您现在的位置是:主页 > news > 品牌网站建设绿d茶/2021小学生新闻摘抄
品牌网站建设绿d茶/2021小学生新闻摘抄
![]() admin2025/5/21 1:03:33【news】
admin2025/5/21 1:03:33【news】
简介品牌网站建设绿d茶,2021小学生新闻摘抄,利于优化的网站,深圳市专业做网站本文是对典型数据科学管道中的期望的高级概述。从构建业务问题到创建可操作的见解。 解决任何数据科学问题的第一步是首先制定问题,然后使用数据来解决。 “良好的数据科学更多地是关于你对数据提出的问题,而不是数据调整和分析。” - 莱利纽曼例如&…
本文是对典型数据科学管道中的期望的高级概述。从构建业务问题到创建可操作的见解。
解决任何数据科学问题的第一步是首先制定问题,然后使用数据来解决。
“良好的数据科学更多地是关于你对数据提出的问题,而不是数据调整和分析。” - 莱利纽曼
例如,您收集了来自在线调查,常规客户反馈,历史采购订单,历史投诉,过去危机等的数据。现在,您可以使用这些不同的数据来回答以下问题:
- 下个季度的现实销售目标应该是什么?
- 未来假期的最佳库存水平是多少?
- 公司应该采取什么样的措施来留住客户?
- 如何尽量减少投诉?
- 我们如何弥合定性和定量矩阵之间的差距?
- 如何才能带来更多满意的客户?
问题很重要

您询问的数据问题越多,您获得的洞察力就越多。这就是您自己的数据产生隐藏知识的方式,这些知识有可能完全改变您的业务。
下图是解决任何数据科学问题的典型管道。
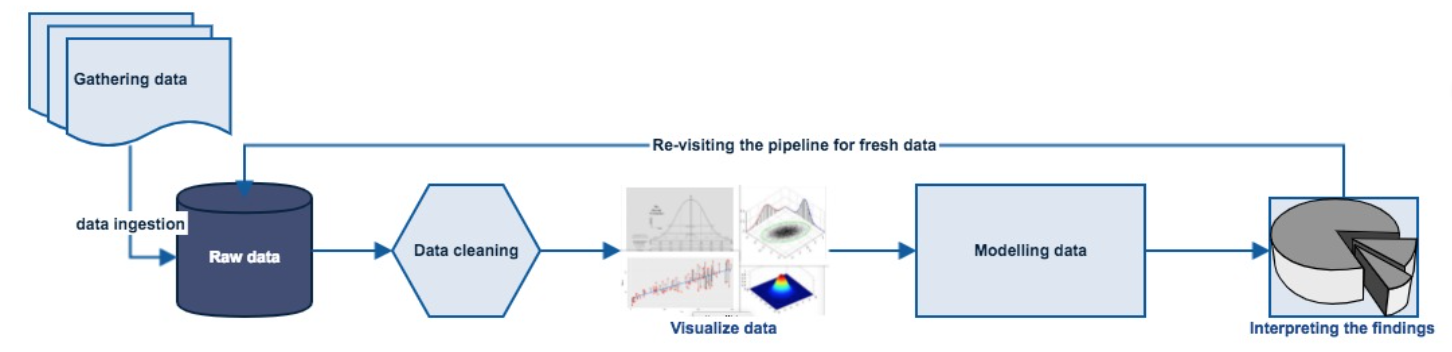
- 获取数据。
- 准备/清理数据。
- 探索/可视化数据,允许您查找数字中的模式。
- 建模数据。
- 解释调查结果。
- 重新访问/更新您的模型。
获取数据
没有数据,数据科学无法回答任何问题。因此,最重要的是获取数据,而不仅仅是获取数据; 它必须是“真实可靠的数据。”这很简单,垃圾就会出现垃圾。
根据经验,在获取数据时必须进行严格的检查。现在,收集所有可用数据集(可以来自Internet或外部/内部数据库/第三方)并将其数据提取为可用格式(.csv,JSON,XML等)。
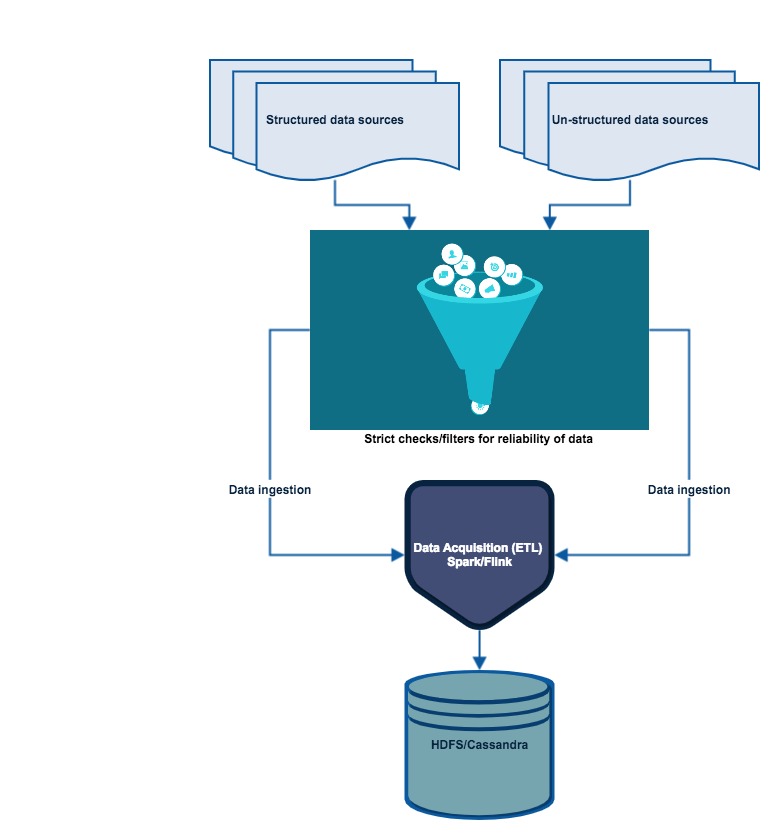
所需技能:
- 分布式存储:Hadoops,Apache Spark / Flink。
