您现在的位置是:主页 > news > 个人服务器 网站建设/手机优化大师下载
个人服务器 网站建设/手机优化大师下载
![]() admin2025/6/15 17:58:56【news】
admin2025/6/15 17:58:56【news】
简介个人服务器 网站建设,手机优化大师下载,郑州知名网站建设,南宁百度推广代理公司作者 | 萝卜来源 | 早起Python(ID: zaoqi-python)本文将基于不平衡数据,使用Python进行反欺诈模型数据分析实战,模拟分类预测模型中因变量分类出现不平衡时该如何解决,具体的案例应用场景除反欺诈外,还有客户违约和疾病检测等。只…
个人服务器 网站建设,手机优化大师下载,郑州知名网站建设,南宁百度推广代理公司作者 | 萝卜来源 | 早起Python(ID: zaoqi-python)本文将基于不平衡数据,使用Python进行反欺诈模型数据分析实战,模拟分类预测模型中因变量分类出现不平衡时该如何解决,具体的案例应用场景除反欺诈外,还有客户违约和疾病检测等。只…  作者 | 萝卜来源 | 早起Python(ID: zaoqi-python)本文将基于不平衡数据,使用Python进行反欺诈模型数据分析实战,模拟分类预测模型中因变量分类出现不平衡时该如何解决,具体的案例应用场景除反欺诈外,还有客户违约和疾病检测等。只要是因变量中各分类占比悬殊,就可对其使用一定的采样方法,以达到除模型调优外的精度提升。主要将分为两个部分:
作者 | 萝卜来源 | 早起Python(ID: zaoqi-python)本文将基于不平衡数据,使用Python进行反欺诈模型数据分析实战,模拟分类预测模型中因变量分类出现不平衡时该如何解决,具体的案例应用场景除反欺诈外,还有客户违约和疾病检测等。只要是因变量中各分类占比悬殊,就可对其使用一定的采样方法,以达到除模型调优外的精度提升。主要将分为两个部分:
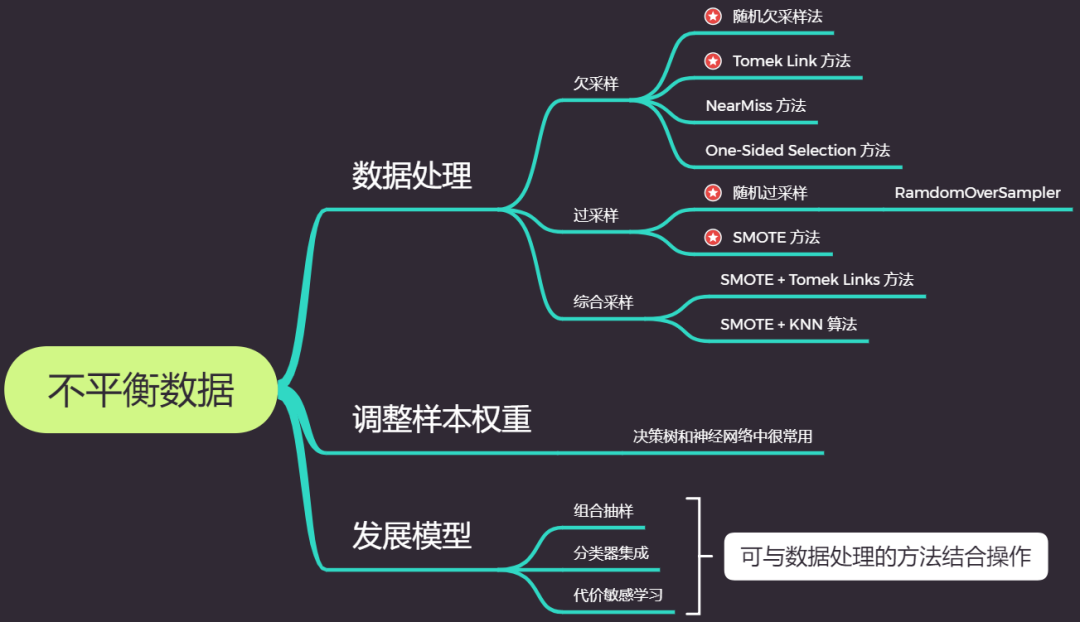
与其花大量的时间对建好的模型进行各种调优操作,不如在一开始就对源数据进行系统而严谨的处理。而数据处理背后的算法原理又常是理解代码的支撑。所以本节将详细介绍不平衡采样的多种方法。在以往的学习中,数据大多是 欠采样与过采样
