hashtable. However, even though all operations are thread-safe, retrieval operations do not entail locking, and there is not any support for locking the entire table in a way that prevents all access. This class is fully interoperable with Hashtable in programs that rely on its thread safety but not on its synchronization details.
大意是ConcurrentHashMap支持并发的读写,支持HashTable的所有方法,实现并发读写不会锁定整个ConcurrentHashMap。
ConcurrentHashMap数据结构
我们回忆一下HashMap的数据结构(JDK7版本),核心是一个键值对Entry数组,键值对通过键的hash值映射到数组上:
ConcurrentHashMap在初始化时会要求初始化concurrencyLevel作为segment数组长度,即并发度,代表最多有多少个线程可以同时操作ConcurrentHashMap,默认是16,每个segment片段里面含有键值对HashEntry数组,是真正存放键值对的地方,这就是ConcurrentHashMap的数据结构。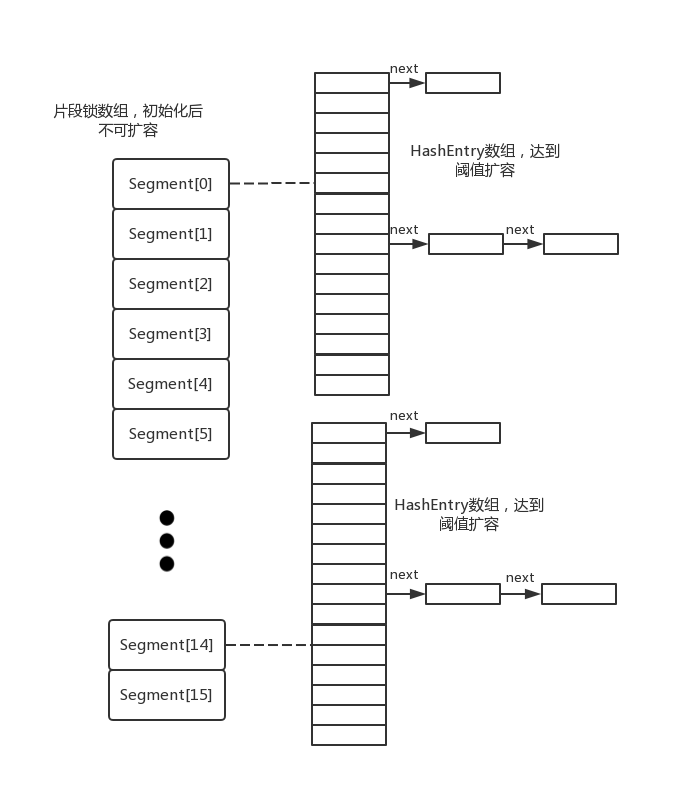
源码解析
从图中可以看到,ConcurrentHashMap离不开Segment,Segment是ConcurrentHashMap的一个静态内部类,可以看到Segment继承了重入锁ReentrantLock,要想访问Segment片段,线程必须获得同步锁,结构如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {//尝试获取锁的最多尝试次数,即自旋次数static final int MAX_SCAN_RETRIES =Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;//HashEntry数组,也就是键值对数组transient volatile HashEntry<K, V>[] table;//元素的个数transient int count;//segment中发生改变元素的操作的次数,如put/removetransient int modCount;//当table大小超过阈值时,对table进行扩容,值为capacity *loadFactortransient int threshold;//加载因子final float loadFactor;Segment(float lf, int threshold, HashEntry<K, V>[] tab) {this.loadFactor = lf;this.threshold = threshold;this.table = tab;}
}键值对HashEntry是ConcurrentHashMap的基本数据结构,多个HashEntry可以形成链表用于解决hash冲突。
static final class HashEntry<K,V> {//hash值final int hash;//键final K key;//值volatile V value;//下一个键值对volatile HashEntry<K, V> next;HashEntry(int hash, K key, V value, HashEntry<K, V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}
}ConcurrentHashMap成员变量和构造方法如下:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>implements ConcurrentMap<K, V>, Serializable {private static final long serialVersionUID = 7249069246763182397L;//默认的初始容量static final int DEFAULT_INITIAL_CAPACITY = 16;//默认加载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认的并发度,也就是默认的Segment数组长度static final int DEFAULT_CONCURRENCY_LEVEL = 16;//最大容量,ConcurrentMap最大容量static final int MAXIMUM_CAPACITY = 1 << 30;//每个segment中table数组的长度,必须是2^n,最小为2static final int MIN_SEGMENT_TABLE_CAPACITY = 2;//允许最大segment数量,用于限定concurrencyLevel的边界,必须是2^nstatic final int MAX_SEGMENTS = 1 << 16; // slightly conservative//非锁定情况下调用size和contains方法的重试次数,避免由于table连续被修改导致无限重试static final int RETRIES_BEFORE_LOCK = 2;//计算segment位置的掩码值final int segmentMask;//用于计算算segment位置时,hash参与运算的位数final int segmentShift;//Segment数组final Segment<K,V>[] segments;public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {//参数校验if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching arguments//找到一个大于等于传入的concurrencyLevel的2^n数,且与concurrencyLevel最接近//ssize作为Segment数组int sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;// 计算每个segment中table的容量int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;int cap = MIN_SEGMENT_TABLE_CAPACITY;// 确保cap是2^nwhile (cap < c)cap <<= 1;// create segments and segments[0]// 创建segments并初始化第一个segment数组,其余的segment延迟初始化Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]this.segments = ss;}}concurrencyLevel 参数表示期望并发的修改 ConcurrentHashMap 的线程数量,用于决定 Segment 的数量,通过算法可以知道就是找到最接近传入的concurrencyLevel的2的幂次方。而segmentMask 和 segmentShift看上去有点难以理解,作用主要是根据key的hash值做计算定位在哪个Segment片段。
