您现在的位置是:主页 > news > 联科三网合一网站建设系统/谷歌优化排名怎么做
联科三网合一网站建设系统/谷歌优化排名怎么做
![]() admin2025/6/13 17:49:39【news】
admin2025/6/13 17:49:39【news】
简介联科三网合一网站建设系统,谷歌优化排名怎么做,传奇合成版2合1雷霆版手游,网站普查建设背景一、相关模型学习 ResNet学习 (1)模型层数越深,效果越好吗? 很明显当前CNN面临的效果退化不是因为过拟合,因为过拟合的现象是"高方差,低偏差",即测试误差大而训练误差小。但实际上&…
一、相关模型学习
ResNet学习
(1)模型层数越深,效果越好吗?
很明显当前CNN面临的效果退化不是因为过拟合,因为过拟合的现象是"高方差,低偏差",即测试误差大而训练误差小。但实际上,深层CNN的训练误差和测试误差都很大。
(2)梯度爆炸、梯度消失
假设模型输入是x,y,z,对应的参数分别是w1,w2,w3,模型是F,F(x,y,z)是输出output,易知output对模型参数w的梯度均与输入x,y,z的值有关。当计算图每次输入的模长为大于1的数时,经过网络中多次的回传,梯度不可避免地呈现指数级的增长,直到NAN,这就是梯度爆炸;反过来,如果计算图每次输入的模长为小于1的数时,经过网络中多次的回传,梯度不可避免地呈现指数级的下降,直到0,这就是梯度消失。
我们现在无论用Pytorch还是Tensorflow,都会自然而然地加上Bacth Normalization(简称BN),而BN的作用本质上也是控制每层输入的模值,因此梯度的爆炸/消失现象理应在很早就被解决了(至少解决了大半)。
