您现在的位置是:主页 > news > 网站开发和移动开发/视频剪辑培训班
网站开发和移动开发/视频剪辑培训班
![]() admin2025/6/8 11:50:13【news】
admin2025/6/8 11:50:13【news】
简介网站开发和移动开发,视频剪辑培训班,多语言网站如何做,建设银行给税对账在什么网站目录 前情提要 Transformers对比 TransformerXL改进 Recurrence Mechanism Relative Position Embedding Caculation Method的改进 综合代码实现 前情提要 原文链接:MTFramework、TransformerXL 第二篇文章让我认识到我自己在Deep Learning的research doma…
目录
前情提要
Transformers对比
TransformerXL改进
Recurrence Mechanism
Relative Position Embedding
Caculation Method的改进
综合代码实现
前情提要
原文链接:MTFramework、TransformerXL
第二篇文章让我认识到我自己在Deep Learning的research domain中懂的真的是太少太少了,例如论文中使用的TransformerXL和Graph embedding根本就不了解是怎么回事,心态爆炸,可还能怎么办呢,已经入坑了,不懂就追根溯源的看吧,Graph Embedding暂时还不懂,后面再单独补上一章(当然你可以直接理解为把图embedding为一个向量就行,具体怎么embedding当成黑盒子)。
Transformers对比
先来看一下TransformerXL,淦!这玩意是Vanilla Transformer的改进(注意不是Transformer!这玩意也是Transformer的一个改进)。Transformer不详述了,具体可见:Transformer详解。那Vanilla Transformer是什么东西呢,简单的说就是用于处理长序列输入问题的。
- Transformer:最原始,用Self Attention机制吊打一众RNNs系列的Model。
- Vanilla Transformer:发现Transformer只能处理定长的问题,不能够解决长序列输入问题,举个栗子!Transformer可以解决机器翻译问题,设定一个max_length,不足的地方使用padding补齐,但是万一你输入的是一个超级长的article,导致你计算机内存爆炸了咋办(注意你的计算机内存是有限的)。所以他提出了一个新的方法,使用segment,就是把这个超长的输入split成几个小块,如下图所示(中间没有标识的你把它当作一个encoder和decoder共同组成的hidden layer)。即
,每一个segment之间没有信息传递。这么做显然有个坏处,x4的output只和segement内部的x有关,直接忽略了segment以外的x信息,而且fixed length的windows也会导致切分的句子不完整(比如你在某个句子中间截断),也就是context fragmentation的问题。其次,这个Model在Evaluation的时候只根据最后一个hidden state来generate数据(通常情况下认为最后一个hidden state具有前面segment的所有信息),每次开一个segment就从头train from scrach,这成本谁能顶得住啊。


- TransformerXL:这个就是作者提出的Model,他做了三个创新,如果不想看细节,把这个看完就可以结束。第一,Recurrence Mechanism,缓存上一个segment的hidden layer和当前hidden layer进行concat以汲取更长的信息。第二,相对位置编码,这是对Transformer中绝对位置编码的一个改进,这个改进是针对segment split的特性所必须的。第三,改进了部分计算方式以加快速度。
TransformerXL改进
Recurrence Mechanism

乍一看和Vanilla Transformer很像,但不一样,它接受2个输入,以途中红框的hidden units为例,,不但吸收了当前segment的部分输入(grey line),同样接受了前一个segment的输入(green line),而我们又知道hidden units是可以保存前文的信息的,这样递归下去就等于汲取了更长的信息。原文中计算公式如下:
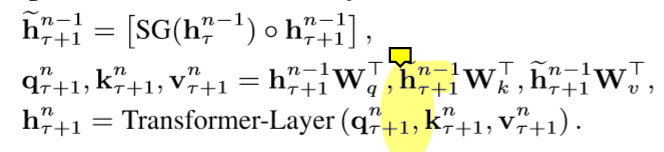
第一个公式表示缓存在内存中的hidden layer的参数是由上一个hidden layer与当前hidden layer进行concat得到的。第二个公式表示q、k、v的计算,尤其注意k和v的计算,是由cache的hidden layer进行直接计算。第三个公式就是传统的Transformer计算,不再赘述。
这里XL相对于Vanilla的提升在于,每次后者只能前进一个step(也就是一个点,为了汲取最长历史信息),而前者可以直接前进一个segment,并利用之前segment的数据来预测当前段的输出,如下图所示。