- 数据库管理:MySQL,PostgresSQL,MongoDB。
- 查询关系数据库。
- 检索非结构化数据:文本,视频,音频文件,文档。
准备/清理您的数据
管道的这个阶段非常耗时且费力。大多数情况下,数据都有自己的异常,例如缺少参数,重复值,不相关的特征等。因此,我们进行清理练习并仅采用对所提问题很重要的信息变得非常重要,因为结果和您的机器学习模型的输出仅与您输入的内容一样好。再次,垃圾垃圾进出。
目标应该是彻底检查数据,以了解您正在使用的数据的每个功能,识别错误,填写数据漏洞,删除重复或损坏的记录,有时丢弃整个功能等。域级专业知识至关重要在这个阶段,了解任何功能或价值的影响。
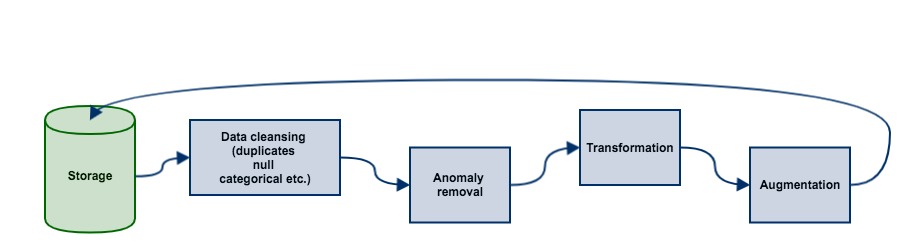
所需技能:
- 编码语言:Python,R。
- 数据修改工具:Python库,Numpy,Pandas,R。
- 分布式处理:Hadoop,Map Reduce / Spark。
数据的探索/可视化
在可视化阶段,您应该尝试找出数据的模式和值。您应该使用不同类型的可视化和统计测试技术来备份您的发现。这是您的数据将通过各种图形,图表和分析开始揭示隐藏的秘密的地方。在此阶段,需要领域级专业知识才能完全理解可视化及其解释。
目标是通过可视化和图表找出模式,这也将导致使用统计数据识别和测试重要变量的特征提取步骤。
所需技能:
- Python:NumPy,Matplotlib,Pandas,SciPy。
- R:GGplot2,Dplyr。
- 统计:随机抽样,推论。
- 数据可视化:Tableau。
数据建模(机器学习)
机器学习模型是通用工具。您可以访问许多工具和算法,并使用它们来实现不同的业务目标。您使用的功能越多,您的预测能力就越好。在通过使用相关模型作为预测工具来清理数据并找出对于给定业务问题最重要的功能之后,将增强决策制定过程。
这样做的目的是进行深入分析,主要是创建相关的机器学习模型,如预测模型/算法,以回答与预测相关的问题。
第二个重要目标是评估和改进您自己的模型。这涉及多个评估和优化周期。任何机器学习模型在第一次尝试时都不能是最高级的。您必须通过对新数据采集,最小化损失等进行培训来提高其准确性。
有多种技术或方法可用于评估模型的准确性或质量。评估您的机器学习算法是数据科学管道的重要组成部分。使用度量评价说,当你的模型可能会给你满意的结果accuracy_score但是当对其他指标,如评价可能会差的结果logarithmic_loss或任何其他这样的度量。使用分类精度来衡量模型的性能是一种标准方法,但是,仅仅真正判断模型是不够的。因此,在这里您将测试多个模型的性能,错误率等,并根据您的要求考虑最佳选择。
