您现在的位置是:主页 > news > 有没有什么好的网站/兰州seo外包公司
有没有什么好的网站/兰州seo外包公司
![]() admin2025/5/18 21:57:18【news】
admin2025/5/18 21:57:18【news】
简介有没有什么好的网站,兰州seo外包公司,济南济阳哪有做网站的,类似问卷星做心理测试的网站现在还在写JDBC事务的文章,我觉得我一定是相当的Out了,现在主流的java应用,框架都是分布式的,各种分布式的事务,或者容器事务才是需要学习的重点,在这里谈JDBC确实有点不合时宜,但任何的java 开…
现在还在写JDBC事务的文章,我觉得我一定是相当的Out了,现在主流的java应用,框架都是分布式的,各种分布式的事务,或者容器事务才是需要学习的重点,在这里谈JDBC确实有点不合时宜,但任何的java 开发人员,如果不能够深入的理解数据库的事务,那在做数据处理的方面就一定是有所欠缺的,另外确实很少有文章能够谈到JDBC和数据库事务的精髓,希望这里能够让你深度的了解到什么是JDBC的事务以及它和数据库的关系。
事务
事务应该说是数据库最核心的能力之一,对于任何和数据打交道的开发人员而言,是非常重要的
事务的原子性
事务的最基本功能是原子性。比如张三给李四异地打钱5000元,假设同一银行异地手续费是5‰,那么数据库要干三件事情
张三的账户余额扣除5025(含5‰手续费,中国特色)
李四的账户余额增加5000
银行自己的账户余额增加25
这三件事情要么全部成功,要么全部失败,绝对不能一些成功,一些失败。
本地事务
对上面提出的问题,可以用一下代码简单示范
String sql =
“update Account set Balance = Balance + ? where id=?”try (Connection con = dataSource.getConnection();
PreparedStatement pstmtForSource = con.preparedStatement(sql);
PreparedStatement pstmtForTarget = con.preparedStatement(sql);
PreparedStatement pstmtForBlank = con.preparedStatement(sql)) {con.setAutoCommit(false); //关闭自动提交,手动事务开始pstmtForSource.setInt(1, -5025);pstmtForSource.setLong(2, sourceAccountId);pstmtForSource.executeUpdate();pstmtForTarget.setInt(1, +5000);pstmtForTarget.setLong(2, targetAccountId);pstmtForTarget.executeUpdate();pstmtForBank.setInt(1, +25);pstmtForBank.setLong(2, 1L);银行自己卡号为1pstmtForBank.executeUpdate();con.commit(); //提交事务
} catch (SQLException | RuntimeException | Error ex) {con.rollback(); //回滚事务throw ex; //不要忽略,继续抛出,让ATM界面层报错
}数据库连接使用setAutoCommit(false)来开始一个事务,此所做的所有事情都是原子性事务的一部分,最后一件事情做完后,调用con.commit来提交事务。如果整个过程有任何异常发生,可以调用con.rollback()来撤销已经被执行的那部分修改。
数据库连接的自动提交默认为true,自动提交为true的意思就是每句SQL执行完成后,数据库都会自动根据成功与否来提交或回滚。这是毫无意义的,事务的原子性只有对多个操作而言才有意义,要么全部成功要么全部失败这句话本身就隐含整个过程还有多个SQL操作的意思。所谓,默认的自动提交也可以理解成无事务的意思。
一旦setAutoCommit(false);就表示数据库开启一个需要手动提交或回滚的事务,从这句话开始,一直往后,到最接近的commit或rollback调用的代码之间,所执行的任何SQL修改都作为一个不可分割的一个整体,那理论性点的话说,就是一个原子。原子中所有语句要么都成功,要么都失败。
特殊地,如果因为网络故障、客户端崩溃或者数据库本身崩溃而导致既没有commit也没有rollback。等数据库察觉到这个异常情况后,都视为rollback。
一旦commit或rollback之后,下一个的事务又自动开始了。当前事务的最终结果已经成事实了,板上钉钉了。更后面的提交或回滚的调用只针对下一个事务。从这里,你也可以往下延伸,即同一个connection 上可以执行多个事务,在connection close之前,你有多少个commit就代表你提交了多少个事务。
保存点
数据库事务回滚默认是整体回滚,即回滚到事务刚开始的地方,这样做是为了保证原子性。但数据库也提供一种故意破坏原子性的功能,叫做保存点(Save Point),保存点可以使用专用的SQL语句当前事务添加注册。事务开始后,添加保存点的SQL和操作数据的SQL可以任意混合地不断执行,但在当前事务范围内,各保存点的名称必须唯一,这样,多个保存点可以把很多个数据操作SQL的分成很多小段。最后可以使用指定一个保存点名称的rollback操作,这样,就可以回滚到添加那个保存点的SQL的位置,而不是默认的全部回滚。