欠采样与过采样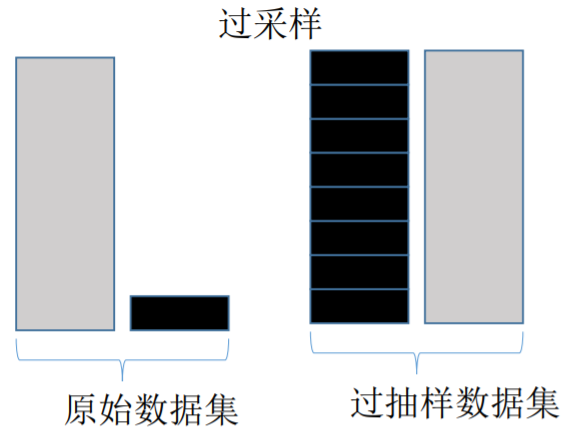
综合采样综合采样的核心:先使用过采样,扩大样本后再对处在胶着状态的点用 Tomek Link 法进行删除,有时候甚至连 Tomek Link 都不用,直接把离得近的对全部删除,因为在进行过采样后,0 和 1 的样本量已经达到了 1:1。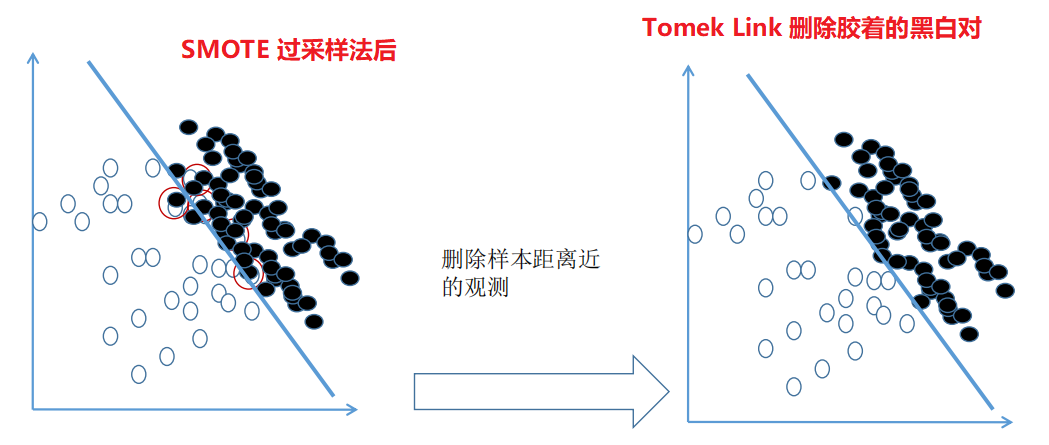





作者 | 萝卜来源 | 早起Python(ID: zaoqi-python)本文将基于不平衡数据,使用Python进行反欺诈模型数据分析实战,模拟分类预测模型中因变量分类出现不平衡时该如何解决,具体的案例应用场景除反欺诈外,还有客户违约和疾病检测等。只要是因变量中各分类占比悬殊,就可对其使用一定的采样方法,以达到除模型调优外的精度提升。主要将分为两个部分:原理介绍
Python实战
 原理介绍
原理介绍
与其花大量的时间对建好的模型进行各种调优操作,不如在一开始就对源数据进行系统而严谨的处理。而数据处理背后的算法原理又常是理解代码的支撑。所以本节将详细介绍不平衡采样的多种方法。在以往的学习中,数据大多是对称分布的,就像下图一样,即正负样本的数量相当。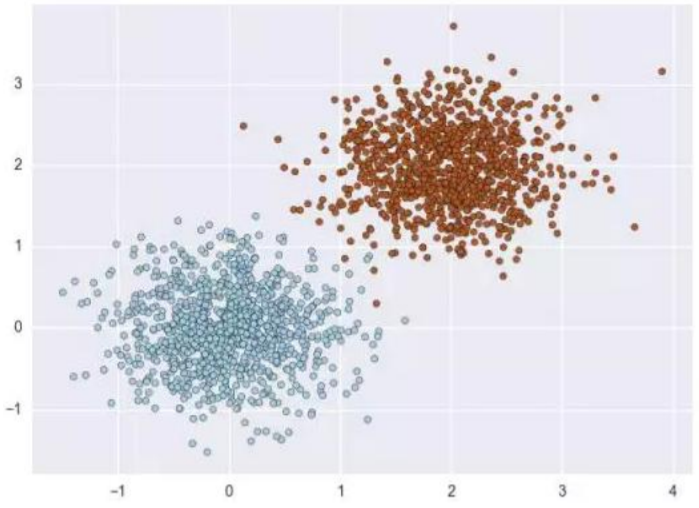
- 评估指标:使用精确度(Precise Rate)、召回率(Recall Rate)、Fmeasure或ROC曲线、准确度召回曲线(precision-recall curve);不要使用准确度(Accurate Rate)
- 不要使用模型给出的标签,而是要概率估计;得到概率估计之后,不要盲目地使用0.50的决策阀值来区分类别,应该再检查表现曲线之后再自己决定使用哪个阈值。
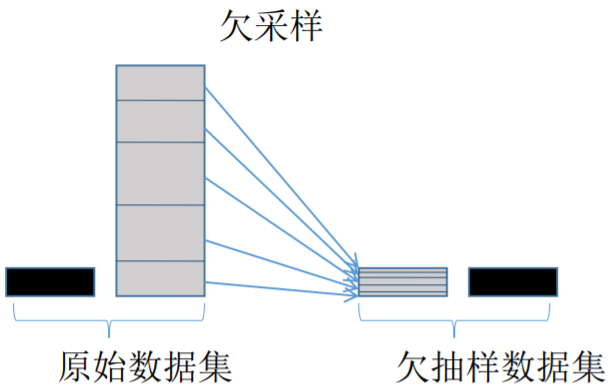
欠采样与过采样Tomek Link 法欠采样
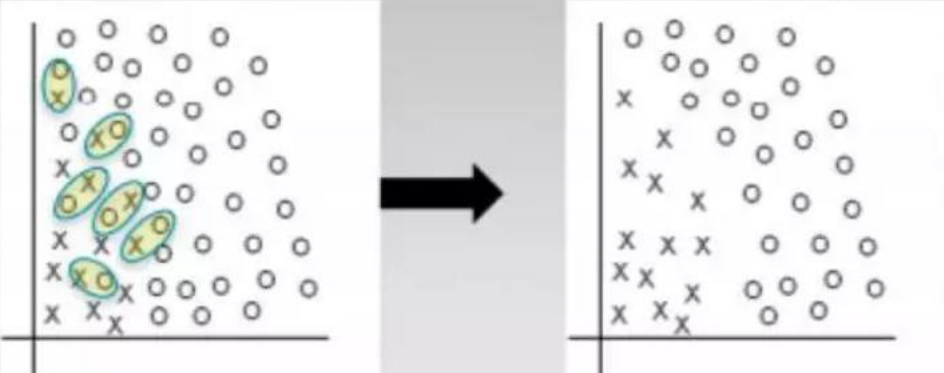
Random Over Sampling 随机过采样
