您现在的位置是:主页 > news > 网页制作模板中文/衡阳seo外包
网页制作模板中文/衡阳seo外包
![]() admin2025/5/21 12:35:13【news】
admin2025/5/21 12:35:13【news】
简介网页制作模板中文,衡阳seo外包,淘宝导购网站怎么做,asp网站建设下载代码链接 1. 研究问题 当前立体深度估计算法在算力受限的情况下难以在精度和速度达到较好的权衡,因此难以在要求实时深度感知的移动设备中进行准确的视差估计。 2. 研究方法 AnyNet 提出一个在任意时间进行视差估计的网络,该网络分四个阶段生成由粗到…
代码链接
1. 研究问题
当前立体深度估计算法在算力受限的情况下难以在精度和速度达到较好的权衡,因此难以在要求实时深度感知的移动设备中进行准确的视差估计。
2. 研究方法
AnyNet 提出一个在任意时间进行视差估计的网络,该网络分四个阶段生成由粗到精的视差图,第一阶段快速生成初始粗视差图,第二和第三阶段预测残差对上一阶段的视差进行细化,第四阶段采用SPNet进行进一步的视差细化。AnyNet在精度和速度上进行动态权衡,并允许在任何时间查询当前最精确的视差图。
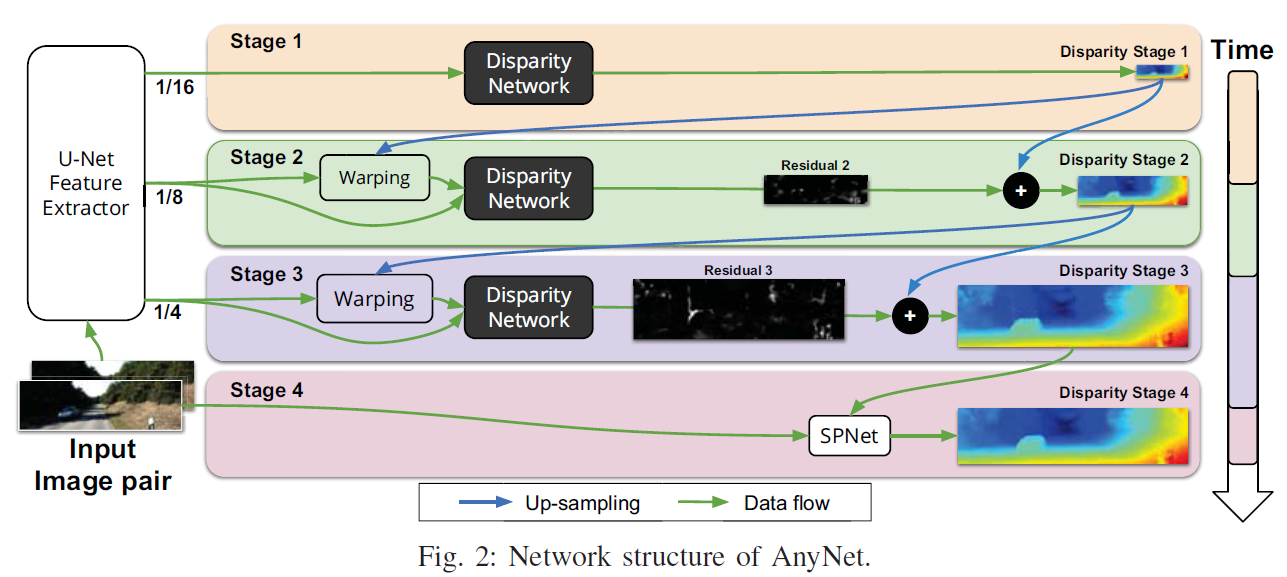

阶段1 - 阶段3
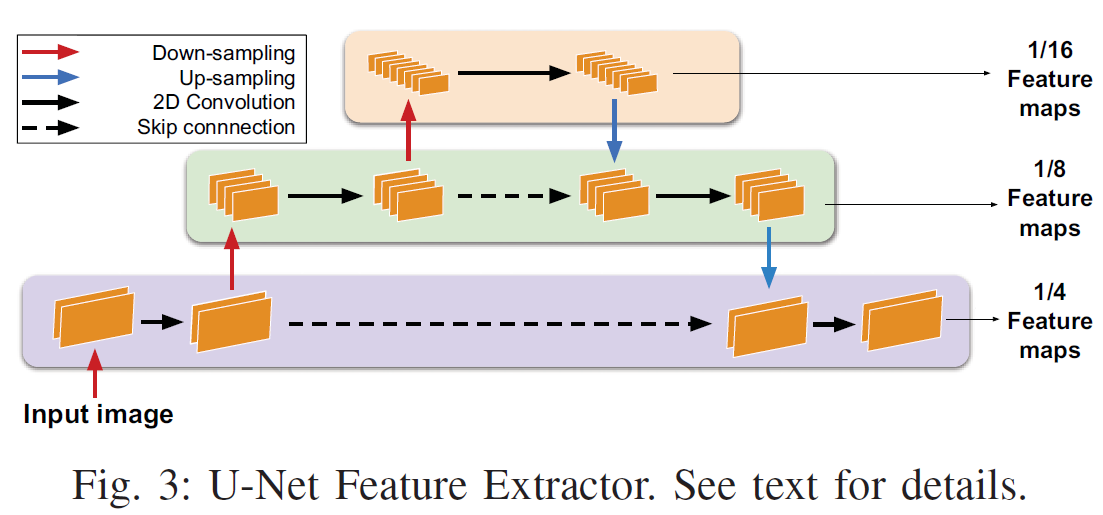
2.1 U-Net Feature Extractor
使用 U-Net 计算 1/16,1/8,1/4 三个分辨率的特征,根据时间要求,分别作为第一阶段到第三阶段视差回归网络的输入。例如,当允许的时间较短时(无人机快速飞行),只计算第一阶段的视差,那么就只输入1/16 分辨率的特征图给视差回归网络,计算粗视差图,第一阶段能达到30FPS。当允许的时间较长时(无人机慢速飞行),可以将1/8和1/4分辨率的特征图输入给视差回归网络,对上一阶段的视差图进行细化,甚至可以进入第四阶段,利用SPNet对视差进一步细化。这就是文章的一大亮点,对精度和速度的动态平衡。U-Net 还可以很好的结合全局上下文和局部细节特征,使网络的表达能力更好。