对于哈希表而言,最重要的方法就是put和get了,下面分别来分析这两个方法的实现:
put(K key, V value)
put方法实际上只有两步:1.根据键的值定位键值对在那个segment片段 2.调用Segment的put方法
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();//计算键的hash值int hash = hash(key);//通过hash值运算把键值对定位到segment[j]片段上int j = (hash >>> segmentShift) & segmentMask;//检查segment[j]是否已经初始化了,没有的话调用ensureSegment初始化segment[j]if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);//向片段中插入键值对return s.put(key, hash, value, false);}- ensureSegment(int k)
我们从ConcurrentHashMap的构造函数可以发现Segment数组只初始化了Segment[0],其余的Segment是用到了在初始化,用了延迟加载的策略,而延迟加载调用的就是ensureSegment方法
private Segment<K,V> ensureSegment(int k) {final Segment<K,V>[] ss = this.segments;long u = (k << SSHIFT) + SBASE; // raw offsetSegment<K,V> seg;//按照segment[0]的HashEntry数组长度和加载因子初始化Segment[k]if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {Segment<K,V> proto = ss[0]; // use segment 0 as prototypeint cap = proto.table.length;float lf = proto.loadFactor;int threshold = (int)(cap * lf);HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheckSegment<K,V> s = new Segment<K,V>(lf, threshold, tab);while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))break;}}}return seg;}- put(K key, int hash, V value, boolean onlyIfAbsent)
调用Segment的put方法插入键值对到Segment的HashEntry数组
final V put(K key, int hash, V value, boolean onlyIfAbsent) {//Segment继承ReentrantLock,尝试获取独占锁HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);V oldValue;try {HashEntry<K,V>[] tab = table;//定位键值对在HashEntry数组上的位置int index = (tab.length - 1) & hash;//获取这个位置的第一个键值对HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {if (e != null) {//此处有链表结构,一直循环到e==nullK k;//存在与待插入键值对相同的键,则替换valueif ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {oldValue = e.value;if (!onlyIfAbsent) {//onlyIfAbsent默认为falsee.value = value;++modCount;}break;}e = e.next;}else {//node不为null,设置node的next为first,node为当前链表的头节点if (node != null)node.setNext(first);//node为null,创建头节点,指定next为first,node为当前链表的头节点elsenode = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;//扩容条件 (1)entry数量大于阈值 (2) 当前数组tab长度小于最大容量。满足以上条件就扩容if (c > threshold && tab.length < MAXIMUM_CAPACITY)//扩容rehash(node);else//tab的index位置设置为node,setEntryAt(tab, index, node);++modCount;count = c;oldValue = null;break;}}} finally {unlock();}return oldValue;}
- scanAndLockForPut(K key, int hash, V value)
在不超过最大重试次数MAX_SCAN_RETRIES通过CAS尝试获取锁
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {//first,e:键值对的hash值定位到数组tab的第一个键值对HashEntry<K,V> first = entryForHash(this, hash);HashEntry<K,V> e = first;HashEntry<K,V> node = null;int retries = -1; // negative while locating node//线程尝试通过CAS获取锁while (!tryLock()) {HashEntry<K,V> f; // to recheck first belowif (retries < 0) {//当e==null或key.equals(e.key)时retry=0,走出这个分支if (e == null) {if (node == null) // speculatively create node//初始化键值对,next指向nullnode = new HashEntry<K,V>(hash, key, value, null);retries = 0;}else if (key.equals(e.key))retries = 0;elsee = e.next;}//超过最大自旋次数,阻塞else if (++retries > MAX_SCAN_RETRIES) {lock();break;}//头节点发生变化,重新遍历else if ((retries & 1) == 0 &&(f = entryForHash(this, hash)) != first) {e = first = f; // re-traverse if entry changedretries = -1;}}return node;}- rehash(HashEntry<K,V> node)