Relative Position Embedding
Transformer中使用的位置编码如果在这种segment split的方法中使用会出现一个问题,每个segment相同位置的编码是一样的,比如下面标红的两个位置,但很明显这两个东西对于最终的output(蓝色)的位置影响是不同的。

论文根据Transformer的公式(下面的公式2)分解提出了自己新的公式(下面的公式3),这个公式1怎么来的还记得吗,其实是Scale dot attention,做q、k、v转换之前会在Embedding x上加上位置编码U,然后再根据q和k计算Self Attention(下面的公式1)。作者首先在b和d中将j(也就是历史信息<t)的部分的绝对位置编码替换成相对位置编码(这个也是用个公式计算出来的,不需要训练)。其次,由于在考虑相对位置的时候并不需要知道q的绝对位置信息,所以使用u,v两个可训练参数替代前面需要计算的部分。最后,作者将k的权重矩阵拆分为K-E,基于内容的向量,以及K-R基于位置的向量。作者给了四部分定义为几个解释如下:
a. 基于内容的“寻址”,即没有添加原始位置编码的原始分数。
b. 基于内容的位置偏置,即previous相对于当前内容的位置偏差。
c. 全局的内容偏置,用于衡量key的重要性。
d. 全局的位置偏置,根据query和key之间的距离调整重要性。
![]()

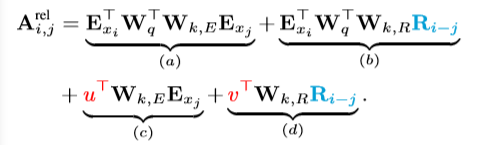
到此为止,作者的前面两个显式的创新讲完了,作者就把最终的q、k、v计算方法和attention计算方法的公式列出来了,这里(每一层hidden layer只考虑single head的情况)。如下所示(注意hidden layer的层值都是x的embedding):

代码实现
class PositionalEmbedding(nn.Module):
'''这一块比较小,单独拿出来看'''def __init__(self, demb):# demb就是相对位置编码的维度super(PositionalEmbedding, self).__init__()self.demb = dembinv_freq = 1 / (10000 ** (torch.arange(0.0, demb, 2.0) / demb))def forward(self, pos_seq):# 这里的pos_seq就是mlen+qlen,这就是query的长度,#这个公式就和Transform的公式来的一样迷sinusoid_inp = torch.ger(pos_seq, self.inv_freq)pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1)return pos_emb[:,None,:]
Caculation Method的改进
改进一
在上述A计算的时候大家不知道有没有发现,如果对所有的i-j计算的话,计算复杂度是平方级别,很显然嘛,两个for循环才行,但这个i-j范围是,而且R的公式是死的,我们可以直接计算好这个R,然后计算的时候提取出来用就行了,即:
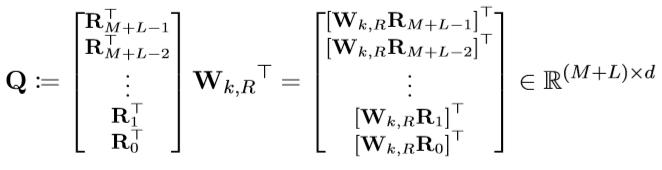
注意,这个M是缓存在cache中以往的hidden layer(这里我们不再假设只存了一个segmentd的hidden layer,因为我可以看更多的segment保证我看到足够长的历史信息)。
改进二
对于Attention计算的b部分,我们展开看一下:

我们定义一个矩阵,(讲真,这作者什么脑回路,是怎么想到的),如下:
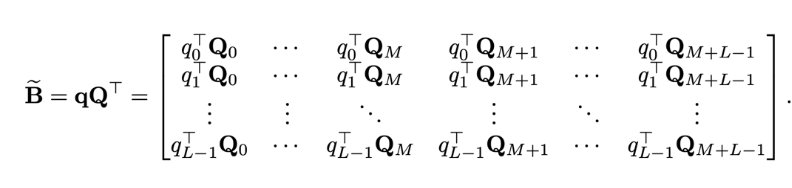
他发现那个B居然就是下面的这个式子每行偏移一下就能得到,这样复杂度就从四维乘积变成了,三维乘积+三维乘积,很好理解,因为那个Q是我们在改进1中计算好的,直接搜索一下拿来用就行。
改进三
这个改进思想和改进2一样,也是通过先生成一个矩阵,再shift即可,这里不再赘述。

