您现在的位置是:主页 > news > 开发高端网站建设/佛山网站建设公司哪家好
开发高端网站建设/佛山网站建设公司哪家好
![]() admin2025/5/25 10:33:27【news】
admin2025/5/25 10:33:27【news】
简介开发高端网站建设,佛山网站建设公司哪家好,网站概念设计,做公司网站域名怎么做记账凭证IR系统最为关键的部分。 文章目录一、搜索引擎简介1:什么是搜索引擎(1)工作原理(2)系统流程2:搜索引擎分类(1)目录式搜索引擎(2)机器人搜索引擎(3…
IR系统最为关键的部分。
文章目录
- 一、搜索引擎简介
- 1:什么是搜索引擎
- (1)工作原理
- (2)系统流程
- 2:搜索引擎分类
- (1)目录式搜索引擎
- (2)机器人搜索引擎
- (3)元搜索引擎
- 二、链接分析技术
- 1:什么是链接分析?
- 2:基于链接分析的排序算法*
- (1)PageRank (Google)
- (i)PageRank算法基本思想
- (ii)如何计算 PageRank?
- (iii)计算实例
- (iv)结果分析
- (v)PageRank 算法:随机冲浪模型
- (vi)Google的实际计算
- (vii)进一步讨论
- (2)HITS (IBM Clever)
- (i)Hub值和Authority值
- (ii)HITS更新规则
- (iii)根集(Root Set)
- (iv)算法过程
- (v)计算实例
- (vi)优缺点
- (3)PageRank和HITS的比较
- 一些小问题
一、搜索引擎简介
1:什么是搜索引擎
用户角度
- 一个连接后台程序的入口页面
- 允许用户输入词语来说明所要找的页面的特点
- 返回那些满足查询的页面的链接
搜索引擎(Search Engine),亦称Web检索,是一种用于帮助用户在互联网上查询信息的搜索工具,它以一定的策略在互联网中发现和搜集信息,并对搜集的信息进行加工整理和组织存贮,为用户提供检索服务,输出排序检索结果
(1)工作原理

(2)系统流程

对原始网页的分析建立倒排索引是常规的步骤,这一节的重点在于分析网页结构时我们会产生PageRank,PageRank(连接分析算法)对搜索引擎的能力带来的极大的提高。
2:搜索引擎分类
(1)目录式搜索引擎
-
以人工方式或半自动方式搜集信息,由编辑员查看信息后,人工形成信息摘要,并将信息置于事先确定的分类框架中,提供目录浏览和直接检索。
-
特点:
信息准确、导航质量高
需人工介入,维护量大、信息量少、更新不及时 -
实例:Yahoo、LookSmart、OpenDirectory
(2)机器人搜索引擎
- 由spider自动在互联网中搜集和发现信息,由索引器建立索引,由检索器根据用户的查询检索索引库,并将结果返回给用户。
- 特点:
信息量大、更新及时、毋需人工干预
返回信息过多,用户必须在结果中筛选 - 实例: InfoSeek、Google、Baidu、AltaVista、Lycos
(3)元搜索引擎
- 没有自己的数据,而是将用户的查询请求同时向多个搜索引擎递交,将返回的结果进行去重、重新排序等处理后,作为自己的结果返回给用户
- 特点:
返回的信息量更大、更全
用户需要做更多的筛选 - 实例:Vivisimo、Dogpile
目前的Google和Baidu的搜索结果已经足够好了,而且信息量非常大,要综合二者的优势不那么容易,所以元搜索引擎不太稳。
二、链接分析技术
- 页面之间的链接通常隐含非常重要的信息
- 仅仅是“结构”就可以带来丰富的“语义”
1:什么是链接分析?
- 链接反映的是网页之间的“参与”、“引用”、“推荐”关系
- 根据网页的导入(反向,inlink)、导出(正向,outlink)链接的数量和质量决定该网页的重要性
- 页面的链接:
所提取的页面的指向页面(Pages pointed to by a retrieved page):导出链接(正向链接)
所提取页面的被指向页面(Pages that point to a retrieved page):导入链接(反向链接)
流行度(Popularity):一个页面的导入链接的数量
关系度(Relatedness):页面中相同超链的数目
2:基于链接分析的排序算法*
(1)PageRank (Google)