用于对Segment的table数组进行扩容,扩容后的数组长度是原数组的两倍。
private void rehash(HashEntry<K,V> node) {//扩容前的旧tab数组HashEntry<K,V>[] oldTable = table;//扩容前数组长度int oldCapacity = oldTable.length;//扩容后数组长度(扩容前两倍)int newCapacity = oldCapacity << 1;//计算新的阈值threshold = (int)(newCapacity * loadFactor);//新的tab数组HashEntry<K,V>[] newTable =(HashEntry<K,V>[]) new HashEntry[newCapacity];//新的掩码int sizeMask = newCapacity - 1;//遍历旧的数组for (int i = 0; i < oldCapacity ; i++) {//遍历数组的每一个元素HashEntry<K,V> e = oldTable[i];if (e != null) {//元素e指向的下一个节点,如果存在hash冲突那么e不为空HashEntry<K,V> next = e.next;//计算元素在新数组的索引int idx = e.hash & sizeMask;// 桶中只有一个元素,把当前的e设置给新的tableif (next == null) // Single node on listnewTable[idx] = e;//桶中有布置一个元素的链表else { // Reuse consecutive sequence at same slotHashEntry<K,V> lastRun = e;// idx 是当前链表的头结点 e 的新位置int lastIdx = idx;for (HashEntry<K,V> last = next;last != null;last = last.next) {//k是单链表元素在新数组的位置int k = last.hash & sizeMask;//lastRun是最后一个扩容后不在原桶处的Entryif (k != lastIdx) {lastIdx = k;lastRun = last;}}//lastRun以及它后面的元素都在一个桶中newTable[lastIdx] = lastRun;// Clone remaining nodes//遍历到lastRun即可for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {V v = p.value;int h = p.hash;int k = h & sizeMask;HashEntry<K,V> n = newTable[k];newTable[k] = new HashEntry<K,V>(h, p.key, v, n);}}}}//处理引起扩容的那个待添加的节点int nodeIndex = node.hash & sizeMask; // add the new nodenode.setNext(newTable[nodeIndex]);newTable[nodeIndex] = node;//把Segment的table指向扩容后的tabletable = newTable;}
get(Object key)
get获取元素不需要加锁,效率高,获取key定位到的segment片段还是遍历table数组的HashEntry元素时使用了UNSAFE.getObjectVolatile保证了能够无锁且获取到最新的volatile变量的值
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;//计算key的hash值int h = hash(key);//根据hash值计算key在哪个segment片段long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;//获取segments[u]的table数组if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {//遍历table中的HashEntry元素for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {K k;//找到相同的key,返回valueif ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;}size()
size方法用来计算ConcurrentHashMap中储存元素的个数。那么在统计所有的segment元素的个数是否都需要上锁呢?如果不上锁在统计的过程中可能存在其他线程并发存储/删除元素,而如果上锁又会降低读写效率。ConcurrentHashMap在实现时使用了折中的方法,它会无锁遍历三次把所有的segment的modCount加到sum里面,如果与前一次遍历结果相比sum没有改变那么说明这两次遍历没有其他线程修改ConcurrentHashMap,返回segment的count的和;如果每次遍历与上一次相比都不一样那就上锁进行同步。
