您现在的位置是:主页 > news > 三门网站建设/百度如何推广网站
三门网站建设/百度如何推广网站
![]() admin2025/6/15 19:26:59【news】
admin2025/6/15 19:26:59【news】
简介三门网站建设,百度如何推广网站,网站建设南京公司,重庆大渡口营销型网站建设公司哪家专业一、前言 接触k8s也有小一年了。跟着需求走很容易囫囵吞枣式的学习k8s, 知其然而不知其所以然。周末正好有时间,再回过头来看看k8s的实现方式。刚看了前几张官方文档,就产生了一个疑问:k8s为何要引入pod作为其控制的最小单元,直接…
一、前言
接触k8s也有小一年了。跟着需求走很容易囫囵吞枣式的学习k8s, 知其然而不知其所以然。周末正好有时间,再回过头来看看k8s的实现方式。刚看了前几张官方文档,就产生了一个疑问:k8s为何要引入pod作为其控制的最小单元,直接用容器不好吗?带着这个疑问,好好翻阅了一下资料,特此记录一下。
二、pod是什么?
Pod是 Kubernetes 项目中最小的 API 对象,而Pod也是由容器组组成的。Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。这个解释太官方了。你可以把pod想象成一个“豆荚” ,然后里面包着一组有关联关系的“豆子”(容器)。一个豆荚里的豆子,它们共同吸收着同一个养分,Pod也是如此,里面的容器共有着同一组资源。

上面这个图很形象的表达了pod和容器的关系。转换成咱们计算机的知识,其实,你把Pod想成虚拟机,然后容器想成虚拟机里面的应用你就明白很多了。我们还是拿K8S跟OpenStack对比就明白了:
| K8S | OpenStack |
|---|---|
| Pod | VM |
| Docker | application 应用、进程 |
OpenStack管理的VM可以说是OpenStack里的最小单元,虚拟机我们知道有隔离性,里面部署的应用只跑在虚拟机里面,他们共享这个VM的CPU、Mem、网络、存储资源。那么,同理Pod也是如此,Pod里面的容器共享着Pod里面的CPU、Mem、网络和存储资源。
三、pod的内部实现机制
因为Linux提供了Namespace和Cgroup两种机制才让容器的出现提供了可能。Namespace用于进程之间的隔离,Cgroup用于控制进程资源的使用;Namespace由hostname、PID、filesystem、network、IPC组成。在K8S里,Pod的生成也是基于Namespace和Cgroup的,所以Pod内的架构合成,我们可以用下面这张图画出来:

那这些要素是通过什么机制组合在一起呢?这里是通过一个叫Pause(gcr.io/google_containers/pause-amd64)的容器完成的。K8S在初始化一个Pod的时候会先启动一个叫Pause的容器,然后再启动用户自定义的业务容器。这个Pause容器我们认为它是一个“根容器”,它主要有两方面作用:
- 扮演PID 1的角色,处理僵尸进程
- 在Pod里为其他容器共享Linux namespace的基础
首先我们了解下Linux系统下PID为 1 的进程它的作用和意义。在Linux里,PID 为 1的进程,叫超级进程,也叫根进程,它是系统的第一个进程,是其他进程的父进程,所有的进程都会被挂在这个进程下。如果一个子进程的父进程退了,那么这个子进程会被挂到 PID 1 下面。
其次,我们知道容器本身就是一个进程。在一个Namespace下,Pause作为PID为1的进程存在于一个Pod里,其他的业务容器都挂载这个Pause进程下面。这样,一个Namespace下的进程就会以Pause作为根,呈树状的结构存在一个Pod下。
最后,Pause还有个功能是负责处理僵尸进程。僵尸进程:一个进程使用fork函数创建子进程,如果子进程退出,而父进程并没有来得及调用wait或waitpid获取其子进程的状态信息,那么这个子进程的描述符仍然保存在系统中,其进程号会一直存在被占用(而系统的进程号是有限的),这种进程称之为僵尸进程(Z开头)。
Pause这个容器代码是用C写的(代码见下),其中Pause的代码里,有个无限循环的for(;;)函数,函数里面执行的是pause( )函数,pause() 函数本身是在睡眠状态的, 直到被信号(signal)所中断。因此,正是因为这个机制,Pause容器会一直等待SIGCHLD信号,一旦有了SIGCHLD信号(进程终止或者停止时会发出这种信号),Pause就会启动sigreap方法,sigreap方法里就会调用waitpid获取其子进程的状态信息,这样自然就不会在Pod里产生僵尸进程了。
## Pause代码
static void sigdown(int signo) {psignal(signo, "Shutting down, got signal");exit(0);
}static void sigreap(int signo) {while (waitpid(-1, NULL, WNOHANG) > 0);
