您现在的位置是:主页 > news > 唯品会网站建设方案/免费手游推广平台
唯品会网站建设方案/免费手游推广平台
![]() admin2025/5/24 20:56:34【news】
admin2025/5/24 20:56:34【news】
简介唯品会网站建设方案,免费手游推广平台,网站开发常用的开发工具,网站开发运行及维护来源书籍: TENSORFLOW REINFORCEMENT LEARNING QUICK START GUIDE 《TensorFlow强化学习快速入门指南-使用Python动手搭建自学习的智能体》 著者:[美]考希克巴拉克里希南(Kaushik Balakrishnan) 译者:赵卫东 出版…
来源书籍:
TENSORFLOW REINFORCEMENT LEARNING QUICK START GUIDE
《TensorFlow强化学习快速入门指南-使用Python动手搭建自学习的智能体》
著者:[美]考希克·巴拉克里希南(Kaushik Balakrishnan)
译者:赵卫东
出版社:Packt 机械工业出版社
1.强化学习的启动和运行
1.1为何选择强化学习



1.2agent及其环境之间的关系

1.2.1定义agent的状态
 1.2.2定义agent的行为
1.2.2定义agent的行为
agent执行行为(动作)以探索环境。获取动作矢量是强化学习的主要目标。理想情况下,需要怒率获得最佳行为。
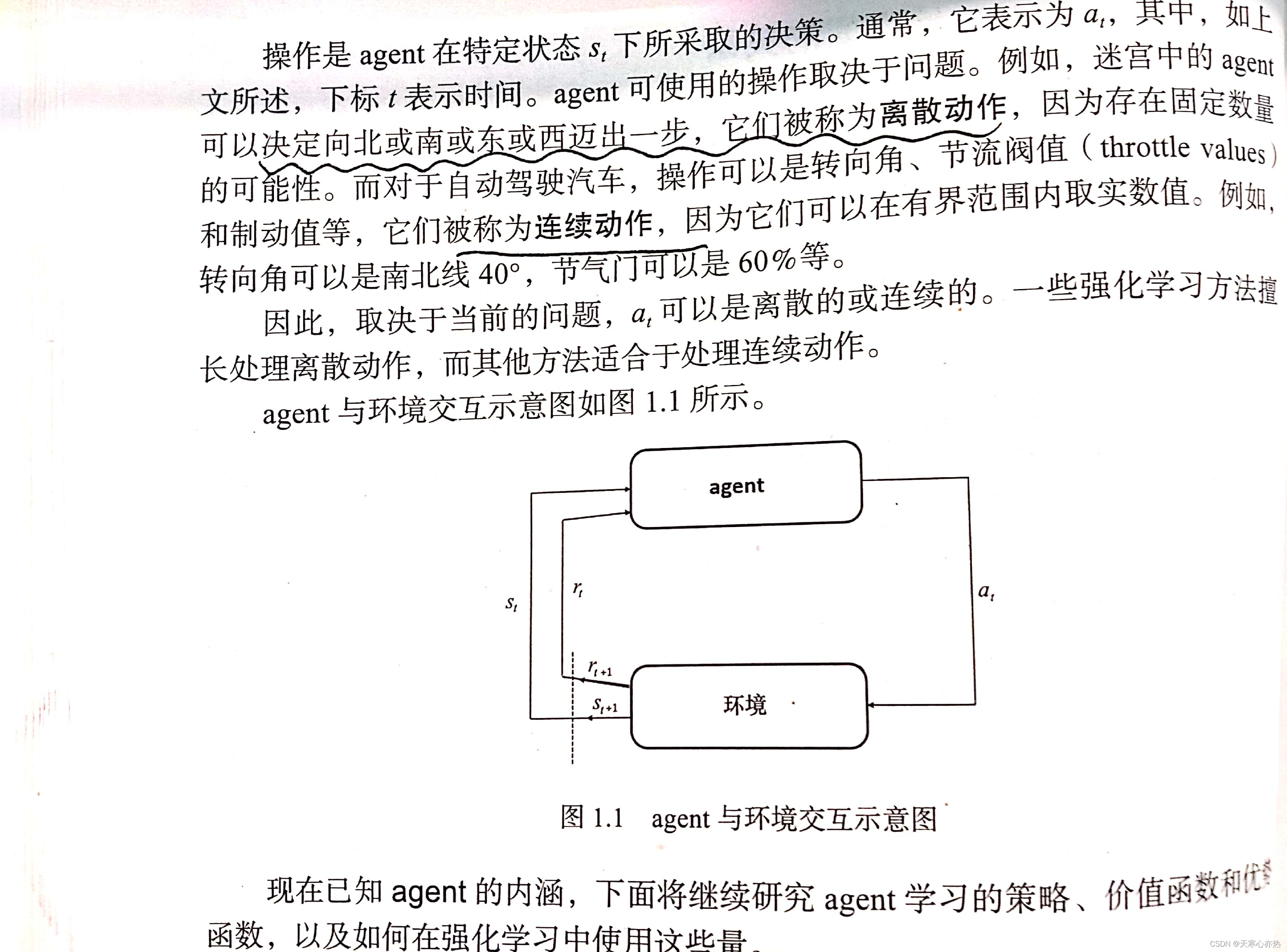
1.2.3了解策略、价值函数和优势函数


1.3认识回合

1.4认识奖励函数和折扣奖励


1.5学习马尔可夫决策过程

1.6定义贝尔曼方程

1.7同步策略与异步策略学习


1.8无模型训练和基于模型训练

思考题:
①对于同步策略或异步策略的强化学习算法是否需要重放缓冲区?
答:同步策略算法通常没有缓冲区,一般经验是在原地训练模型,将agent从时间t的状态移动到时间t+1的状态的相同策略用来评估性能的好坏。例如:SARSA、A3C、TRPO和PPO。
许多异步策略算法使用重(回)放缓冲区来存储经验,并从重放缓冲区中采样数据以训练模型。在训练步骤中,随机抽取一小批经验数据并用于训练策略和价值函数。例如:DQN、DDQN和DDPG。
②为什么需要折扣奖励?
答:折扣系数通常由γ表示,0≤γ≤1,其幂乘以。γ=0,使agent目光短浅,只针对眼前的奖励。γ=1,使agent目光长远,考虑到它完成最终目标的程度。因此,0~1范围内的γ值(不包括0和1)用于确保agent既不会目光过于短浅,也不会太有远见。由于0≤γ≤1,对未来的奖励远低于agent在不久的将来可以获得的奖励。这有助于agent不浪费时间,并优先处理其操作。
③如果折扣系数γ>1,将会发生什么?
答:如果折扣系数大于1, 会导致agent的训练不稳定,无法学习最优策略。
④既然有环境状态模型,那么基于模型的RL agent是否总是比没有模型的RL agent表现更好?
答:基于模型的可能会具有良好性能,但不能保证它比无模型的agent表现更好,因为构建的环境模型不一定总是好的。当然,建议一个足够精确的环境模型也很困难。
⑤强化学习和深度强化学习有什么区别?
在深度强化学习中,深度神神经网络用于和actor策略(后者在Actor-Critic背景中是真实的)。在传统的强化学习算法中使用表格
,但是状态的数量是非常大时是不能使用表格的,通常在大多数问题中都是这种情况。








