您现在的位置是:主页 > news > 网站建设和管理专业好不好/重庆seo优化
网站建设和管理专业好不好/重庆seo优化
![]() admin2025/6/1 9:56:36【news】
admin2025/6/1 9:56:36【news】
简介网站建设和管理专业好不好,重庆seo优化,深圳画册设计网站,安卓项目开发1 Hive的基础操作和数据类型 1.1 Hive的基础操作 1.1.1 Hive命令 假定已将hive命令配置到环境变量中。 进入hive安装目录的bin目录下,执行hive --help命令,显示出: Usage ./hive <parameters> --service serviceName <service p…
1 Hive的基础操作和数据类型
1.1 Hive的基础操作
1.1.1 Hive命令
假定已将hive命令配置到环境变量中。
进入hive安装目录的bin目录下,执行hive --help命令,显示出:
Usage ./hive <parameters> --service serviceName <service parameters>
Service List: beeline cli help hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat schemaTool
Parameters parsed:--auxpath : Auxillary jars --config : Hive configuration directory--service : Starts specific service/component. cli is default
Parameters used:HADOOP_HOME or HADOOP_PREFIX : Hadoop install directoryHIVE_OPT : Hive options
For help on a particular service:./hive --service serviceName --help
Debug help: ./hive --debug --help注意Service List后面的内容即为所有的服务,下表提供了其中最有用的几个服务。
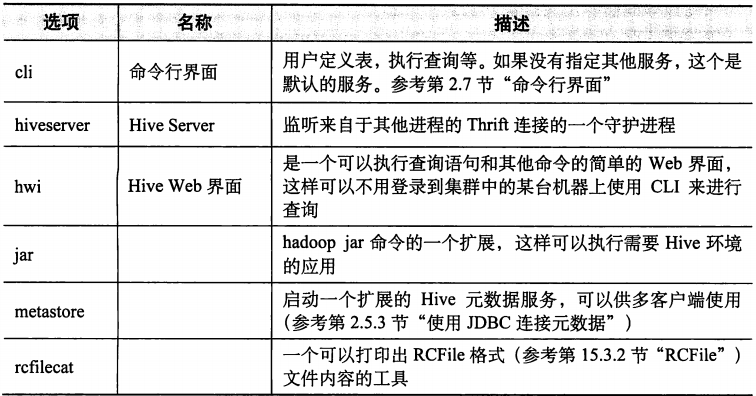

1.1.2 命令行界面
命令行界面,也就是CLI,是和Hive交互的最常用的方式。使用CLI,用户可以创建表,检查模式以及查询表,等等。
1. CLI选项
执行hive --service cli --help,控制台输出:
usage: hive-d,--define <key=value> Variable subsitution to apply to hivecommands. e.g. -d A=B or --define A=B--database <databasename> Specify the database to use-e <quoted-query-string> SQL from command line-f <filename> SQL from files-H,--help Print help information-h <hostname> connecting to Hive Server on remote host--hiveconf <property=value> Use value for given property--hivevar <key=value> Variable subsitution to apply to hivecommands. e.g. --hivevar A=B-i <filename> Initialization SQL file-p <port> connecting to Hive Server on port number-S,--silent Silent mode in interactive shell-v,--verbose Verbose mode (echo executed SQL to the
这个命令的一个简化版是./hive -help。注意和./hive --help做区分。
2.变量和属性
Hive中变量和属性命名空间有4种:hivevar、hiveconf、system、env。hivevar命名空间指的是用户自定义的变量,hiveconf命名空间指的是Hive相关属性的配置,system命名空间指的是Java定义的配置属性,env命名空间指的是Shell环境定义的变量信息,如HADOOP_HOME。

进入Hive的CLI,可以使用set这个命令来显示或者修改变量值。
使用
set;
set -v;1)hivevar
如何定义一个命名空间为hivevar的变量呢?