数据库支持此功能,JDBC也支持暴露数据库的这个能力,所以大家还是有必要了解这个概念。但说实话,用得非常少,应用场景不多。
扁平事务和嵌套事务
对于所有数据库而言,针对一个连接,事务的扁平结构是默认结构,结束上一个事务隐含了下一个事务的开始。事务总是被开始、结束、开始、结束,同一时刻,一个连接顶多能开启一个事务。这种事务模型为扁平事务。
而对少数数据库而言,针对一个连接,事务总是被开始、开始、结束、结束,但可能需要该数据产品特有的特殊的SQL命令。这是开启了一个父事务和子事务,父事务和子事务各自遵循自己的原子性,双方的提交回滚彼此不干扰。这就是嵌套事务。这个概念,有点类似spring里面的Nested事务,但这里是数据库层面的,而且是针对同一个连接,对于绝大多数仅仅支持扁平事务的数据库而言,可以让当前线程创建两个不同的数据库连接,然后在两个不同的连接上各开启一个事务,属于不同连接的不同事务各自遵循自己的原子性,各自的提交回滚彼此不干扰。这是扁平事务数据库模拟嵌套事务的一个经典用法。也是事务传播属性里,require new和nested的实现原理。
数据库事务实现大致原理
以Oracle为例,Oracle数据都存储在表空间上,表空间里面有一个段,叫做Undo段,在一个事务中,所进行的所有增删改操作被实施之前,都先要按照严格的顺序在Undo段保持每条记录的旧数据(对于INSERT操作而言,旧数据为空),这样这对数据修改之前,Undo段就保证备份了所有被操作记录的原数据。如果最终被提交,清空Undo段中的数据,如果最终rollback,则按照Undo中事先备份好的原数据进行逆向操作,每完成一项逆向操作,就清除一部分Undo数据,最后全部回滚后,Undo段的数据也被清空了。
如果网络掉线或客户端崩溃,一定超时后,数据库能发现超时的“死链接”,数据库会清除死链接,并且解开死连接所持有的锁,并且根据和死连接相关联的Undo段数据开始逆向操作以撤销修改。
如果数据库本身崩溃、数据库所在操作系统奔溃、服务器硬件故障或者服务器停电导致数据库死掉。人工采取恢复措施(例如换主板、或想办法恢复电力供给)后重启数据库,刚重启的数据库会拒绝所有客户的连接申请,专心看储存介质上是否有Undo数据,如果有,开始撤销,每撤销一点就清除一点Undo数据。考虑更极端一点,如果在撤销了一部分后,数据库又出问题,那么大不了再重启一次再来,反正还没有被用于逆操作的Undo数据还在,当所有的Undo数据被全部清空后,意味着所有的未提交操作全部非法数据都被逆操作了。这是标志着数据库得以全部恢复,自此,数据库服务器才开始接受外界申请连接,进入正常的服务状态。
总之,只要存储数据的存储介质本身没有损坏,无论多极端的软件或硬件故障,数据库一定能回滚。而事实上,存储介质本身也很可能有硬件层面的有镜像容错能力,这就如虎添翼,更完美了。
Undo段故障
如果启动一个过于庞大的事务,事务开始之后到提交之前的修改行为过于海量,当会导致Oracle表空间Undo段所允许储存资源被耗尽,此时应用程序会得到异常。出现这个问题后,要仔细分析问题,辨别是应用程序写得太二(比如可以用小一点的事务实现同样的功能)还是数据库配置太二。最终决定由开发人员改应用程序还是由DBA改数据库软硬件设置。
事务隔离级别
上面所讲的事务的原子性,是对多条修改SQL具备意义。对于读操作,事务同样具备重大意义,这就是事务隔离级别
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
特别提醒,Oracle不支持此级别!在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少,但读取到的数据极其不靠谱。读取未提交的数据,可能前脚刚读到别人修改但未提交的数据,后脚数据就被别人回滚撤销了,自己读到了一份完全无效的数据还浑然不知,这种最无节操的问题称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。这个级别可以解决脏读(Dirty Read)的问题,一个事务只能看见已经提交事务所做的改变,如果其它事务反复修改数据,当前事务多次读取同一条数据每次会读到不同的数据,这种现象叫做不可重复读(Nonrepeatable Read)。
Repeatable Read(可重读)
特别提醒,Oracle不支持此级别!这是MySQL的默认事务隔离级别。这个级别可以解决不可重复读的(Nonrepeatable Read)问题。它确保同一事务的多次同一条数据的时候,每次会看到同样的数据行。 但是其它事务任然还是可以添加和删除同一张表的其它数据,导致当前事务反复看这张表的记录总条数,有时变多有时变少,就如同看街上闪烁的霓虹灯一样,这种问题叫做幻读(Phantom Read)
Serializable(串行化读)
这是最高的隔离级别,连幻读(Phantom Read)问题也被解决了。所有企图操作同一张表(无论读写)的事务必须割舍掉所有并发性,串行化地排队。对一张表而言,此级别完全不具备任何并发性,读取到的数据绝对可靠。
隔离级别表格总结
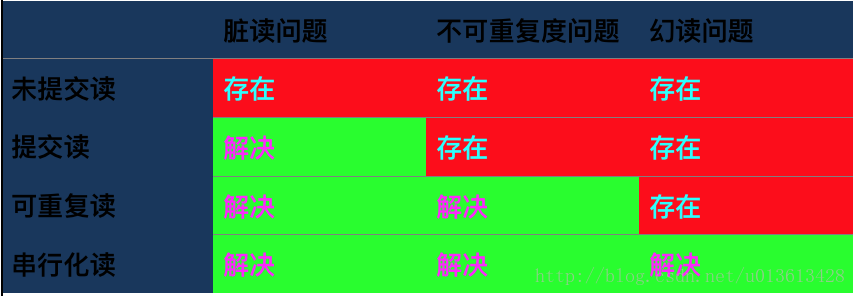
越靠上,读取到的数据越不严密,但并发度越高。
越靠下,读取到的数据越严密,但并发度越低下。
典型的鱼和熊掌难以兼得的问题,就连数据库制造商自己都觉得难以取舍,就给了这个4档变速箱,开发人员根据实际路况(项目具体情况)自己选。
隔离级别基本原理
由于部分数据库对4种级别支持得未必全,比如Oracle就仅仅支持两个级别,而且每种数据库的实现细节会稍微有所差异,所以我们讲解一种理论上最简实现原理。实际数据库实现完整隔离级别的原理只能比这个模型更复杂,不能更简单。