2.2 Disparity Network

为了计算第 2 和第 3 阶段中的残差,我们首先放大粗视差图,并通过逐像素应用视差估计,使用它来扭曲更高尺度的输入特征(图 2)。利用左视差图重建左图特征,如果当前的视差估计是正确的,则重建的左特征图应该原始左特征图匹配。由于低分辨率输入的粗糙性,通常仍然存在几个像素的不匹配,我们通过计算残差视差图来纠正。残余视差的预测与全视差图计算类似。唯一的区别是成本量计算为只限制在5个像素以内,并且将得到的残差视差图添加到前一阶段放大的视差图中。
2.3 Spatial Propagation Network(SPNet)
为了进一步改善我们的结果,我们添加了最后的第四阶段,在该阶段我们使用空间传播网络 (SPNet) [26] 来改进我们的视差预测。SPNet 通过应用局部滤波器来锐化视差图,该滤波器的权重是通过对左侧输入图像应用一个小的 CNN 来预测的。 我们表明,这种改进以相对较少的额外成本显着改善了我们的结果。
3. 实验结果
训练:
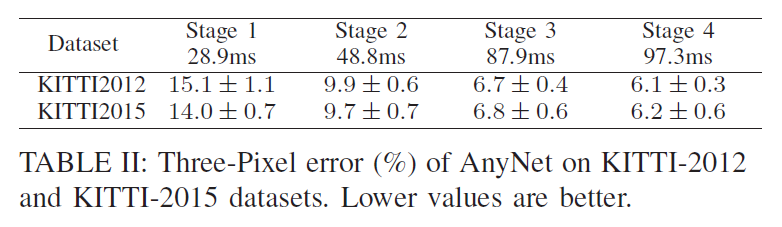
- 最大视差:192,对应于阶段 1 的视差深度 M = 192/16 = 12,在阶段 2 和 3 中,残差范围为 ±2,对应于阶段 2 中的 ±16 像素和阶段 3 中的 ±8 像素。
- 损失超参数:λ1=1/4,λ2=1/2,λ1=1,λ1=1\lambda_1 = 1/4, \lambda_2 = 1/2, \lambda_1 = 1, \lambda_1 = 1λ1=1/4,λ2=1/2,λ1=1,λ1=1,四个阶段联合训练