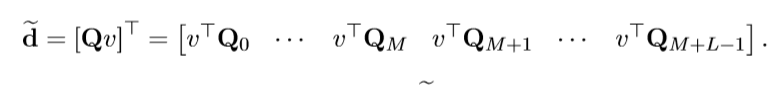
综合代码实现
源代码中给了两种Attention实现机制,一个是RelPartialLearnableMutiHeadAtten,还有一个是RelLearnableMultiHeadAttn,我就详细注释其中一个,具体可以去看原文实现的源代码coding。
class RelPartialLearnableMultiHeadAttn(RelMultiHeadAttn):def __init__(self, *args, **kwargs):super(RelPartialLearnableMultiHeadAttn, self).__init__(*args, **kwargs)# d_model:hidden dim ; n_head:num of head ;d_head: 头的隐藏层维度# r_net,转换位置编码的维度矩阵W-kRself.r_net = nn.Linear(self.d_model, self.n_head * self.d_head, bias=False)def forward(self, w, r, r_w_bias, r_r_bias, attn_mask=None, mems=None):# w是当前seg上一层输出,r是relative embeddingqlen, rlen, bsz = w.size(0), r.size(0), w.size(1)if mems is not None:cat = torch.cat([mems, w], 0)if self.pre_lnorm:# qkvnet是用于计算q\k\v变换的参数矩阵,和Transformer中一致w_heads = self.qkv_net(self.layer_norm(cat))else:w_heads = self.qkv_net(cat)r_head_k = self.r_net(r)w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)w_head_q = w_head_q[-qlen:]else:if self.pre_lnorm:w_heads = self.qkv_net(self.layer_norm(w))else:w_heads = self.qkv_net(w)r_head_k = self.r_net(r) # 这个就是Rij# q、k、v的生成w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)klen = w_head_k.size(0)w_head_q = w_head_q.view(qlen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_headw_head_k = w_head_k.view(klen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_headw_head_v = w_head_v.view(klen, bsz, self.n_head, self.d_head) # qlen x bsz x n_head x d_headr_head_k = r_head_k.view(rlen, self.n_head, self.d_head) # qlen x n_head x d_head#### compute attention score# r_w_bias是可训练的u参数,w_head_q是我们提前计算好存下来的# AC就是Attention计算中的acrw_head_q = w_head_q + r_w_bias # qlen x bsz x n_head x d_headAC = torch.einsum('ibnd,jbnd->ijbn', (rw_head_q, w_head_k)) # qlen x klen x bsz x n_head# r_r_bias是可训练的v参数# bd就是Attention计算中的bd,而且要做shift偏移rr_head_q = w_head_q + r_r_biasBD = torch.einsum('ibnd,jnd->ijbn', (rr_head_q, r_head_k)) # qlen x klen x bsz x n_headBD = self._rel_shift(BD)# [qlen x klen x bsz x n_head]attn_score = AC + BDattn_score.mul_(self.scale)#### compute attention probabilityif attn_mask is not None and attn_mask.any().item():if attn_mask.dim() == 2:# 我淦,居然mask ,pytorch自己给实现了attn_score = attn_score.float().masked_fill(attn_mask[None,:,:,None], -float('inf')).type_as(attn_score)elif attn_mask.dim() == 3:attn_score = attn_score.float().masked_fill(attn_mask[:,:,:,None], -float('inf')).type_as(attn_score)# [qlen x klen x bsz x n_head]attn_prob = F.softmax(attn_score, dim=1)attn_prob = self.dropatt(attn_prob)#### compute attention vectorattn_vec = torch.einsum('ijbn,jbnd->ibnd', (attn_prob, w_head_v))# [qlen x bsz x n_head x d_head]attn_vec = attn_vec.contiguous().view(attn_vec.size(0), attn_vec.size(1), self.n_head * self.d_head)#下面的部分就和标准的Transformer是一致的了##### linear projectionattn_out = self.o_net(attn_vec) # 拼接不同的head后进行输出attn_out = self.drop(attn_out)if self.pre_lnorm:##### residual connectionoutput = w + attn_outelse:##### residual connection + layer normalizationoutput = self.layer_norm(w + attn_out)return output淦!!!这个鬼论文源码又臭又长,我找到这个代码并且看懂一部分足足用了两个晚上,想读的哥们自己看看吧,我暂时反正是不想看了,这个工程化做的太严谨了,很多琐碎的知识点需要学习,不看了不看了。








