您现在的位置是:主页 > news > 石家庄教育学会网站建设/查收录
石家庄教育学会网站建设/查收录
![]() admin2025/5/19 11:15:43【news】
admin2025/5/19 11:15:43【news】
简介石家庄教育学会网站建设,查收录,网站建设行业如何,wordpress 24小时插件回顾在数据处理进阶pandas入门(十三)中,我们介绍了pandas中的数据合并与修补,并对比了concat()方法和merge()方法、join()方法的差别。今天我们讲一下pandas中的去重与替换。去重方法duplicated()去重指的是不停的把后面不重复的元素移到前面来ÿ…
回顾
在数据处理进阶pandas入门(十三)中,我们介绍了pandas中的数据合并与修补,并对比了concat()方法和merge()方法、join()方法的差别。今天我们讲一下pandas中的去重与替换。
去重方法duplicated()
去重指的是不停的把后面不重复的元素移到前面来,也可以说是用不重复的元素占领重复元素的位置。之前内容中有介绍过unique()方法就是去重的一种方法,pandas中对于去重还提供了其他方法。
duplicated()方法的功能是用于判断Series中的元素、DataFrame中的记录行是否有重复,重复的为True,不重复的为False,返回的是一个布尔型的Series,默认为第一次出现的不算重复。
Series中的duplicated()方法如下:duplicated(keep='first')。它有一个keep参数,指定重复规则,默认为first,即第一次出现的不算重复。我们看一下它的基本用法。
import pandas as pdimport numpy as nps = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])print(s)print("---------------")# 判断是否重复,默认第一次出现的不算重复 返回一个布尔型Seriesprint(s.duplicated())print("---------------")# 通过布尔索引得到不重复的Series,功能类似于unique()print(s[s.duplicated() == False])运行结果如下图所示。由于duplicated()方法返回结果是一个布尔型Series,我们需要使用布尔型索引来得到一个去重后的Series。
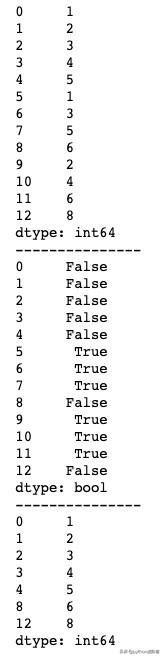
duplicated()方法
keep参数除默认的first外,还可以设置成last和False两种值。当设置成last时,则规定最后一次出现的元素为不重复;当设置成False时,则所有相同的元素都会被标记为重复。基本用法如下。
import pandas as pdimport numpy as nps = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])print(s)print("---------------")print(s.duplicated(keep='last'))print("---------------")print(s.duplicated(keep=False))运行结果如下图所示。可以看到,当keep='last'时,除了最后一次出现的元素外,其余位置上相同的元素都被标记为重复。而当keep=False时,凡是有相同的元素都被标记为了重复。

keep参数
duplicated()方法同样可以用于DataFrame。DataFrame中的duplicated()方法如下:duplicated(subset=None, keep='first')。相比于Series的duplicated()方法,除了keep参数,DataFrame的duplicated()方法还有一个subset参数,用于识别重复的列标签或列标签序列,默认所有列标签。基本用法如下。
import pandas as pdimport numpy as npdf = pd.DataFrame({'A':[1, 1, 2, 4, 5], 'B':[1, 1, 2, 2, 7]})print(df)print("---------------")print(df.duplicated())print("---------------")print(df.duplicated(['B']))运行结果如下图所示。当DataFrame的duplicated()方法不指定subset参数时,默认所有列标签,即只有所有列的当前位置上都满足是重复值时,才被标记为重复。

DataFrame的duplicad()方法
去重方法drop_duplicates()
duplicated()方法的返回结果是一个布尔型Series,无法直接得到去重后的结果。因此pandas为我们提供了drop_duplicates()方法,用于删除Series或DataFrame中的重复元素,并返回删除重复元素后的结果。
Series和DataFrame的drop_duplicates()方法分别为drop_duplicates(keep='first', inplace=False)和drop_duplicates(self, subset=None, keep='first', inplace=False)。对比duplicated()方法我们可以发现,只是多了一个inplace参数,因此用法基本与duplicated()一致。drop_duplicates()方法的基本用法如下。
import pandas as pdimport numpy as nps = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])print(s)print("---------------")s_drop = s.drop_duplicates(keep='last')print(s_drop)print("---------------")df = pd.DataFrame({'A':[1, 1, 2, 4, 5], 'B':[1, 1, 2, 2, 7]})print(df)print("---------------")df_drop = df.drop_duplicates(keep='last')print(df_drop)运行结果如下图所示。
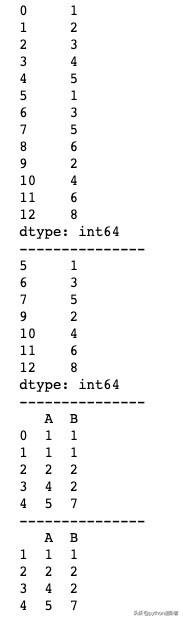
drop_duplicates()基本用法
上述代码中我们使用了新的Series和DataFrame去接收drop_duplicates()方法去重后的返回结果,那是因为drop_duplicates()方法默认是生成新的Series或DataFrame,而不改变原Series或DataFrame。如果我们想直接改变原Series或DataFrame,这个时候就用上了inplace参数。inplace参数默认为False不改变原Series或DataFrame,当我们想直接改变原Series或DataFrame时只需设置inplace=True即可。基本用法如下。
import pandas as pdimport numpy as nps = pd.Series([1, 2, 3, 4, 5, 1, 3, 5, 6, 2, 4, 6, 8])print(s)print("---------------")s.drop_duplicates(keep='last', inplace=True)print(s)print("---------------")df = pd.DataFrame({'A':[1, 1, 2, 4, 5], 'B':[1, 1, 2, 2, 7]})print(df)print("---------------")df.drop_duplicates(keep='last', inplace=True)print(df)替换方法replace()
pandas中使用replace()方法替换Series或DataFrame中的元素。replace()方法支持传入列表或字典,可一次性替换一个值或多个值,基本用法如下。
import pandas as pdimport numpy as nps = pd.Series(list('abcaasbdc'))print(s)print("---------------")print(s.replace('a', 1))print("---------------")print(s.replace(['a', 's'], 1))print("---------------")print(s.replace({'a':1, 'b':2, 'c':3}))运行结果如下图所示。replace()会遍历所有元素,并将对应的所有元素进行替换。

Series的replace()方法
DataFrame的replace()方法与Series一样,并且会替换所有对应元素。基本用法如下。
import pandas as pdimport numpy as npdf = pd.DataFrame({'A':[1, 1, 2, 4, 5], 'B':[1, 1, 2, 2, 7]})print(df)print("---------------")print(df.replace(1, 'a'))print("---------------")print(df.replace([1, 7], 'Hello World!'))print("---------------")print(df.replace({1:'a', 2:'b', 4:'d'}))运行结果如下图所示。

DataFrame的replace()方法
总结
以上内容介绍了pandas中的数据去重与替换,重点掌握去重方法duplicates()方法与drop_duplicates()方法的用法与差别、各参数的含义和用法,以及替换方法replace()方法的基本用法。感谢大家的支持与关注,欢迎批评指正,一起讨论~








