您现在的位置是:主页 > news > 济南做网站知识/铁力seo
济南做网站知识/铁力seo
![]() admin2025/5/20 20:20:49【news】
admin2025/5/20 20:20:49【news】
简介济南做网站知识,铁力seo,邯郸疫情防控最新政策,怎么才能访问自己做的网站SQL性能优化 首先,要理解什么是执行计划 PLSQL可以看执行计划:圆形框起来的 也可以改代码格式:红框 数据库存储结构: 数据块 是oracle 对数据文件进行管理的单位, 数据库中最小的 数据块 是最小的数据单位ÿ…
SQL性能优化
首先,要理解什么是执行计划
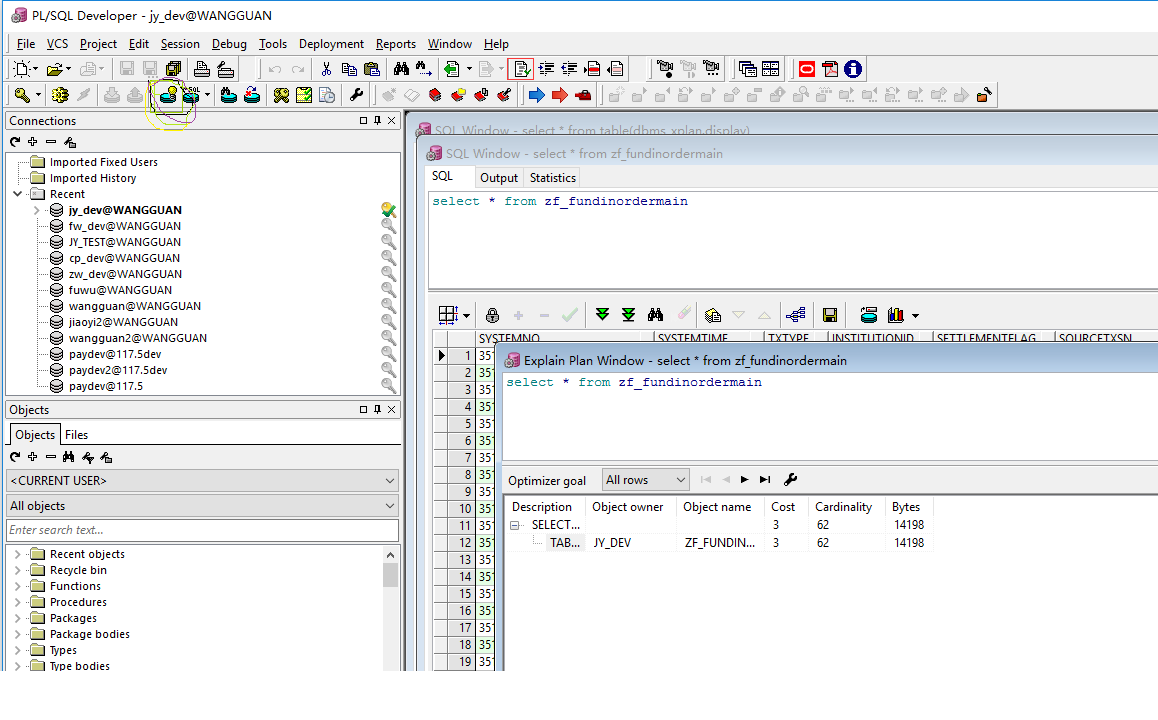
PLSQL可以看执行计划:圆形框起来的
也可以改代码格式:红框
数据库存储结构:
数据块 是oracle 对数据文件进行管理的单位, 数据库中最小的
数据块
是最小的数据单位,是最小的I/O 单位,
数据区:
连续的数据块构成的数据库逻辑存储分配单位
数据区何时被回收:
如果用户为回滚段(rollbacksegment)设定了 OPTIMAL 参数,Oracle将周期性地从其中回收数据扩展。
使用 drop delete 和 truncate,oracle不会回收对应的字段的数据块
数据段:
数据段是数据库对象的对应,一个数据库对象对应一个数据段
通俗的讲 一个表为一个段,如果表分区了,那么一个表分区是一个段
表空间:
由一个或者多个物理文件组成,建表时,将表建在表空间上
SQL性能优化:
1.select * from 避免使用
2.减少数据库的访问次数
3.索引上加函数,会致使索引失效,不要再索引上加函数
4.隐身转换也会导致索引失效 id='3'
5.like '%xx%' 第一个不要
6.IS NULL", " <>", "!=", "!>", "! <", "NOT", "NOT EXISTS", "NOT IN", "NOT LIKE", and "LIKE '%500'",因为他们不走索引全是表扫描
7.也不要在WHere字句中的列名加函数,如Convert,substring等,如果必须用函数的时候,创建计算列再创建索引来替代.还可以变通写法:WHERE SUBSTRING(firstname,1,1) = 'm'改为WHERE firstname like 'm%'(索引扫描)
8.NOT IN会多次扫描表,使用EXISTS、NOT EXISTS ,IN , LEFT OUTER JOIN 来替代,特别是左连接,而Exists比IN更快,最慢的是NOT操作.
复合索引,第一个生效,第二个不生效 有索引的先写前面
所谓的复合索引 create index 索引名 表名(字段1, 字段2)
在字段1和字段2 上都新建索引 这个就是复合索引
9.索引建立在关联表的关联字段上,
Where q.a = i.a 这个情况q 是驱动表,如果更加查询条件 q查出来的字段少,就把q放在前面, 否则where i.a = q.a
建立索引的规则:
1)重复值最少的列上建立索引
create unique index
2)尽量选择唯一的,最小的,不可Null的作为主键
3)尽量选择where字句中最频繁的列上建立索引
驱动表选择可以大大优化性能:
SQL的JOIN优化
在SQL中,Join操作常常会成为最为耗时的操作。DRDS在大多数情况下使用的Join算法都是Nested Loop及其派生算法(若Join有排序要求,则使用Sort Merge 算法)。DRDS 基于Nested Loop算法的Join过程是这样的:对于Join的左右两个表,DRDS首先从Join的左表(又叫驱动表)取出数据,然后将所取出数据中的Join列的值放到右表并进行IN查询,从而完成Join过程。因此,如果Join的左表的数据量越少,那么DRDS对右表做IN查询就次数就越少,如果右表的数据量也很少或建有索引,则Join的速度会更快。因此,在DRDS中,Join的驱动表的选择对于Join的优化非常重要。
具体参见链接:点击打开链接
索引失效问题:
- https://www.cnblogs.com/yanggb/p/10637595.html