public int size() {// Try a few times to get accurate count. On failure due to// continuous async changes in table, resort to locking.final Segment<K,V>[] segments = this.segments;int size;boolean overflow; // true if size overflows 32 bitslong sum; // sum of modCountslong last = 0L; // previous sumint retries = -1; // first iteration isn't retrytry {for (;;) {//达到RETRIES_BEFORE_LOCK,也就是三次if (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)ensureSegment(j).lock(); // force creation}sum = 0L;size = 0;overflow = false;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);//遍历计算segment的modCount和count的和if (seg != null) {sum += seg.modCount;int c = seg.count;//是否溢出int范围if (c < 0 || (size += c) < 0)overflow = true;}}//last是上一次的sum值,相等跳出循环if (sum == last)break;last = sum;}} finally {//解锁if (retries > RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}}return overflow ? Integer.MAX_VALUE : size;}remove(Object key)
调用Segment的remove方法
public V remove(Object key) {int hash = hash(key);Segment<K,V> s = segmentForHash(hash);return s == null ? null : s.remove(key, hash, null);}- remove(Object key, int hash, Object value)
获取同步锁,移除指定的键值对
final V remove(Object key, int hash, Object value) {//获取同步锁if (!tryLock())scanAndLock(key, hash);V oldValue = null;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;HashEntry<K,V> e = entryAt(tab, index);//遍历链表用来保存当前链表节点的前一个节点HashEntry<K,V> pred = null;while (e != null) {K k;HashEntry<K,V> next = e.next;//找到key对应的键值对if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {V v = e.value;//键值对的值与传入的value相等if (value == null || value == v || value.equals(v)) {//当前元素为头节点,把当前元素的下一个节点设为头节点if (pred == null)setEntryAt(tab, index, next);//不是头节点,把当前链表节点的前一个节点的next指向当前节点的下一个节点elsepred.setNext(next);++modCount;--count;oldValue = v;}break;}pred = e;e = next;}} finally {unlock();}return oldValue;}
- scanAndLock(Object key, int hash)
扫描是否含有指定的key并且获取同步锁,当方法执行完毕也就是跳出循环肯定成功获取到同步锁,跳出循环有两种方式:1.tryLock方法尝试获取独占锁成功 2.尝试获取超过最大自旋次数MAX_SCAN_RETRIES线程堵塞,当线程从等待队列中被唤醒获取到锁跳出循环。
private void scanAndLock(Object key, int hash) {// similar to but simpler than scanAndLockForPutHashEntry<K,V> first = entryForHash(this, hash);HashEntry<K,V> e = first;int retries = -1;while (!tryLock()) {HashEntry<K,V> f;if (retries < 0) {if (e == null || key.equals(e.key))retries = 0;elsee = e.next;}else if (++retries > MAX_SCAN_RETRIES) {lock();break;}else if ((retries & 1) == 0 &&(f = entryForHash(this, hash)) != first) {e = first = f;retries = -1;}}}
isEmpty()
检查ConcurrentHashMap是否为空。同样没有使用同步锁,通过两次遍历:1.确定每个segment是否为0,其中任何一个segment的count不为0,就返回,都为0,就累加modCount为sum.2.第一个循环执行完还没有推出,map可能为空,再做一次遍历,如果在这个过程中任何一个segment的count不为0返回false,同时sum减去每个segment的modCount,若循环执行完程序还没有退出,比较sum是否为0,为0表示两次检查没有元素插入,map确实为空,否则map不为空。
public boolean isEmpty() {//累计segment的modCount值long sum = 0L;final Segment<K,V>[] segments = this.segments;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {if (seg.count != 0)return false;sum += seg.modCount;}}//再次检查if (sum != 0L) { // recheck unless no modificationsfor (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) {if (seg.count != 0)return false;sum -= seg.modCount;}}if (sum != 0L)return false;}return true;}总结
ConcurrentHashMap引入分段锁的概念提高了并发量,每当线程要修改哈希表时并不是锁住整个表,而是去操作某一个segment片段,只对segment做同步,通过细化锁的粒度提高了效率,相对与HashTable对整个哈希表做同步处理更实用与多线程环境。
如果你对编程感兴趣或者想往编程方向发展,可以关注微信公众号【筑梦编程】,大家一起交流讨论!小编也会每天定时更新既有趣又有用的编程知识!