一些常用的方法是:
- 分类准确性。
- 对数损失。
- 混淆矩阵。
- 曲线下面积。
- F1得分。
- 平均绝对误差。
- 均方误差。
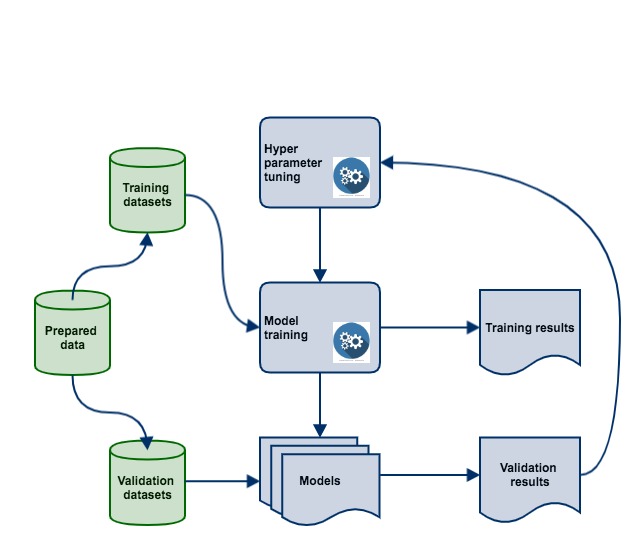
所需技能:
- 机器学习:监督/非监督算法。
- 评估方法。
- 机器学习库:Python(Sci-kit Learn,NumPy)。
- 线性代数和多元微积分。
解释数据
解释数据更像是将您的发现传达给感兴趣的各方。如果你无法向相信我的人解释你的发现,无论你做了什么都没用。因此,这一步变得非常关键。
此步骤的目标是首先确定业务洞察力,然后将其与您的数据结果相关联。您可能需要让领域专家将调查结果与业务问题相关联。领域专家可以帮助您根据业务维度可视化您的发现,这也有助于向非技术受众传达事实。
所需技能:
- 业务领域知识。
- 数据可视化工具:Tableau,D3.js,Matplotlib,ggplot2,Seaborn。
- 沟通:演讲/演讲和报道/写作。
重温您的模型
随着您的模型投入生产,根据您接收新数据的频率或根据业务性质的变化,定期重新访问和更新您的模型变得非常重要。您收到的数据越多,更新的频率就越高。假设你在一家运输供应商公司工作,有一天,燃料价格上涨,公司不得不把电动汽车带到马厩里。您的旧型号不考虑这一点,现在您必须更新包含此新类别车辆的型号。如果没有,您的模型会随着时间的推移而降级,并且性能也不会下降,从而使您的业务也会降级。新功能的引入将通过不同的变化或可能与其他功能的相关性来改变模型性能。
综上所述
-
确定您的业务问题并提出问题。
-
从真实可靠的来源获取相关数据。
-
获取数据,清理数据,使用可视化探索数据,使用不同的机器学习算法建模数据,通过评估解释数据,并定期更新旧模型。
您分析的大部分影响将来自您构建到数据平台的强大功能,而不是伟大的机器学习算法。所以,基本方法是:
-
确保您的管道是坚固的,端到端。
-
从合理的目标开始。
-
直观地了解您的数据。
-
确保您的管道保持稳固。
所以,这就是我对数据科学管道的看法。如果您想在本文中添加任何内容,或者您发现任何漏洞,请随时留言并不要犹豫!任何形式的反馈都非常值得赞赏。谢谢!








