您现在的位置是:主页 > news > 太平洋保险网站做的这么烂/企业软文营销
太平洋保险网站做的这么烂/企业软文营销
![]() admin2025/6/10 0:12:57【news】
admin2025/6/10 0:12:57【news】
简介太平洋保险网站做的这么烂,企业软文营销,做收款二维码的网站,群晖 wordpress加载慢基数排序(桶排序)基数排序(桶排序)介绍:1) 基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或 bin sort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中ÿ…
基数排序(桶排序)
基数排序(桶排序)介绍:
1) 基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或 bin sort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用
2) 基数排序法是属于稳定性的排序,基数排序法的是效率高的 稳定性排序法
3) 基数排序(Radix Sort)是桶排序的扩展
4) 基数排序是 1887 年赫尔曼·何乐礼发明的。它是这样实现的:将整数按位数切割成不同的数字,然后按每个位数分别比较。
基数排序基本思想:
1) 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
2) 这样说明,比较难理解,下面我们看一个图文解释,理解基数排序的步骤
基数排序图文说明:
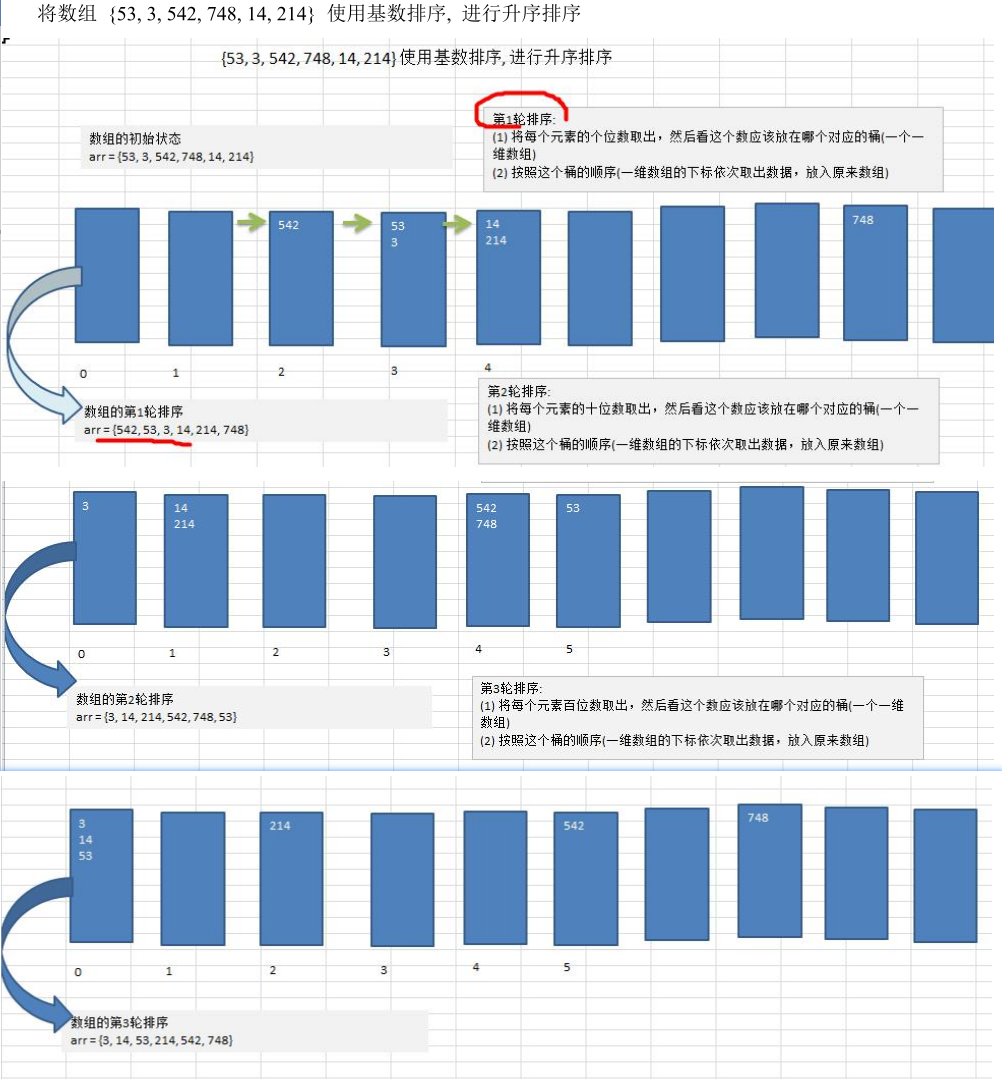
代码实现:
public class BubbleSort {
public static void main(String[] args) {
// int arr[] = {3, 9, -1, 10, 20};
//
// System.out.println("排序前");
// System.out.println(Arrays.toString(arr));
//为了容量理解,我们把冒泡排序的演变过程,给大家展示
//测试一下冒泡排序的速度 O(n^2), 给 80000 个数据,测试
//创建要给 80000 个的随机的数组
int[] arr = new int[80000000];
for (int i = 0; i < 80000000; i++) {
//生成一个[0, 8000000) 数
arr[i] = (int) (Math.random() * 80000000);
}
long millis1 = System.currentTimeMillis();
System.out.println("排序前的时间是=" + millis1);
//测试冒泡排序
// bubbleSort(arr);
// selectSort(arr);
// insertSort(arr);
// shellSort2(arr);
// quickSort(arr, 0, arr.length - 1);
// int temp[] = new int[arr.length]; //归并排序需要一个额外空间
// mergeSort(arr, 0, arr.length - 1, temp);
radixSort(arr);
long millis2 = System.currentTimeMillis();
System.out.printf("排序后的时间是=%s", millis2 - millis1);
System.out.println();
System.out.println(arr.length);
for (int i = 0; i < 100; i++) {
int index = (int) (Math.random() * 8000000);
System.out.println(arr[index]);
}
// System.out.println(Arrays.toString(arr));
}
//基数排序方法
public static void radixSort(int[] arr) {
//根据前面的推导过程,我们可以得到最终的基数排序代码
//1. 得到数组中最大的数的位数
int max = arr[0]; //假设第一数就是最大数