随机过采样并不是将原始数据集中占比少的类简单的乘个指定的倍数,而是对较少类按一定比例进行一定次数的随机抽样,然后将每次随机抽样所得到的数据集叠加。但如果只是简单的随机抽样也难免会出现问题,因为任意两次的随机抽样中,可能会有重复被抽到的数据,所以经过多次随机抽样后叠加在一起的数据中可能会有不少的重复值,这便会使数据的变异程度减小。所以这是随机过采样的弊端。SMOTE 过采样
SMOTE 过采样法的出现正好弥补了随机过采样的不足,其核心步骤如下图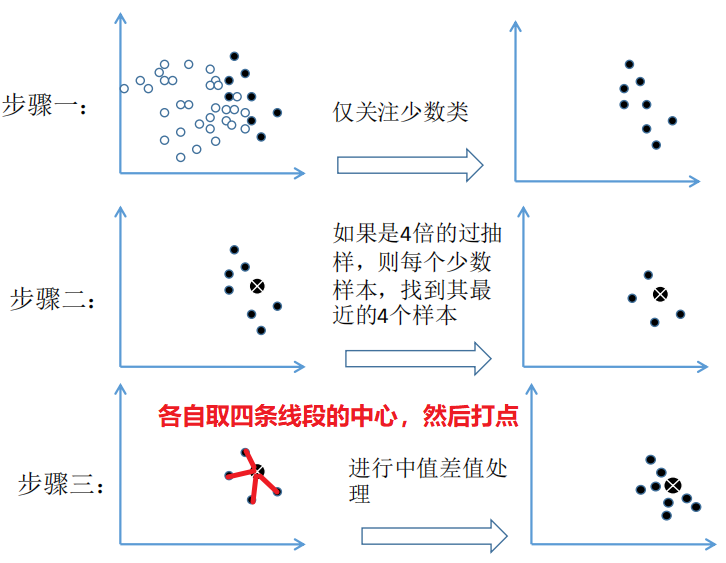
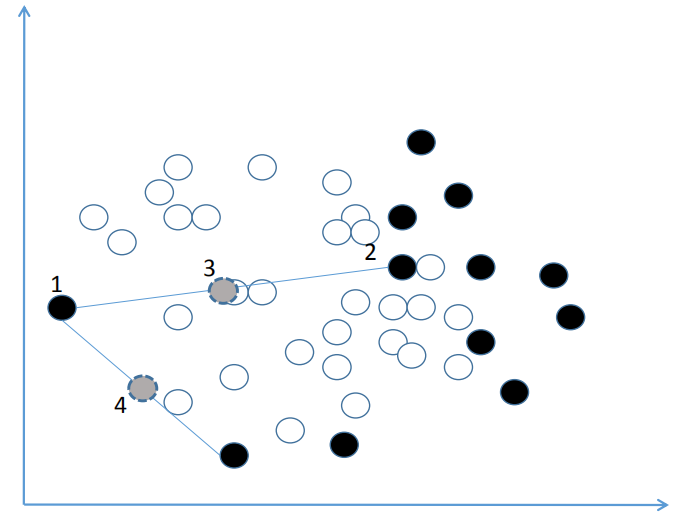

Python实战
数据探索
首先导入相关包import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snstrain = pd.read_csv('imb_train.csv')
test = pd.read_csv('imb_test.csv')
print(f'训练集数据长度:{len(train)},测试集数据长度:{len(test)}')
train.sample(3)- X1 ~ X5:自变量,
- cls:因变量 care life of science - 科学关爱生命 0-不得病,1-得病
print('训练集中,因变量 cls 分类情况:')
print(train['cls'].agg(['value_counts']).T)
print('='*55 + '\n')
print('测试集中,因变量 cls 分类情况:')
print(test['cls'].agg(['value_counts']).T)
from collections import Counter
print('训练集中因变量 cls 分类情况:{}'.format(Counter(train['cls'])))
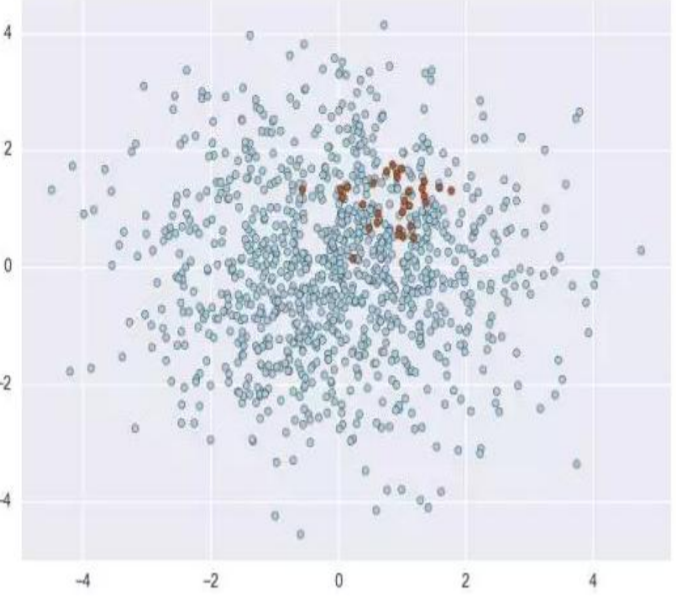
print('测试集因变量 cls 分类情况:{}'.format(Counter(test['cls'])))#训练集中因变量 cls 分类情况:Counter({0: 13644, 1: 356})#测试集因变量 cls 分类情况:Counter({0: 5848, 1: 152})不同的抽样方法对训练集进行处理