- 大脸表示的就是比较popular的网页,被指向的数目越多,网页越重要。
- 越大的脸指出去的权值也比较大,黄脸被多个大脸引用,所以他的脸比蓝脸大(蓝脸的追随者都是小脸)
好鬼畜
(i)PageRank算法基本思想
- 如果页面A链向页面B,则认为A到B的链接是A对B的支持投票,Google根据投票数(入度)来判断某个页面的重要性
- 不单只看入度,对参与投票的页面也进行分析,重要性高的页面所投的票具有更高的价值
- 对获得了高评价的页面给与较高的PageRank,在检索结果内的名次也会提升
PageRank高不见得相关
链入网页和链出网页
- 网页A通过超链接( hyperlink )链接到网页B。则称:
网页A是网页B的链入网页
网页B是网页A的链出网页
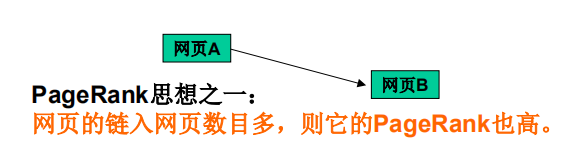
链接的数目与链接的质量
- 左图完全取决于入度的大小,基于假设:1,2,3的重要性一样
- 右图也要考虑链入网页出链的数目,如果一个网页有超级多个出链(n个),那么其中某一个链接所占的重要性可以看作1/n,而网页3只有一个出链,显然比较专一,可以把自己的重要性完整的传递给B。


上面这个公式什么意思呢?R(v)R(v)R(v)即网页vvv的重要性,对uuu而言,它的重要性等于所有指向uuu的页面vvv的重要性除以页面vvv的链接数目,乘以一个常数ccc。
- 反向链接数(number of inlink): 单纯的意义上的受欢迎度指标
- 反向链接源:反向链接是否来自推荐度高的页面 (有根据的受欢迎指标)
- 反向链接源页面的正向链接数(number of outlinks) :被选中的几率指标
对来自总链接数少页面的链接给予较高的评价,而来自总链接数多的页面的链接给予较低的评价
(ii)如何计算 PageRank?
-
用邻接矩阵 (adjacent matrix)
A表示邻接关系
aij=1a_{ij}=1aij=1,如果从页面 i 向页面 j有链接时
aij=0a_{ij}=0aij=0,如果从页面 i 向页面 j没有链接时 -
把这个邻接行列倒置后,并归一化,得到转移概率矩阵
M
如果页面i有di个出链
如果页面i有链接指向页面 j, 则 mji=1/dim_{ji}=1/d_imji=1/di ,否则mji=0m_{ji}=0mji=0 -
矩阵
M(列随机矩阵,column stochastic matrix) 每一列之和等于1


(iii)计算实例
7个web页面,为简单起见,不考虑这7个页面之外的链接

第一步:构造行列式A

第二步:得到转移概率矩阵M
先把A的每一行归一化然后进行一个转置。
然后我们按行来读就可以发现,第一行就是第一个页面被转移到的概率,(第二个页面肯定转向他,第三个页面有0.5的概率转向他,所以这个矩阵称之为转移概率矩阵)

第三步:对M进行特征值分解(1)

第三步:对M进行特征值分解(2)

第四步:获得PageRank排名

(iv)结果分析
- PageRank 的名次和反向链接的数目是基本一致的。
- 无论链接多少正向链接都几乎不会影响PageRank,相反地有多少反向链接却是从根本上决定 PageRank 的大小。
- 但是,仅仅这些并不能说明第1位和第2位之间的显著差别
- ID=1 的文件的 PageRank 是0.304,占据全体的三分之一,成为了第1位
- 特别需要说明的是,起到相当大效果的是从排在第3位 的 ID=2 页面中得到了所有的 PageRank(0.166)
- ID=2页面有从3个地方过来的反向链接,而只有面向ID=1页面的一个链接,因此(面向ID=1页面的)链接就得到了所有的 PageRank 数
- 不过,就因为 ID=1页面是正向链接和反向链接最多的页面,也可以理解它为什么是最受欢迎的页面
(v)PageRank 算法:随机冲浪模型


红色的线就表示一个跳转过程,用户沿着链接走烦了,就会跳出来。

所以(1-d)是一个网页固有的PR值,即使该网页并没有链接指向他,他也有(1-d)的PR值,但是(1-d)也是一个比较大的值了。
PageRank算法2(对算法1的修订)
不同之处在于,算法2的所有页面的PR值加起来是1。

PageRank算法的例子

如果用算法2的话网页级别之和等于1。
(vi)Google的实际计算
- Google采用一种近似的迭代的方法计算网页的网页级别:
- 先给每个网页一个初始值,然后利用上面的公式,循环进行有限次运算得到近似的网页级别。根据Lawrence Page 和 Sergey Brin在1999年公开发表的文章,他们实际需要进行100次迭代才能得到整个互联网的满意的网页级别值,
- 在迭代的过程中,每个网页的网页级别的和是收敛于整个网络的页面数的。所以,每个页面的平均网页级别是1,实际上的值在(1-d) 和(dN+(1-d))之间。
上面实例的迭代情况

