您现在的位置是:主页 > news > 怎么做投注网站/网址搜索引擎
怎么做投注网站/网址搜索引擎
![]() admin2025/5/19 3:11:44【news】
admin2025/5/19 3:11:44【news】
简介怎么做投注网站,网址搜索引擎,北京小程序开发平台,厦门网站建设推荐前言数据从来不是独立存在的,对数据进行处理的过程为数据加工,数据加工流程之间是存在依赖关系的,为了解决定时和依赖问题,我们引入了任务调度系统。在数据平台中,任务调度系统负责管理任务的启动时间,任务…

前言
数据从来不是独立存在的,对数据进行处理的过程为数据加工,数据加工流程之间是存在依赖关系的,为了解决定时和依赖问题,我们引入了任务调度系统。在数据平台中,任务调度系统负责管理任务的启动时间,任务之间的依赖关系,保证数据加工流程能正确运行。
除了定时功能,任务调度系统对于任务之间的依赖处理使得调度更加灵活。同一流程内的任务可以通过连线实现依赖;不同流程之间可以通过设置流程间的依赖关系结合来实现依赖。
Apache Dolphin Scheduler 是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
DolphinScheduler系统架构
Dolphin Scheduler 1.3.x 的系统架构图如下所示:
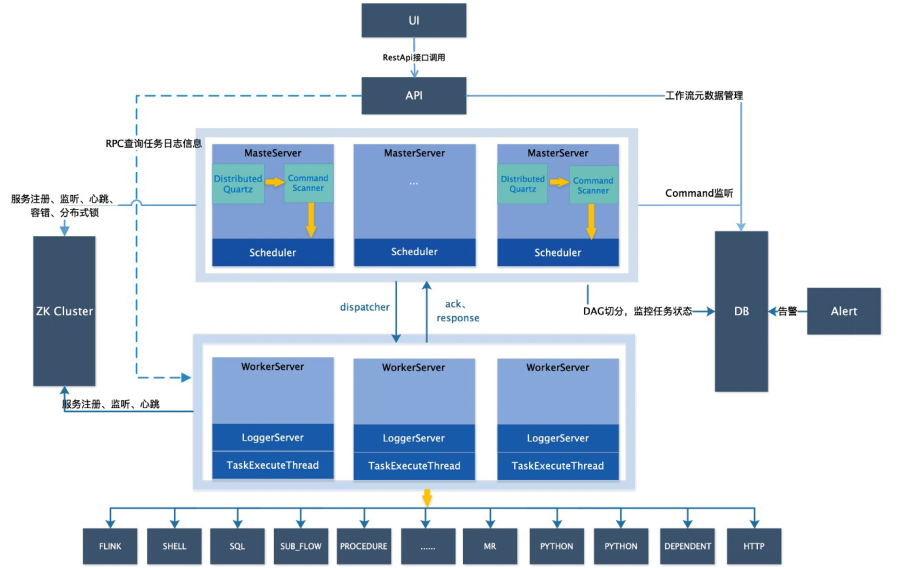
Dolphin Scheduler 1.3.x 的系统架构由以下服务组成:
01 MasterServer
- MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。MasterServer基于netty提供监听服务
该服务内主要包含:
- Distributed Quartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作
- MasterSchedulerThread是一个扫描线程,定时扫描数据库中的 command 表,根据不同的命令类型进行不同的业务操作
- MasterExecThread主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理
- MasterTaskExecThread主要负责任务的持久化
02 WorkerServer
- WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。WorkerServer基于netty提供监听服务
该服务内包含:
- FetchTaskThread主要负责不断从Task Queue中领取任务,并根据不同任务类型调用TaskScheduleThread对应执行器