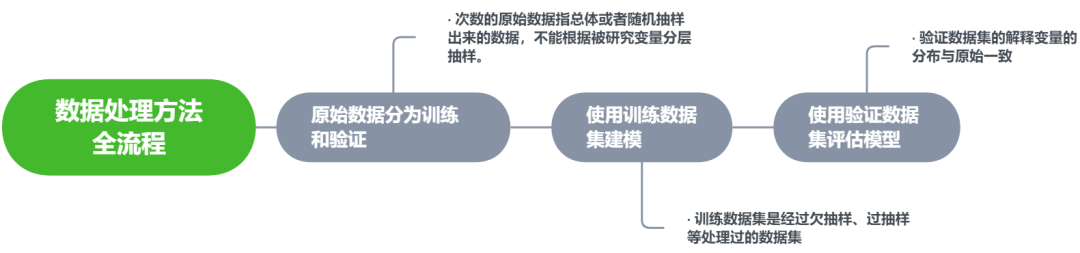
在处理前再次重申两点:- 测试集不做任何处理!保留严峻的比例考验来测试模型。
- 训练模型时用到的数据才是经过处理的,0-1 比例在 1:1 ~ 1:10 之间拆分自变量与因变量
拆分自变量与因变量
y_train = train['cls']; y_test = test['cls']
X_train = train.loc[:, :'X5']; X_test = test.loc[:, :'X5']
X_train.sample(), y_train[:1] #( X1 X2 X3 X4 X5# 9382 -1.191287 1.363136 -0.705131 -1.24394 -0.520264, 0 0# Name: cls, dtype: int64)抽样的几种方法
- Random Over Sampling:随机过抽样
- SMOTE 方法过抽样
- SMOTETomek 综合抽样
pip install imblearn安装一下即可,下面是不同抽样方法的核心代码,具体如何使用请看注释from imblearn.over_sampling import RandomOverSamplerprint('不经过任何采样处理的原始 y_train 中的分类情况:{}'.format(Counter(y_train)))# 采样策略 sampling_strategy = 'auto' 的 auto 默认抽成 1:1,## 如果想要另外的比例如杰克所说的 1:5,甚至底线 1:10,需要根据文档自行调整参数## 文档:https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.RandomOverSampler.html# 先定义好好,未开始正式训练拟合
ros = RandomOverSampler(random_state=0, sampling_strategy='auto')