}int main() {if (getpid() != 1)/* Not an error because pause sees use outside of infra containers. */fprintf(stderr, "Warning: pause should be the first process\n");if (sigaction(SIGINT, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)return 1;if (sigaction(SIGTERM, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)return 2;if (sigaction(SIGCHLD, &(struct sigaction){.sa_handler = sigreap,.sa_flags = SA_NOCLDSTOP},NULL) < 0)return 3;## 关注这下面的for循环代码for (;;)pause();fprintf(stderr, "Error: infinite loop terminated\n");return 42;
}四、pod的网络通信
在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:

如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了
- 这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
而对于同一个 Pod 里面的所有用户容器来说,它们的进出流量,也可以认为都是通过 Infra 容器完成的。这一点很重要,因为将来如果你要为 Kubernetes 开发一个网络插件时,应该重点考虑的是如何配置这个 Pod 的 Network Namespace,而不是每一个用户容器如何使用你的网络配置,这是没有意义的。
这就意味着,如果你的网络插件需要在容器里安装某些包或者配置才能完成的话,是不可取的:Infra 容器镜像的 rootfs 里几乎什么都没有,没有你随意发挥的空间。当然,这同时也意味着你的网络插件完全不必关心用户容器的启动与否,而只需要关注如何配置 Pod,也就是 Infra 容器的 Network Namespace 即可。
五、Pod容器共享Volume
Volume类型包括:emtyDir、hostPath、gcePersistentDisk、awsElasticBlockStore、gitRepo、secret、nfs、scsi、glusterfs、persistentVolumeClaim、rbd、flexVolume、cinder、cephfs、flocker、downwardAPI、fc、azureFile、configMap、vsphereVolume等等,可以定义多个Volume,每个Volume的name保持唯一。在同一个pod中的多个容器能够共享pod级别的存储卷Volume。Volume可以定义为各种类型,多个容器各自进行挂载操作,讲一个Volume挂载为容器内需要的目录。

六、 sidecar容器与Init Container容器
- sidecar: 伴生容器,指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
- Init Container:初始化容器 就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行,只有所有的Init Container执行完后,主容器才会被启动。我们知道一个Pod里面的所有容器是共享数据卷和网络命名空间的,所以Init Container里面产生的数据可以被主容器使用到的。
例如:我们现在有一个 Java Web 应用的 WAR 包,它需要被放在 Tomcat 的 webapps 目录下运行起来。假如,你现在只能用 Docker 来做这件事情,那该如何处理这个组合关系呢?
- 一种方法是,把 WAR 包直接放在 Tomcat 镜像的 webapps 目录下,做成一个新的镜像运行起来。可是,这时候,如果你要更新 WAR 包的内容,或者要升级 Tomcat 镜像,就要重新制作一个新的发布镜像,非常麻烦。
- 另一种方法是,你压根儿不管 WAR 包,永远只发布一个 Tomcat 容器。不过,这个容器的 webapps 目录,就必须声明一个 hostPath 类型的 Volume,从而把宿主机上的 WAR 包挂载进 Tomcat 容器当中运行起来。不过,这样你就必须要解决一个问题,即:如何让每一台宿主机,都预先准备好这个存储有 WAR 包的目录呢?这样来看,你只能独立维护一套分布式存储系统了。
实际上,有了 Pod 之后,这样的问题就很容易解决了。我们可以把 WAR 包和 Tomcat 分别做成镜像,然后把它们作为一个 Pod 里的两个容器“组合”在一起。这个 Pod 的配置文件如下所示:
apiVersion: v1
kind: Pod
metadata:name: javaweb-2