(vii)进一步讨论
入链(Inlinks)的影响

阻尼因子的影响



出链(Outlinks)的影响

悬摆链(Dangle Links)的影响
当一个页面没有出链的时候,它的PageRank值不会传递给别的页面, Lawrence Page和Sergey Brin把链到这样页面的链接称为悬摆链( dangling links )


- 据Page和Brin称,Google在索引页面时,悬摆链的量很大,主要是由于受robot.txt的限制及索引了一些没有链出的文件类型如PDF等
- 为消除这种负面影响,google在计算级别时,将此类链接从数据库里去掉,在计算完毕后,再单独计算悬摆链所链到的页面

不停的杀掉悬摆链
页面数目的影响

- 网页增加后,总的PageRank值并没有明显增加,上例从33变为34
- 但几乎每个页面的级别值减少了(除了A),这是由于新加页面分享了入链带来的值
PageRank的缺陷
- Web的链接具有以下特征:
有些链接具有注释性,也有些链接是起导航或广告作用
基于商业或竞争因素考虑,很少有Web网页指向其竞争领域的权威网页
权威网页很少具有显式的描述 - 可见平均分布权值的PageRank不符合链接的实际情况
- 许多链接经纪商和网站向别的网站出售文本链接时,会将PR值作为定价因素之一
- 可以通过链接来控制PR(如何做到?),因此PR值在排名中作用应该被正确的评估
- 搜索引擎目前的重要任务是反作弊(Web Spam)
(2)HITS (IBM Clever)
PR不考虑出度,但是出度很多的有可能是一个目录型网页,比如资源网站的首页,目录性很强。

(i)Hub值和Authority值

迭代计算方法

(ii)HITS更新规则
网页的h值取决于本身指出去的网页的权威性之和,网页的权威性取决于指向该网页的h值之和。


(iii)根集(Root Set)
输入一个查询,所有相关网页集合形成根集合。然后所有和根集合相关的网页集合作为基本集合。

(iv)算法过程

当然我们有两个值a和h,根据哪个属性进行排序完全取决于个人。

(v)计算实例


(vi)优缺点
- 很多例子中,最后的权威网页可能不在初始集里
- 权威性可从正向链接和反向链接页面带来,HITS可以计算它的权威性
- 需要特别指出的是,因为一个网页本身有很多个不同的主题,这使得HITS算法的结果容易出现主题漂移(Topic Drift)和概念泛化(Concept Generalization)现象
例如,本来查询的是“物理”,但结果可能出现“数学”和“自然科学”等主题。为了使结果的主题单一化,可以利用许多其它的文字信息来克服这个问题,如利用URL对应的锚文字、URL所在的上下文信息、URL本身的文字信息等等
(3)PageRank和HITS的比较
- PageRank独立于查询,HITS依赖于查询
- HITS算法将重要性在Hub页和Authorities页之间互相传递,而PageRank将重要性在Authorities页之间进行传递
- PageRank可在索引时计算,HITS需在查询时计算,一般用在相关反馈(Relevance Feedback)
一些小问题
- 搜索引擎的三大组成部分是什么?简述搜索引擎的工作流程。
三大组成部分:搜索系统、索引系统、检索系统。
工作流程大概是:搜集-整理-服务。搜集工作主要负责原页面的抓取和提取。整理的话只要包含了倒排索引的建立,网页结构的分析(PageRank的生成)。服务即对查询的分析并返回搜索结果。 - 什么是悬摆链?什么样的网络结构对提升单个页面的PR值有效?
悬摆链即一些网页没有外链,感觉类似与星型拓扑结构的网路对有利于提升中心节点的PR值,而环状的则相反。 - 什么是阻尼因子?请阐述其含义。
阻尼因子是对用户冲浪的一个建模,表示用户不断随机点击链接的概率。所以对每一个页面,用户有1-d的概率冲浪至另一个页面。 - HITS算法的主题子图是如何形成的?
首先根据查询找到的相关文档集合称之为根集,然后我们把根集相关的页面扩展进来(根集中页面指向的页面,以及指向根集中页面的页面)就形成了主题子图。 - 列举PageRank和HITS算法的共同点和区别。
共同点:都考虑到了网页的入度作为权威性。
区别:HITS考虑得更加全面,既包含权威性也包含目录性。HITS依赖于查询,因为主题子图的构建和查询时息息相关的,而PageRank独立于查询。