- 参数数量:一共
40000参数,比StereoNet少一个数量级,比PSMNet少两个数量级。 - 优化器:Adam,初始学习率为5e-4,批量大小为 6 。
- 数据集:场景流数据集和KITTI。对于场景流数据集,学习率保持不变,持续训练 10 个时期。对于KITTI数据集,使用场景流数据集上预训练的模型,然后对其进行 300 个 epoch 的微调。在 epoch 200 之后,学习率除以 10。
- 数据预处理:归一化为具有
单位方差,零均值的输入。参考GC-Net,图片随机剪裁为960 × 540。
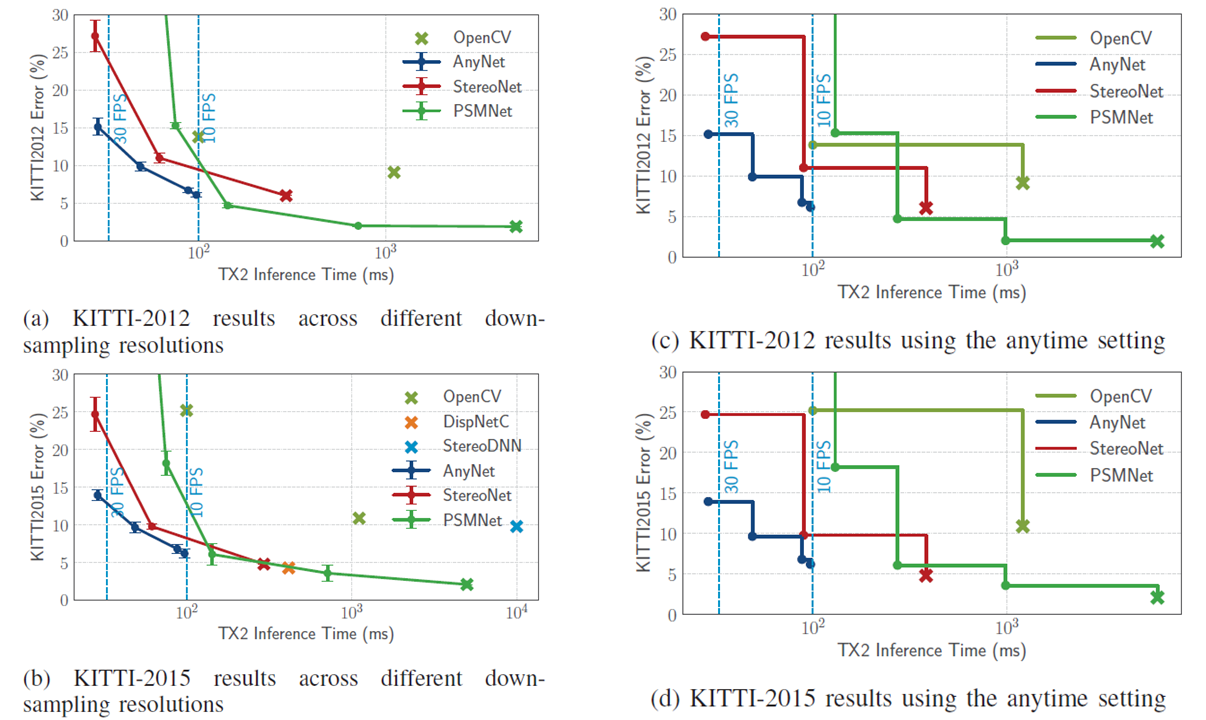
3.1 Anytime
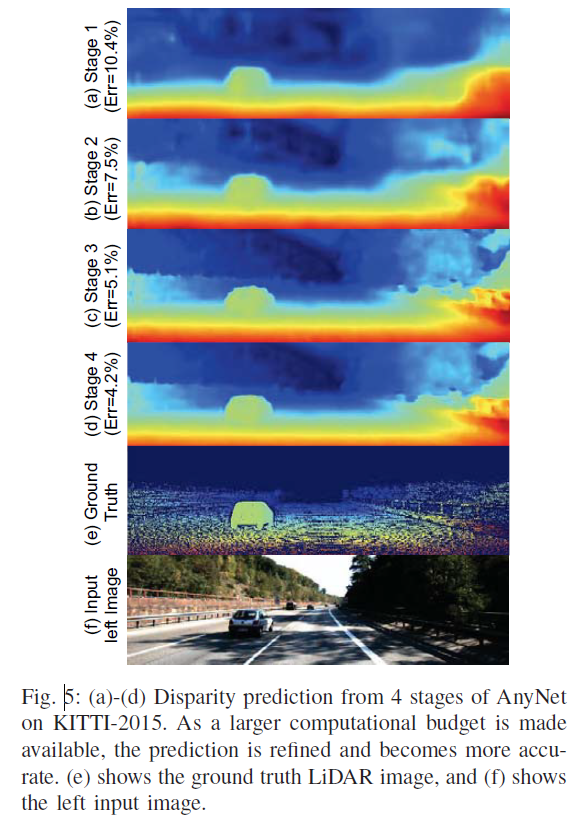
3.2 Evaluation
3.3 Ablation

4. 结论
(1)AnyNet是第一个从立体图像中进行随时高精度深度估计的网络,它实现了精度和速度的动态平衡,可以应用于功率和内存受限的移动设备。
(2)所提出的模型可以在 NVIDIA Jetson TX2 模块上处理 10-35 FPS 范围内的 1242×375 分辨率图像,而误差仅略微增加,模型的参数比最具竞争力的基线少两个数量级。
参考文献
[1] Kendall A , Martirosyan H , Dasgupta S , et al. End-to-End Learning of Geometry and Context for Deep Stereo Regression[J]. IEEE, 2017.
[2] Liu S , De Mello S , Gu J , et al. Learning Affinity via Spatial Propagation Networks[J]. 2017.