- LoggerServer是一个RPC服务,提供日志分片查看、刷新和下载等功能
03 ZooKeeper
- ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错,另外系统还基于ZooKeeper进行事件监听和分布式锁
04 Task Queue
- 提供任务队列的操作,目前队列也是基于Zookeeper来实现
05 Alert
- 提供告警相关接口,接口主要包括告警两种类型的告警数据的存储、查询和通知功能。其中通知功能为邮件通知
06 API
- API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等
07 UI
- 系统的前端页面,提供系统的各种可视化操作界面
为什么选择DS
相信不少人都使用过 crontab 这个 Linux 系统自带的调度工具,crontab 配置简单、使用方便。crontab作为定时调度用来启动一些服务之类的挺方便的,但随着调度任务的量级增加,相互之间存在依赖关系也是比较复杂,这时候crontab作为调度工具就不能满足我们对数据加工的需求了,现在是需要使用调度系统来管理调度我们开发的流程。我们在整合数据加工的过程中发现按照 crontab 调度来整合的话逻辑处理太复杂,工作量太大,不容易定位到问题,后期维护起来也比较困难。后来也查了好几种解决方案,最终选择了Dolphin Scheduler,Apache Dolphin Scheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。我们可以通过使用 DS 完成带调度的数据加工,以下是Dolphin Scheduler的特点:
01 DS的易用性
- Dolphin Scheduler 具有图形化界面,通过图形化操作界面使开发更简洁
- 可以在画布里添加大数据相关组件实现数据加工,然后通过组件之间的连线确定任务依赖,在图形界面我们也可以很直观的看到树形图、甘特图、任务状态统计和流程状态统计展示,还可以通过单个流程状态快速定位到问题节点查看日志解决问题
02 DS的高可用性
- Dolphin Scheduler 支持集群 HA ,通过配置 ZooKeeper 实现 Master 和 Worker 的去中心化设计,通过提高服务节点的容错能力实现服务的高可用
03 DS支持多种任务类型
- Dolphin Scheduler 支持许多任务类型:Shell,MR,Spark,Flink,SQL(MySQL,Postgre SQL,hive,Spark SQL,Oracle等),DataX,Sqoop,Python,Sub_Process,Procedure等