$ hive --define key=value
简写 hive -d key=value
或$ hive --hivevar key=value
sql语句:
$ hive --define foo=bar;
Logging initialized using configuration in jar:file:/usr/hive/hive-0.12.0/lib/hive-common-0.12.0.jar!/hive-log4j.properties
hive> set foo;
foo=bar
hive> set hivevar:foo;
hivevar:foo=bar
hive> set hivevar:foo=bar2;
hive> set hivevar:foo;
hivevar:foo=bar2
hive> set foo;
foo=bar2
hive> create table toss1(i int, ${hivevar:foo} string);hive> create table toss2(i2 int, ${foo} string);注意: 在CLI中查询语句中的变量引用会先被替换掉,然后才会将查询语句交给查询处理器。
2)hiveconf
hiveconf命名空间下有一个hive.cli.print.current.db属性,该属性的值默认是false,开启该属性可以在CLI提示符前打印出当前所在的数据库名,默认的数据库名是default。
sql语句
$ hive --hiveconf hive.cli.print.current.db=true
Logging initialized using configuration in jar:file:/usr/hive/hive-0.12.0/lib/hive-common-0.12.0.jar!/hive-log4j.properties
hive (default)> set hiveconf:hive.cli.print.current.db;
hiveconf:hive.cli.print.current.db=true
hive (default)> set hiveconf:hive.cli.print.current.db=false;
hive> set hiveconf:hive.cli.print.current.db=true;
hive (default)> 3)system和env
system命名空间,Java系统属性对这个命名空间具有可读可写权利;而env命名空间,对于环境变量只提供可读权权限。
用户使用system变量和env变量时,必须使用system:和env:前缀来指定系统属性和环境变量。
