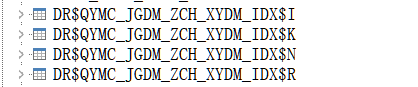您现在的位置是:主页 > news > 自己做抽奖网站违法/sem推广和seo的区别
自己做抽奖网站违法/sem推广和seo的区别
![]() admin2025/5/19 23:19:57【news】
admin2025/5/19 23:19:57【news】
简介自己做抽奖网站违法,sem推广和seo的区别,营销网站的优点,深圳婚纱摄影网站建设oracle全文检索一、全文检索词法分析类型1.basic_lexer2.chinese_vgram_lexer3.chinese_lexer二、全文检索创建1.创建词法分析器2. 设置词法属性1)创建词法2)指定字段(多字段或者单字段)3)其他属性(可查看官…
oracle全文检索
- 一、全文检索词法分析类型
- 1.basic_lexer
- 2.chinese_vgram_lexer
- 3.chinese_lexer
- 二、全文检索创建
- 1.创建词法分析器
- 2. 设置词法属性
- 1)创建词法
- 2)指定字段(多字段或者单字段)
- 3)其他属性(可查看官方文档)
- 3.创建索引
- 三、全文检索查询
- 四、删除全文检索
- 五、其他内容
- 1.检查数据库是否支持全文检索
- 2.手动建立全文检索需要的用户和内容
- 3.使用contains函数的时候,若没有全文检索会报错的。
- 4.建立全文检索会创建几个表,如下
一、全文检索词法分析类型
1.basic_lexer
针对英语。它能根据空格和标点来将英语单词从句子中分离,还能自动将一些出现频率过高已经失去检索意义的单词作为‘垃圾’处理,如if , is 等,具有较高的处理效率。但该lexer应用于汉语则有很多问题,由于它只认空格和标点,而汉语的一句话中通常不会有空格,因此,它会把整句话作为一个term,事实上失去检索能力。以‘中国人民站起来了’这句话为例,basic_lexer 分析的结果只有一个term ,就是‘中国人民站起来了’。此时若检索‘中国’,将检索不到内容。
2.chinese_vgram_lexer
专门的汉语分析器,支持所有汉字字符集(ZHS16CGB231280 ZHS16GBK ZHT32EUC ZHT16BIG5 ZHT32TRIS ZHT16MSWIN950 ZHT16HKSCS UTF8 )。该分析器按字为单元来分析汉语句子。‘中国人民站起来了’这句话,会被它分析成如下几个term: ‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’。可以看出,这种分析方法,实现算法很简单,并且能实现‘一网打尽’,但效率则是差强人意。
3.chinese_lexer
这是一个新的汉语分析器,只支持utf8字符集。上面已经看到,chinese vgram lexer这个分析器由于不认识常用的汉语词汇,因此分析的单元非常机械,像上面的‘民站’,‘站起’在汉语中根本不会单独出现,因此这种term是没有意义的,反而影响效率。chinese_lexer的最大改进就是该分析器 能认识大部分常用汉语词汇,因此能更有效率地分析句子,像以上两个愚蠢的单元将不会再出现,极大 提高了效率。但是它只支持 utf8, 如果你的数据库是zhs16gbk字符集,则只能使用笨笨的那个Chinese vgram lexer.
二、全文检索创建
1.创建词法分析器
beginctx_ddl.create_preference ('词法分析名称');ctx_ddl.create_preference ('词法分析名称','chinese_vgram_lexer');--类型
end;
2. 设置词法属性
1)创建词法
beginctx_ddl.create_pfaxureference ('词法名称');ctx_ddl.create_pfaxureference ('词法名称','MULTI_COLUMN_DATASTORE');--DATASTORE指定存储类型
end;
2)指定字段(多字段或者单字段)
beginctx_ddl.set_attribute('词法名称','columns','字段1,字段2,字段3,字段4,字段5');
end;
3)其他属性(可查看官方文档)
beginctx_ddl.create_preference('词法名称','BASIC_STORAGE');ctx_ddl.set_attribute('词法名称','I_TABLE_CLAUSE','tablespaces Idx_ctxsy');ctx_ddl.set_attribute('词法名称','I_INDEX_CLAUSE','tablespace Idx_ctxsy compress 2');
end;
3.创建索引
CREATE INDEX indexname --索引名ON tablename(字段名称)--表(字段),多字段指定在上方,这里只能指定一个INDEXTYPE IS ctxsys.CONTEXT --指定索引类型为全文检索PARAMETERS ('LEXER 分析器名称 sync (on commit) DATASTORE 词法名称') ;--最后设置全文检索的参数 分析器名称 词法名称,同步更新全文检索sync (on commit)。设置为同步之后就不用单独维护全文检索的更新,不设置同步需单位维护同步,一般为建立job
三、全文检索查询
select * from table_name where contains (column_name,'keyword') >0;
四、删除全文检索
beginCTX_DDL.drop_preference('词法分析名称');--删除词法分析器CTX_DDL.drop_preference('词法名称');--删除词法end;drop index indexname;--删除索引
五、其他内容
1.检查数据库是否支持全文检索
查看用户中是否存在ctxsys用户
查询角色里是否存在ctxapp角色。
以上两个中的1个不满足(不存在),则说明没有装过全文检索功能。
即使满足也要查看下用户下有没有相应存储过程,如果没有,也得执行下面操作,可以不见表空间,但必须执行
@?/ctx/admin/catctx.sql ctxsys Idx_ctxsys temp nolock
@?/ctx/admin/defaults/drdefus.sql
2.手动建立全文检索需要的用户和内容
1)先建立全文检索要使用的空间
sqlplus / as sysdba --进入控制台create tablespace Idx_ctxsys datafile '/oradata/sg186fx/ctxsys01.dbf size 10240M autoextend on next 32M maxsize 20480M;--创建全文检索使用的表空间
2).创建全文检索使用的用户和角色及相应的包,则需要执行oracle自带的一个脚本:cd $ORACLE_HOME/ctx/admin/catctx.sql
还是在sqlplus中执行:
@?/ctx/admin/catctx.sql ctxsys Idx_ctxsys temp nolock
在执行这个脚本的时候,输入了几个参数
第一个参数ctxsys为ctxsys用户的密码
第二个参数Idx_ctxsys为ctxsys用户要使用的表空间
第三个参数temp为ctxsys用户使用的临时表空间
第四个参数nolock为ctxsys用户处于解锁状态。
3)创建完成后,要登录ctxsys用户
connect ctxsys/ctxsys
执行以下脚本:
@?/ctx/admin/defaults/drdefus.sql--(这是个很重要的脚本,创建索引会使用该脚本创建的信息)
3.使用contains函数的时候,若没有全文检索会报错的。
4.建立全文检索会创建几个表,如下