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
//得到最大数是几位数
int maxLength = (max + "").length();
//定义一个二维数组,表示 10 个桶, 每个桶就是一个一维数组
//说明
//1. 二维数组包含 10 个一维数组
//2. 为了防止在放入数的时候,数据溢出,则每个一维数组(桶),大小定为 arr.length
//3. 名明确,基数排序是使用空间换时间的经典算法
int[][] bucket = new int[10][arr.length];
//为了记录每个桶中,实际存放了多少个数据,我们定义一个一维数组来记录各个桶的每次放入的数据个数
//可以这里理解
//比如:bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数
int[] bucketElementCounts = new int[10];
//这里我们使用循环将代码处理
for (int i = 0, n = 1; i < maxLength; i++, n *= 10) {
//(针对每个元素的对应位进行排序处理), 第一次是个位,第二次是十位,第三次是百位..
for (int j = 0; j < arr.length; j++) {
//取出每个元素的对应位的值
int digitOfElement = arr[j] / n % 10;
//放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
int index = 0;
//遍历每一桶,并将桶中是数据,放入到原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
//如果桶中,有数据,我们才放入到原数组
if (bucketElementCounts[k] != 0) {
//循环该桶即第 k 个桶(即第 k 个一维数组), 放入
for (int l = 0; l < bucketElementCounts[k]; l++) {
//取出元素放入到 arr
arr[index++] = bucket[k][l];
}
}
//第 i+1 轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!!
bucketElementCounts[k] = 0;
}
}
}
}
运行结果:
80000000条数据:
排序前的时间是=1587821370890
排序后的时间是=4412
80000000
8000000条数据:
排序前的时间是=1587821857635
排序后的时间是=458
8000000
基数排序的说明:
1) 基数排序是对传统桶排序的扩展,速度很快.
2) 基数排序是经典的空间换时间的方式,占用内存很大, 当对海量数据排序时,容易造成 OutOfMemoryError 。
3) 基数排序时稳定的。[注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些
记录的相对次序保持不变,即在原序列中,r[i]=r[j],且 r[i]在 r[j]之前,而在排序后的序列中,r[i]仍在 r[j]之前,
则称这种排序算法是稳定的;否则称为不稳定的]
4) 有负数的数组,我们不用基数排序来进行排序, 如果要支持负数,参考: https://code.i-harness.com/zh-CN/q/e98fa9
常用排序算法总结和对比
一张排序算法的比较图:
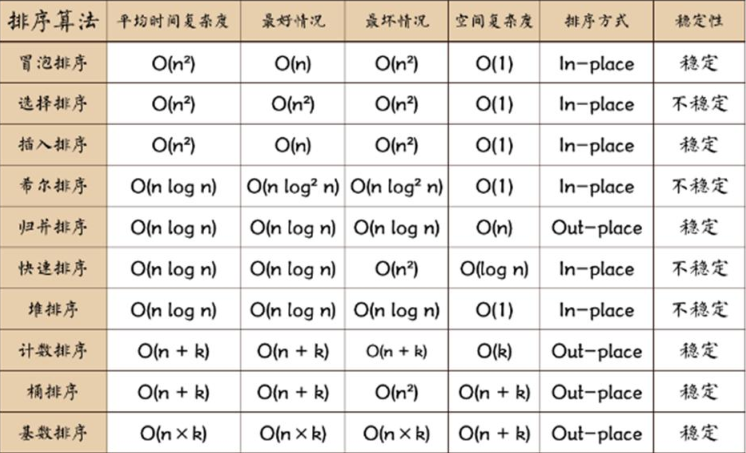
相关术语解释:
1) 稳定:如果 a 原本在 b 前面,而 a=b,排序之后 a 仍然在 b 的前面;
2) 不稳定:如果 a 原本在 b 的前面,而 a=b,排序之后 a 可能会出现在 b 的后面;
3) 内排序:所有排序操作都在内存中完成;
4) 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
5) 时间复杂度: 一个算法执行所耗费的时间。
6) 空间复杂度:运行完一个程序所需内存的大小。
7) n: 数据规模
8) k: “桶”的个数
9) In-place: 不占用额外内存
10) Out-place: 占用额外内存