env命名空间可以作为向Hive传递变量的一个可选方式,例如:
$ YEAR=2012 hive -e "slect * from mytable where year = ${env:YEAR}";3.Hive命令运行方式
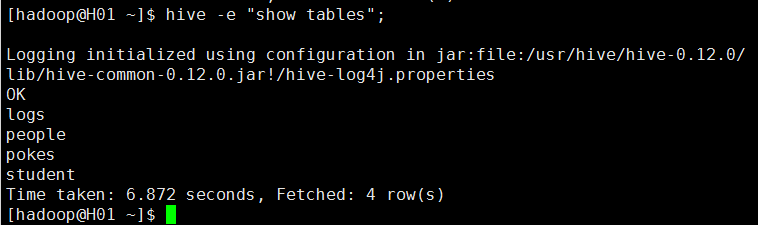
1)使用hive执行一次SQL语句,在linux命令行下使用hive -e "SQL语句"
2)把查询结果导入到某个文件,在linux命令行下使用hive -e "SQL语句"> /tmp/myquery

3)安静模式下执行SQL语句,在linux命令行下使用hive -S -e "SQL语句"

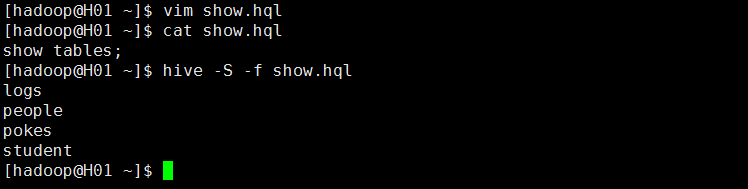
4)执行某个文件中的SQL语句,在linux命令行下使用hive -f 文件名
5)执行本地某个脚本文件中的SQL语,在linux命令行下使用 source 文件名。
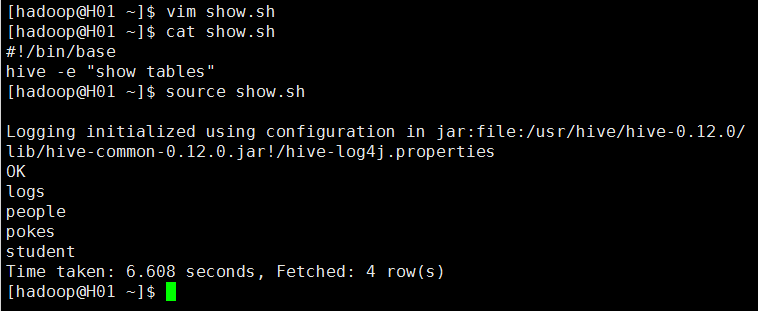
也可以进入hive命令行中执行本地的文件中的SQL语句
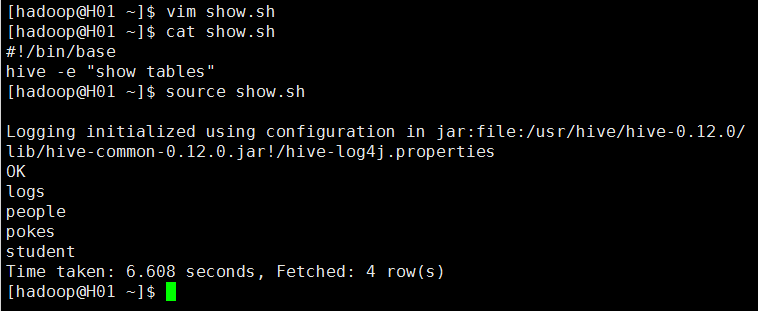
4.hiverc文件
当CLI启动时,在提示符出现之前会先执行这个文件,Hive会自动在${HIVE_HOME}/bin目录下寻找名为.hiverc文件,所以我们可以在这个文件中配置一些常用的参数。由于它是隐藏文件,我们可以用Linux的ls -a命令查看。
#在命令行中显示当前数据库名
set hive.cli.print.current.db=true;
#查询出来的结果显示列的名称
set hive.cli.print.header=true;
#启用桶表
set hive.enforce.bucketing=true;
#压缩hive的中间结果
set hive.exec.compress.intermediate=true;
#对map端输出的内容使用BZip2编码/解码器
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#压缩hive的输出
set hive.exec.compress.output=true;
#对hive中的MR输出内容使用BZip2编码/解码器
set mapred.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#让hive尽量尝试local模式查询而不是mapred方式
set hive.exec.mode.local.auto=true;5.hive中执行shell命令和hadoop命令
在hive cli中,可以直接执行shell命令和hadoop的dfs命令。
