您现在的位置是:主页 > news > 网站模板修改软件/seo免费推广软件
网站模板修改软件/seo免费推广软件
![]() admin2025/5/16 15:12:06【news】
admin2025/5/16 15:12:06【news】
简介网站模板修改软件,seo免费推广软件,成都住建局官网报名入口,动易的网站系统算法融合: 1、基于word2vec的词语相似度计算模型2、标签别名语义相似度匹配算法 本算法是两种算法融合产生的效果,效果还不错: # -*- encodingutf-8 -*-# 载包 from gensim.models import Word2Vec import warnings warnings.filterwarnin…
网站模板修改软件,seo免费推广软件,成都住建局官网报名入口,动易的网站系统算法融合:
1、基于word2vec的词语相似度计算模型2、标签别名语义相似度匹配算法
本算法是两种算法融合产生的效果,效果还不错:
# -*- encodingutf-8 -*-# 载包
from gensim.models import Word2Vec
import warnings
warnings.filterwarnin…
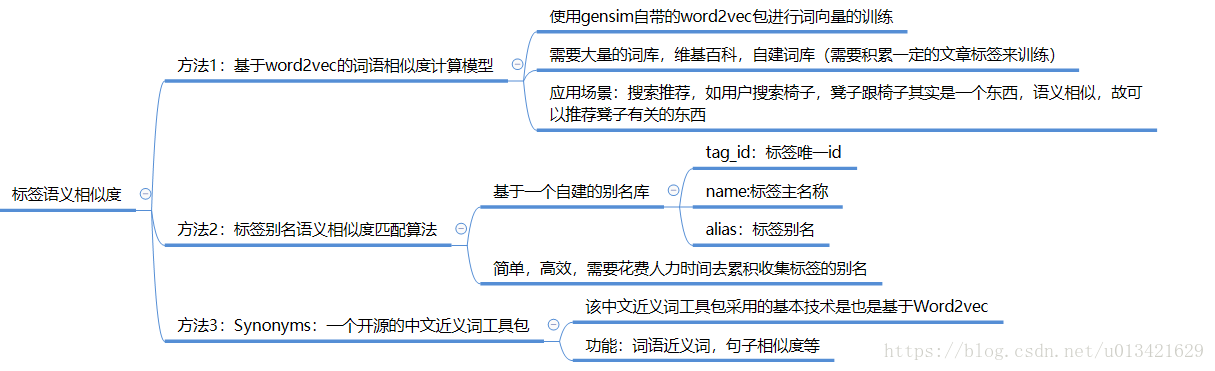
算法融合:
- 1、基于word2vec的词语相似度计算模型
- 2、标签别名语义相似度匹配算法
本算法是两种算法融合产生的效果,效果还不错:
# -*- encoding=utf-8 -*-# 载包
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings(action='ignore',category=UserWarning,module='gensim')
from itertools import combinations
import pandas as pd
import time
time1=time.time()# 加载word2vec训练好的模型model = Word2Vec.load("F:/下载/content/word_embedding_20180907")# 加载别名数据集data0 = pd.read_excel('C:/Users/xiaohu/Desktop/文本挖掘/标签语义相近发现合并算法/data/kktribe_tag_1.xlsx')# 自定义获取近义词函数
def get_most_similar_list(string1):# 使用模型try:items = model.most_similar(string1)key=[]value=[]for i, j in items:# print(i, j)key.append(i)value.append(j)result=pd.DataFrame({"key":key,"value":value})print(result)except:print('找不到该单词的近义词!')passreturn result#定义一个标签有别名的合并函数def combine_tag_name_alis(data1,data2):""":param data1: 别名集:param data2:标签集:return: 合并后的结果集"""# 筛选数据,找到有别名的标签data3 = data1[data1['alias'].isin(data2['key'])]data4=data2[~data2['key'].isin(data3['alias'])]#语义相似标签去重name1= list(set(data3['name']))name2=list(set(data4['key']))name3=name1+name2name4=list(set(name3))return name4# 自定义标签去重函数def get_similarity(data2):data3 = set(data2['key'])tag_drop_list = []# 计算两个词语相似度for i, j in combinations(data3, 2):try:similary = model.similarity(i, j)# print(i, j, similary)# 如果两个词语相似度>0.6,则合并为一个词语if similary >0.75:print(i,j,similary)if len(i) < len(j):tag_drop_list.append(i)if len(i) > len(j):tag_drop_list.append(j)if len(i) == len(j):tag_drop_list.append(i)else:m1 = set([i, j])new_data = pd.DataFrame({'key': [i, j]})# 合并之后的标签集name = combine_tag_name_alis(data0, new_data)# print(name)if len(name) == 1:m2 = namem2 = set(m2)m3 = (m1 - m2)m3_1 = m3.pop()tag_drop_list.append(m3_1)except:m1=set([i,j])new_data = pd.DataFrame({'key': [i,j]})# 合并之后的标签集name = combine_tag_name_alis(data0, new_data)# print(name)if len(name)==1:m2=namem2=set(m2)m3=(m1-m2)m3_1=m3.pop()tag_drop_list.append(m3_1)# print(tag_drop_list)# 集合删除找出的相似词data4 =set(tag_drop_list)data5 = data3 - data4print("最终结果集:")# print(data5)return data5if __name__ == '__main__':# 读取标签数据集data2 = pd.DataFrame({'key': ['詹皇', '小皇帝','辣鸡','垃圾','高倍','高赔','詹姆斯','竞彩足球','C罗','总裁']})result=get_similarity(data2)print(result)詹皇 詹姆斯 0.8157515026814683
垃圾 辣鸡 0.9018741525236081
高赔 高倍 0.7765882760905136
最终结果集:
{'辣鸡', '詹姆斯', 'C罗', '高倍', '竞彩足球'}Process finished with exit code 0