X_ros, y_ros = ros.fit_sample(X_train, y_train)print('随机过采样后,训练集 y_ros 中的分类情况:{}'.format(Counter(y_ros)))# 同理,SMOTE 的步骤也是如此
from imblearn.over_sampling import SMOTE
sos = SMOTE(random_state=0)
X_sos, y_sos = sos.fit_sample(X_train, y_train)print('SMOTE过采样后,训练集 y_sos 中的分类情况:{}'.format(Counter(y_sos)))# 同理,综合采样(先过采样再欠采样)## # combine 表示组合抽样,所以 SMOTE 与 Tomek 这两个英文单词写在了一起
from imblearn.combine import SMOTETomek
kos = SMOTETomek(random_state=0) # 综合采样
X_kos, y_kos = kos.fit_sample(X_train, y_train)print('综合采样后,训练集 y_kos 中的分类情况:{}'.format(Counter(y_kos)))

决策树建模
看似高大上的梯度优化其实也被业内称为硬调优,即每个模型参数都给几个潜在值,而后让模型将其自由组合,根据模型精度结果记录并输出最佳组合,以用于测试集的验证。首先导入相关包from sklearn.tree import DecisionTreeClassifierfrom sklearn import metricsfrom sklearn.model_selection import GridSearchCVclf = DecisionTreeClassifier(criterion='gini', random_state=1234)# 梯度优化
param_grid = {'max_depth':[3, 4, 5, 6], 'max_leaf_nodes':[4, 6, 8, 10, 12]}# cv 表示是创建一个类,还并没有开始训练模型