spec:initContainers:- image: geektime/sample:v2name: warcommand: ["cp", "/sample.war", "/app"]volumeMounts:- mountPath: /appname: app-volumecontainers:- image: geektime/tomcat:7.0name: tomcatcommand: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]volumeMounts:- mountPath: /root/apache-tomcat-7.0.42-v2/webappsname: app-volumeports:- containerPort: 8080hostPort: 8001 volumes:- name: app-volumeemptyDir: {}在这个 Pod 中,我们定义了两个容器,第一个容器使用的镜像是geektime/sample:v2,这个镜像里只有一个 WAR 包(sample.war)放在根目录下。而第二个容器则使用的是一个标准的 Tomcat 镜像。不过,你可能已经注意到,WAR 包容器的类型不再是一个普通容器,而是一个 Init Container 类型的容器。在 Pod 中,所有 Init Container 定义的容器,都会比 spec.containers 定义的用户容器先启动。并且,Init Container 容器会按顺序逐一启动,而直到它们都启动并且退出了,用户容器才会启动。所以,这个 Init Container 类型的 WAR 包容器启动后,我执行了一句"cp /sample.war /app",把应用的 WAR 包拷贝到 /app 目录下,然后退出。而后这个 /app 目录,就挂载了一个名叫 app-volume 的 Volume。接下来就很关键了。Tomcat 容器,同样声明了挂载 app-volume 到自己的 webapps 目录下。所以,等 Tomcat 容器启动时,它的 webapps 目录下就一定会存在 sample.war 文件:这个文件正是 WAR 包容器启动时拷贝到这个 Volume 里面的,而这个 Volume 是被这两个容器共享的。像这样,我们就用一种“组合”方式,解决了 WAR 包与 Tomcat 容器之间耦合关系的问题。实际上,这个所谓的“组合”操作,正是容器设计模式里最常用的一种模式,它的名字叫:sidecar。
在我们的这个应用 Pod 中,Tomcat 容器是我们要使用的主容器,而 WAR 包容器的存在,只是为了给它提供一个 WAR 包而已。所以,我们用 Init Container初始化容器的方式优先运行 WAR 包容器,扮演了一个 sidecar 的角色。
七、Pod资源使用机制
我们前面提到过Pod好比一个虚拟机,虚拟机我们是能分配固定的CPU、Mem、Disk、网络资源的。同理,Pod也是如此,那么Pod如何使用和控制这些分配的资源呢?首先,我们先了解下CPU资源的分配模式:
计算机里CPU的资源是按“时间片”的方式分配给请求的,系统里的每一个操作都需要CPU的处理,我们知道CPU的单位是Hz、GHz(1Hz = 1/s,即在单位时间内完成振动的次数,1GHz = 1 000 000 000 Hz = 1 000 000 000 次/s),频率越大,单位时间内完成的处理次数就越多。所以,哪个任务要是申请的CPU时间片越多,那么它得到的CPU资源就越多。
其次,我们再了解一些Cgroup里资源的换算单位:
CPU换算单位
1 CPU = 1000 millicpu(1 Core = 1000m)
0.5 CPU = 500 millicpu (0.5 Core = 500m)
这里的 m 就是毫、毫核的意思,K8S集群中的每一个节点可以通过操作系统的命令来确认本节点的CPU内核数量,然后将这个数量乘以1000,得到的就是节点总CPU总毫数。比如一个节点有四核,那么该节点的CPU总毫量为4000m。如果你要使用0.5 core,则你要求的是 4000*0.5 = 2000m。
K8S里是通过以下两个参数来限制和请求CPU的资源的:
- spec.containers[].resources.limits.cpu CPU上限值,可以短暂超过,容器也不会被停止。
- spec.containers[].resources.requests.cpu CPU请求值,K8S调度算法里的依据值,可以超过。
这里需要明白的是,如果resources.requests.cpu设置的值大于集群里每个Node的最大CPU核心数,那么这个Pod将无法调度(很容易理解,没有Node能满足它)。
例子,我们在YAML里定义一个容器CPU资源如下:
resources:requests:memory: 50Micpu: 50mlimits:memory: 100Micpu: 100m这里,CPU我们给的是50m,也就是0.05core,这0.05 core也就是占了1 CPU里的5%的资源时间。另外,我们还要知道K8S CPU资源这块,它是一个可压缩性的资源。如果容器达到了CPU设定值会开始限制,容器性能会下降,但是不会终止和退出。
最后我们了解下MEM这块的资源控制:
单位换算:1 MiB = 1024 KiB , 这里注意的是MiB ≠ MB,MB是十进制单位,MiB 是二进制,平时我们以为MB等于1024KB,其实1MB=1000KB,1MiB才等于1024KiB。中间带字母 i 的是国际电工协会(IEC)定的,走1024乘积;KB、MB、GB是国际单位制,走1000乘积。
