您现在的位置是:主页 > news > 做短视频网站好/百度应用商店下载安装
做短视频网站好/百度应用商店下载安装
![]() admin2025/6/9 20:45:19【news】
admin2025/6/9 20:45:19【news】
简介做短视频网站好,百度应用商店下载安装,有经验的江苏网站建设,上辽宁建设工程信息网站今天在看HashMap的源码时,其hash算法使用了无符号右移16位的操作,好奇Java内存中到底是怎么存放这些数字的。虽然以前知道,计算机都是使用补码的形式存放的整数值,但我都没深究过内存中的字节。今天查查资料,把自己所学…
今天在看HashMap的源码时,其hash算法使用了无符号右移16位的操作,好奇Java内存中到底是怎么存放这些数字的。虽然以前知道,计算机都是使用补码的形式存放的整数值,但我都没深究过内存中的字节。今天查查资料,把自己所学的记录在此。
java中基本整型的长度
java中基本整型的长度如下图:
byte:8位,short:16位,int:32位,long:64位
而计算机中,程序员用得最多的是十进制和十六进制,十进制符合人的计算习惯,而二进制因为0101太长看起来不方便,将机器内的二进制转为十六进制方便人查看。
Java也提供了这两种进制的字面量,不写任何前缀如int i = 10;即代表该整型i是赋值十进制的10,而int i = 0x10;则表示i赋值的是十六进制的10,即十进制的16。System.out.println(i);默认以十进制打印出i,而System.out.printf("%x",i);则是以16进制打印i。
但值得注意的是0x10这个字面量是以int类型的,如0xff表示的是int类型的255,如果将其赋值给byte类型byte b = 0xff,编译器会报错,因为byte最大为127。这样的话,难道我就不能为一个byte赋值为全1吗?可以的,但是需要借由int来强制转换,如下:
int i = 0x00_00_00_ff; // JDK1.7之后可以使用下划线来分割整型字面量,便于阅读
byte b = (byte) i; // int类型强制转化为byte,会取最右边八位,即ff
复制代码
内存中存储的是补码
我们知道,计算机在内存中存储的都是整数的补码,空口无凭,那怎么来验证一下呢?程序如下,将int位-1的每一个字节都以十六进制打印出来,确实是补码:0xff_ff_ff_ff
@Test
public void test(){
int i = -1;
byte[] bs = new byte[4];
bs[0] = (byte)(i >>> 24);
bs[1] = (byte)(i >>> 16);
bs[2] = (byte)(i >>> 8);
bs[3] = (byte) i;
for(byte b : bs){
System.out.printf("%x ", b);
}
}
复制代码
结果如下:
反向验证一下,将byte设置为0xff,看打印是否为-1。
@Test
public void test(){
int i = 0x01_23_45_ff;
byte b = (byte) i;
System.out.printf("%d", b);
}
复制代码
得证,结果如下:
一切皆0101
计算机中所有的东西都是0101,那么,现在我想用这些0101来组装一个句子“我喜欢你",打印出来可以吗?答案是,当然没问题,只要你知道这些文字的编码即可。上网查找到,“我喜欢你”这几个字的utf8编码是:\xE6\x88\x91\xE5\x96\x9C\xE6\xAC\xA2\xE4\xBD\xA0(\x表示十六进制),那可以使用byte[]数组来构建字符串了,如下:
@Test
public void test() throws UnsupportedEncodingException{
byte[] bs = {(byte)0xe6, (byte)0x88, (byte)0x91,
(byte)0xe5, (byte)0x96, (byte)0x9c,
(byte)0xe6, (byte)0xac, (byte)0xa2,
(byte)0xe4, (byte)0xbd, (byte)0xa0};
String s = new String(bs, "utf8");
System.out.printf("%s", s);
}
复制代码
结果如下:
当然,搜索unicode编码或其他编码,然后以该编码解码形成String字符串也可。
既然反向能形成字符串,正向也能从字符串获取到编码值,如下,将“我喜欢你”编码为unicode编码:
@Test
public void test() throws UnsupportedEncodingException{
String s = "我喜欢你";
byte[] bs = s.getBytes("unicode");
for(byte b : bs){
System.out.printf("%x ", b);
}
}
复制代码
结果如下,fe ff是unicode头,其余每2字节代表一个中文。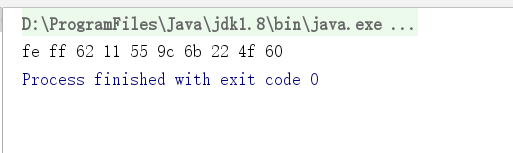
Java字节序endian
写完之后发现遗漏了Java字节序相关的,等下班再补补。其实字节序很简单,就是超过一个字节时,字节在内存中是按什么顺序放置的。像int是四个字节,那么如果存放一个0x12_34_56_78,是在内存地址中按顺序12345678存放还是其他存放方式。这就是字节序。
以上。








