您现在的位置是:主页 > news > 厦门区块链网站开发/草莓永久地域网名入2022
厦门区块链网站开发/草莓永久地域网名入2022
![]() admin2025/6/7 12:58:34【news】
admin2025/6/7 12:58:34【news】
简介厦门区块链网站开发,草莓永久地域网名入2022,长沙做个网站多少钱,网站建设需要注意什么 知乎关于分类问题,结构化数据的分类问题都可以用xgboost来解决;nlp的分类问题使用bert来解决,nlp的所有问题都可以抽象成分类问题,也就是nlp问题都可以用bert来解决,包括命名实体识别、实体关系抽取、实体链接(…
关于分类问题,结构化数据的分类问题都可以用xgboost来解决;nlp的分类问题使用bert来解决,nlp的所有问题都可以抽象成分类问题,也就是nlp问题都可以用bert来解决,包括命名实体识别、实体关系抽取、实体链接(百度叫实体链指)等。有兴趣可以看这个基于bert的实体关系抽取,点我
这里说说xgboost怎么玩。
官网博客,点我
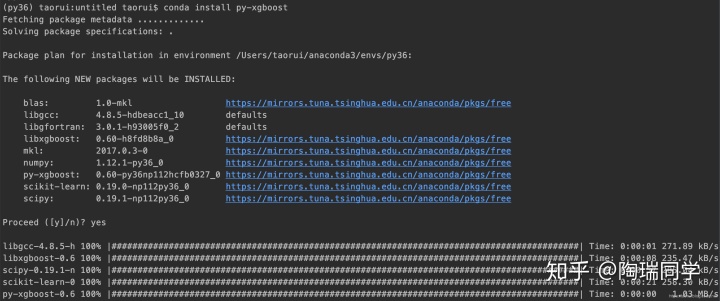
1.安装
mac安装,我直接:pip install xgboost安装报错(mac安装坑挺深),conda安装:conda install py-xgboost 就没有问题了,依赖什么的都会一起安装,省事。
2.运行报错:AttributeError: module 'xgboost' has no attribute 'DMatrix'
修改文件名,你的文件名很可能是xgboost.py
3.输入数据格式 :libsvm
libsvm 使用的训练数据和检验数据文件格式如下:
[label] [index1]:[value1] [index2]:[value2] …
[label] [index1]:[value1] [index2]:[value2] …label 目标值,就是说 class(属于哪一类),就是你要分类的种类,通常是一些整数。 index 是有顺序的索引,通常是连续的整数。就是指特征编号,必须按照升序排列 value 就是特征值,用来 train 的数据,通常是一堆实数组成。
详细见:https://www.cnblogs.com/codingmengmeng/p/6254325.html
4.mushroom数据:
每个样本描述了蘑菇的22个属性,比如形状、气味等等(将22维原始特征用加工后变成了126维特征并存为libsvm格式),然后给出了这个蘑菇是否可食用。其中6513个样本做训练,1611个样本做测试。
libsvm格式数据下载(训练测试数据都在这里):https://download.csdn.net/download/u011630575/10266113
5.跑一个最简单的demo
# coding=utf-8
import xgboost as xgb
import numpy as npif __name__ == '__main__':# 读取数据data_train = xgb.DMatrix('agaricus_train.txt')data_test = xgb.DMatrix('agaricus_test.txt')# 设定相关参数,训练模型param = {'max_depth': 2, 'eta': 1, 'silent': 1, 'objective': 'binary:logistic'}n_round = 10model = xgb.train(param, data_train, num_boost_round=n_round)# 预测结果y_predict = model.predict(data_test)# 实际标签y_true = data_test.get_label()print('y_predict:', y_predict)print('y_true:', y_true)终端输出(可以看到预测结果和标签结果是一致的,阈值设置0.5即可):