04 DS操作类型的多样性
- 我们可以通过 Dolphin Scheduler 实现流程定时调度、依赖调度、手动调度、手工暂停/停止/恢复,同时支持失败重试/告警功能,从节点恢复失败、重跑等功能
05 DS的参数设置
- Dolphin Scheduler支持流程的全局参数设置和流程下的每个节点的自定义参数设置
06 DS的补数操作
- Dolphin Scheduler 支持补数,包括串行补数、并行补数2种模式。串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,只生成一条流程实例;并行补数:指定时间范围内,多天同时进行补数,生成N条流程实例
07 DS的社区活跃
- Dolphin Scheduler 作为一款中国团队开发的开源架构,他的社区是非常活跃的,我们可以直接在GitHub上提交自己的问题,还可以在为微信群里和众多开发者一起讨论问题,社区活跃的优点在于一般你遇到的问题别人可能已经遇到过了,只需要描述清楚你的问题对号入座基本上很快都能解决或定位到问题
Demo
这边列2个在使用DS过程中觉得非常实用的功能:
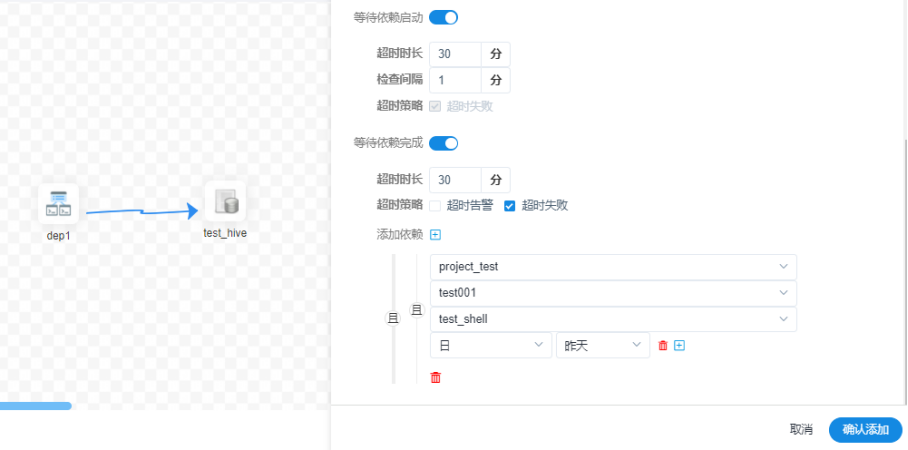
1、依赖设置
- 我们可以通过 DEPENDENT 组件来实现设置不同流程之间的依赖,可以设置超时时长和等待间隔,这2个结合启动时间可以很灵活的管理流程之间的运行关系,特别是在某些特殊情况下批次日期为T-1的流程A依赖T-2、T-N或某个范围内运行成功的流程B,在Dolphin Schedulerr 也可以很好的实现,存在依赖关系的流程A、流程B之间的批次日期要一致
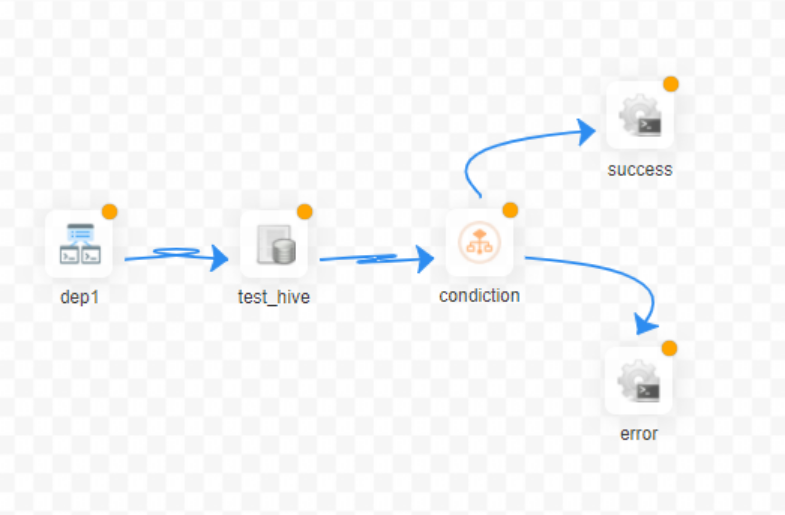
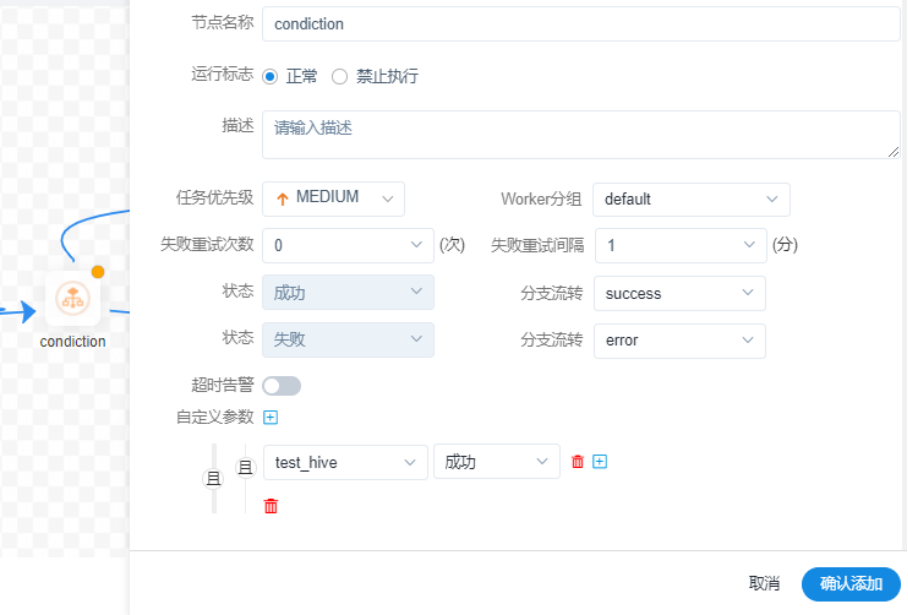
2、条件分支
- 可以通过CONDITIONS组件来实现条件分支,根据当前流程的上一个任务的运行状态来决定之后要运行哪一个后置加工,这种适用于弱依赖的使用场景
 总 结
总 结如果你在数据开发过程中对开发的流程需要设置定时功能且有许多依赖错综复杂的依赖关系,如果你想简化开发过程中的调度关系更多的关注于每个任务本身的实现,如果你想高效管理开发的流程。那么数据加工的开源任务调度系统解决方案 Dolphin Scheduler 是个不错的选择。
作者:宋夏编辑:詹思璇向普适极客回复关键词“大数据”获取学习网址
技术15期:浅谈Hbase中的数据结构和算法

技术14期:TensorFlow2.x的几个实用技巧与工具使用
想学习更多技术内容
别忘了关注普适极客


.png)