模型越深效果越不好,既不是因为过拟合也不是因为梯度爆炸和梯度消失,那是什么原因导致的呢?
(3)模型退化
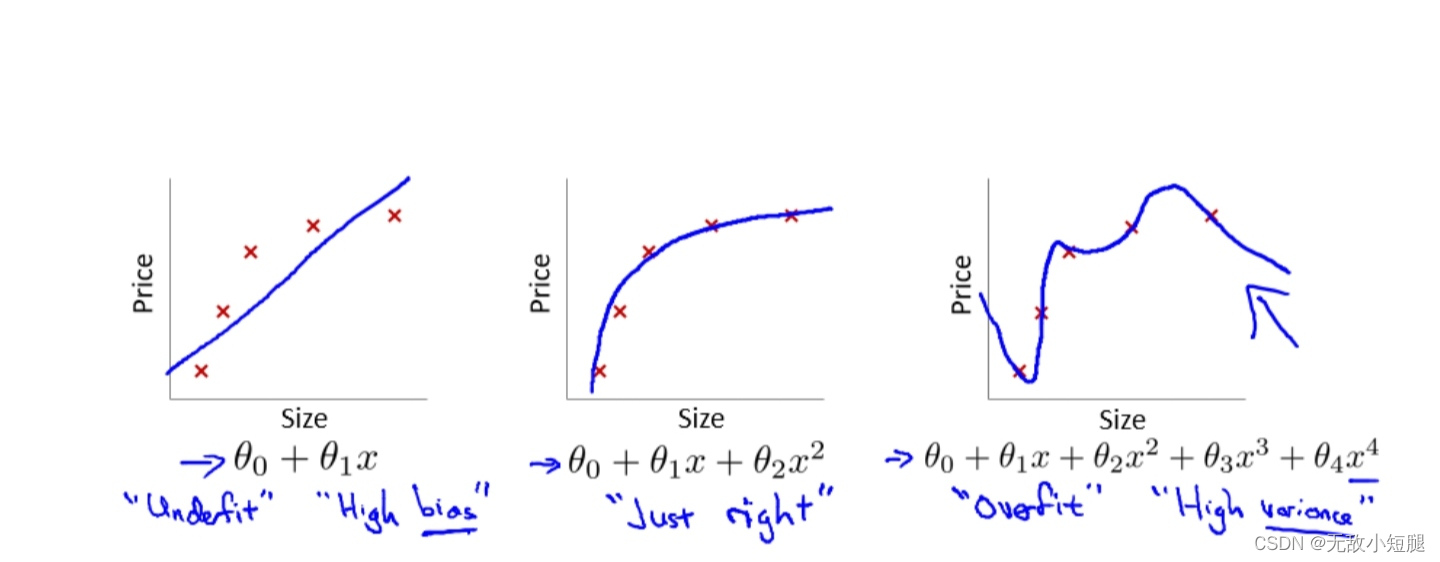
也许会认为如果一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。“什么都不做”恰好是当前神经网络最难做到的东西之一。由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的(信息损失)。我们很难从输出反推回完整的输入。
点的话说,这种神经网络丢失的“不忘初心”什么都不做”的品质叫做恒等映射。因此,可以认为Residual Learning的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
(4)Residual 模块
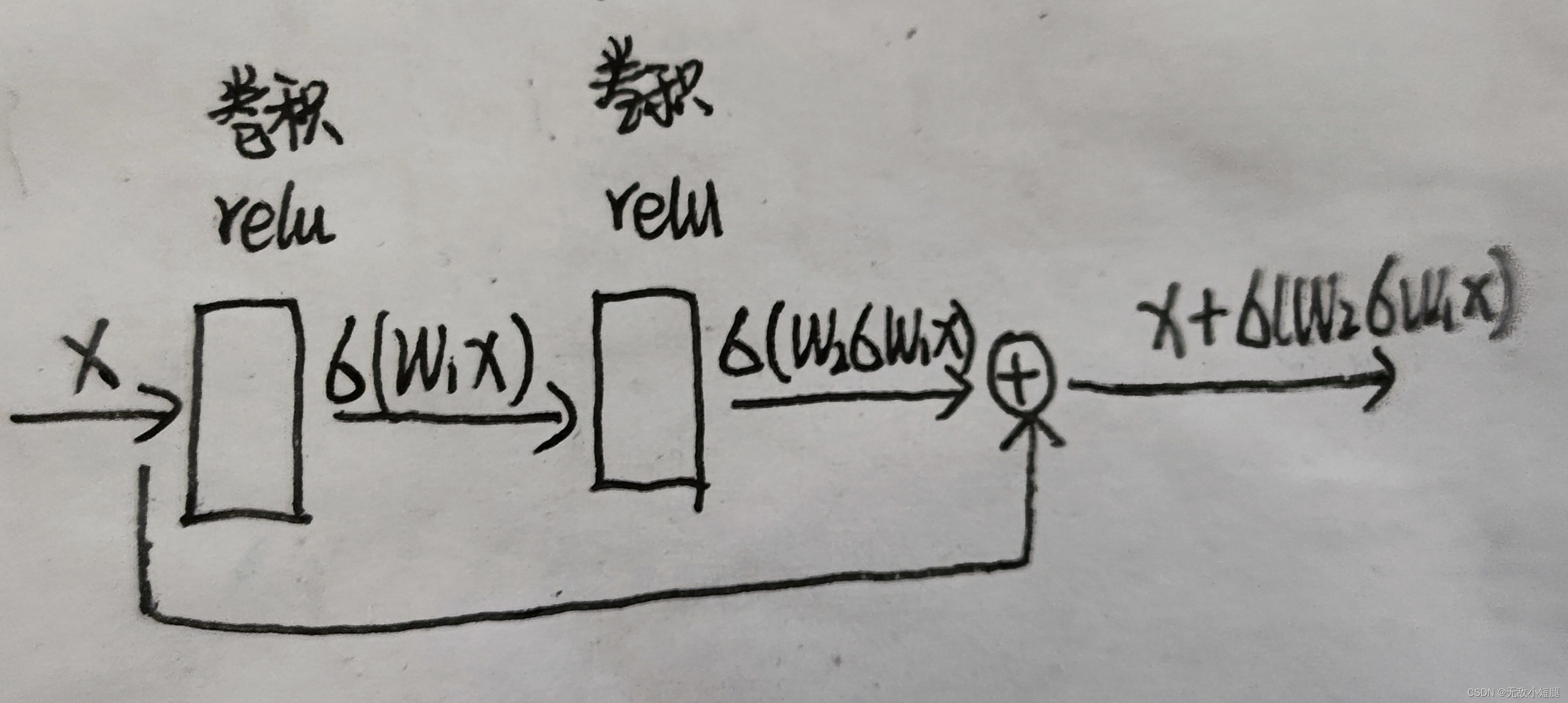
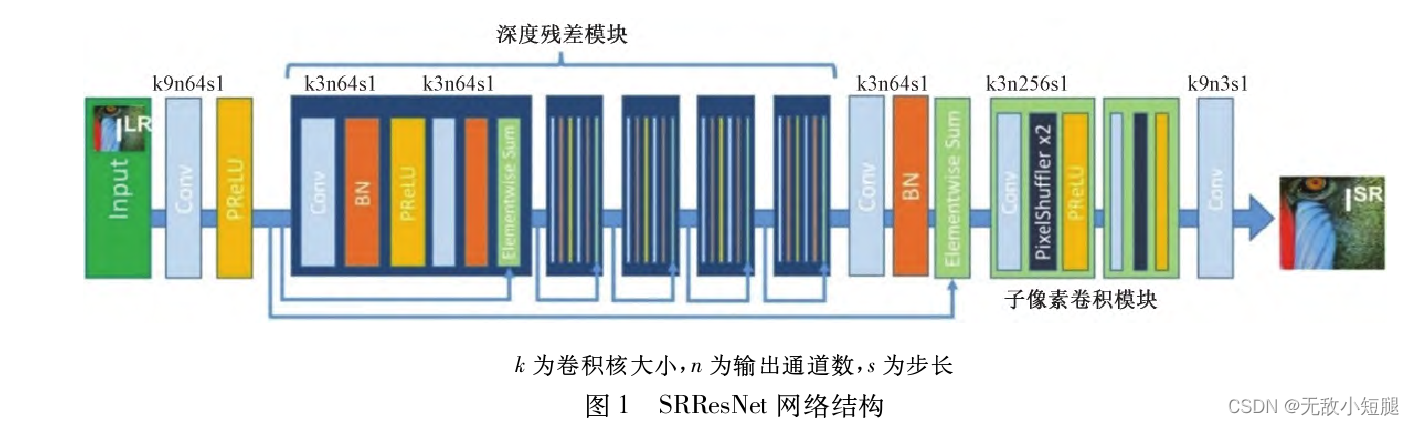
SRResNet网络重建


将图片随机裁剪出(96 x 96)的大小并作为高像素图像,然后再通过最大池化的方式将其下采样为(24 x 24)作为低像素图像。
SRGan网络重建
3.基于注意力机制重建
二、相关论文重要片段
1.远距离侧面人脸的重建及其识别研究_管俊

2.基于改进SRResNet深...低照度图像超分辨率重建方法_卢冰


二、远距离低分辨率图像重建
1.SRResnet重建低分辨率图像
(1)网络模型
参数 scaling_factor: 放大比例为2、4、8