cv = GridSearchCV(clf, param_grid=param_grid, scoring='f1')ros为随机过采样,第三组sos为SMOTE过采样,最后一组kos则为综合采样data = [[X_train, y_train],
[X_ros, y_ros],
[X_sos, y_sos],
[X_kos, y_kos]]recall和precision的用处都不大,看auc即可,recall:覆盖率,预测出分类为0且正确的,但本来数据集中分类为0的占比本来就很大。而且recall是以阈值为 0.5 来计算的,那我们就可以简单的认为预测的欺诈概率大于0.5就算欺诈了吗?还是说如果他的潜在欺诈概率只要超过 20% 就已经算为欺诈了呢?for features, labels in data:
cv.fit(features, labels) # 对四组数据分别做模型# 注意:X_test 是从来没被动过的,回应了理论知识:## 使用比例优良的(1:1~1:10)训练集来训练模型,用残酷的(分类为1的仅有2%)测试集来考验模型
predict_test = cv.predict(X_test) print('auc:%.3f' %metrics.roc_auc_score(y_test, predict_test), 'recall:%.3f' %metrics.recall_score(y_test, predict_test),'precision:%.3f' %metrics.precision_score(y_test, predict_test))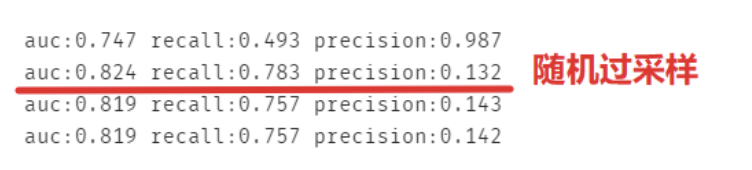
推荐阅读空间-角度信息交互用于光场图像超分辨重构,性能达到最新SOTA | ECCV 2020
阿里巴巴副总裁司罗:达摩院如何搭建NLP技术体系?
Python 爬取 13966 条运维招聘信息,这些岗位最吃香
Python 编程语言的核心是什么?
Python轻松搞定Excel中的20个常用操作
2020 活久见:欧美主流 app「熔断」了
赠书 | DeFi沉思录:历史、中国与未来
你点的每个“在看”,我都认真当成了AI