执行shell命令时,只要在命令前加上!并且以分号(;)结尾就可以。

但是hive cli中不能使用需要用户进行输入的交互式命令,而且不支持shell的“管道”功能和文件名的自动补全功能。例如! ls *.hql; 这个命令表示的是查找文件名为“*.hql”的文件,而不是表示显示以.hql结尾的文件。
执行hadoop的dfs命令时,只需要将命令中的hadoop关键字省略,然后以分号结尾。
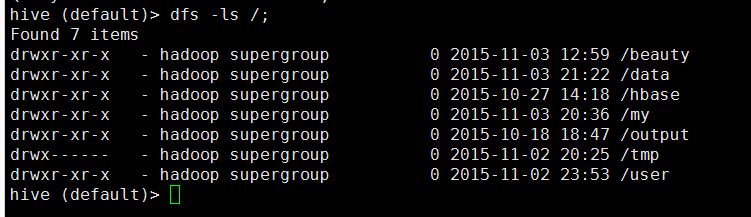
1.2 数据类型和文本文件格式
1.2.1 数据类型
Hive支持关系型数据库中的大多数基本数据类型,同时也支持关系型数据库中很少出现的3种集合数据类型。
1.基本数据类型
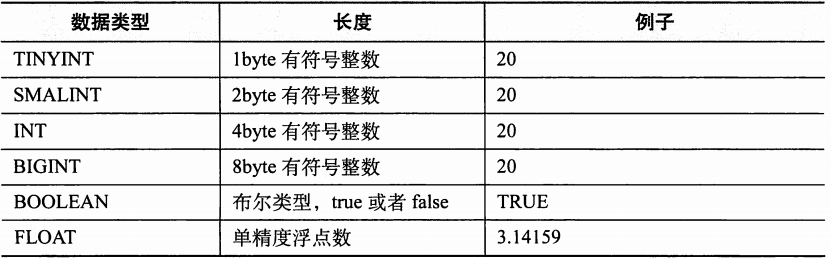
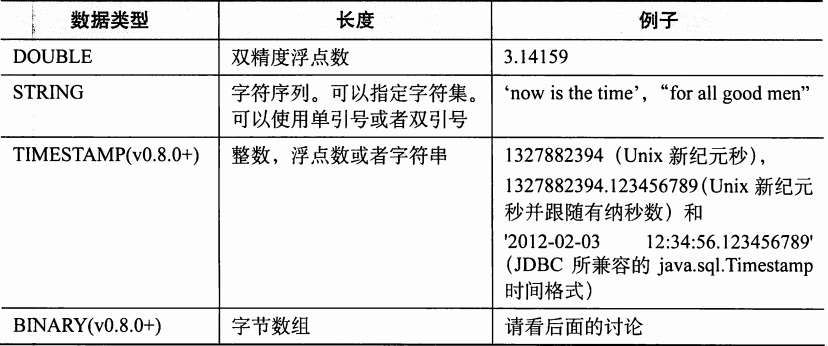
2. 集合数据类型
Hive中的列支持使用struct,map和array集合数据类型。
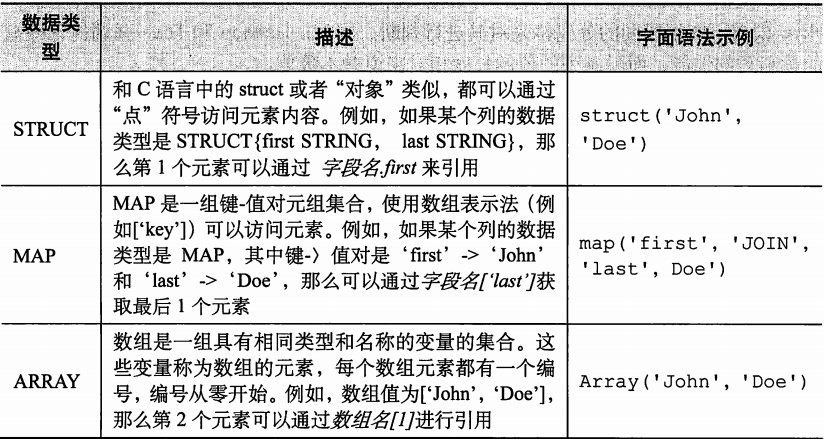
定义一个employees表
hive (default)> create table employees (> name string, > salary float,> subordinates array<string>,> decuctions map<string,float>,> address struct<street:string,city:string,state:string,zip:int>);
1.2.2 文本文件格式
Hive中默认的记录和字段分隔符。
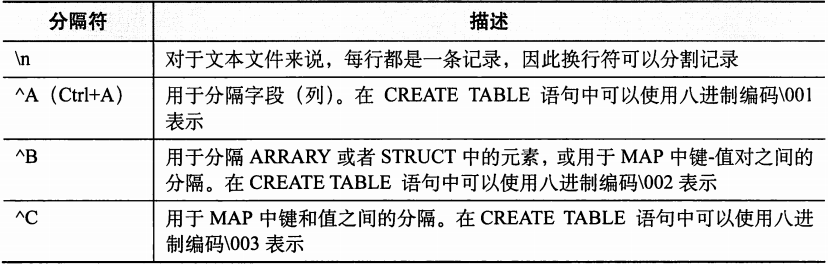
hive (default)> create table employees (name string, salary float,subordinates array<string>,decuctions map<string,float>,address struct<street:string,city:string,state:string,zip:int>) > row format delimited > fields terminated by '\001'> collection items terminated by '\002'> map keys terminated by '\003'> lines terminated by '\n'> stored as textfile;
这个SQL语句创建的表的结构和之前的那个表是一样的,只不过是明确指定了分隔符。