内存这块在K8S里一般用的是Mi单位,当然你也可以使用Ki、Gi甚至Pi,看具体的业务需求和资源容量。这里要注意的是,内存这里不是可压缩性资源,如果容器使用内存资源到达了上限,那么会OOM,造成内存溢出,容器就会终止和退出。
八、pod的生命周期管理
Pod在整个生命周期过程中被定义为各种状态,熟悉Pod的各种状态有助于理解如何设置Pod的调度策略、重启策略Pod的状态包含以下几种,如图:
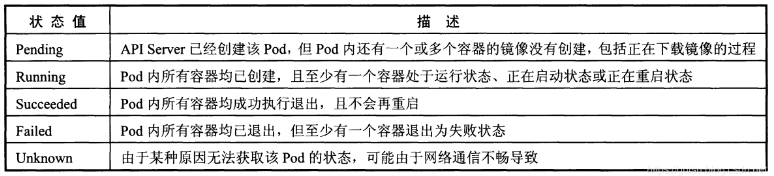
Pod的重启策略(RestartPolicy)应用于Pod内所有的容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某哥容器异常退出或者健康检查石柏师,kubelet将根据RestartPolicy的设置进行相应的操作。Pod的重启策略包括Always、OnFailure及Nerver,默认值为Always。kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5分钟,并且成功重启后的10分钟后重置该事件。
Pod的重启策略和控制方式息息相关,当前可用于管理Pod的控制器宝库ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod),每种控制器对Pod的重启策略要求如下:
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行
- Job:OnFailure或Nerver,确保容器执行完成后不再重启
- kubelet:在Pod失效时重启他,不论RestartPolicy设置什么值,并且也不会对Pod进行健康检查。
九、pod的健康检查
对Pod的健康检查可以通过两类探针来检查:LivenessProbe和ReadinessProbe
- LivenessProbe探针:用于判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,则kubelet杀掉该容器,并根据容器的重启策略做响应处理
- ReadinessProbe探针:用于判断容器是否启动完成(ready状态),可以接受请求。如果ReadinessProbe探针探测失败,则Pod的状态被修改。Endpoint Controller将从service的Endpoint中删除包含该容器所在的Pod的Endpoint。
kubelet定制执行LivenessProbe探针来诊断容器的健康状况。LivenessProbe有三种事项方式。
1)ExecAction:在容器内部执行一个命令,如果该命令的返回值为0,则表示容器健康。例:
apiVersion:v1
kind: Pod
metadata:name: liveness-execlabel:name: liveness
spec:containers:- name: tomcatimage: grc.io/google_containers/tomcatargs:-/bin/sh- -c-echo ok >/tmp.health;sleep10; rm -fr /tmp/health;sleep600livenessProbe:exec:command:-cat-/tmp/healthinitianDelaySeconds:15timeoutSeconds:1(2)TCPSocketAction:通过容器ip地址和端口号执行TCP检查,如果能够建立tcp连接表明容器健康。例:
kind: Pod
metadata:name: pod-with-healthcheck
spec:containers:- name: nginximage: nginxlivenessProbe:tcpSocket:port: 80initianDelaySeconds:30timeoutSeconds:13)HTTPGetAction:通过容器Ip地址、端口号及路径调用http get方法,如果响应的状态吗大于200且小于400,则认为容器健康。例:
apiVersion:v1
kind: Pod
metadata:name: pod-with-healthcheck
spec:containers:- name: nginximage: nginxlivenessProbe:httpGet:path:/_status/healthzport: 80initianDelaySeconds:30timeoutSeconds:1
对于每种探针方式,都需要设置initialDelaySeconds和timeoutSeconds两个参数,它们含义如下:
- initialDelaySeconds:启动容器后首次监控检查的等待时间,单位秒
- timeouSeconds:健康检查发送请求后等待响应的超时时间,单位秒。当发生超时就被认为容器无法提供服务无,该容器将被重启。
【参考文章】
1、参考文章1:https://cloud.tencent.com/developer/article/1443520
2.参考文章2:https://www.jianshu.com/p/d1e1de86d6d6








