您现在的位置是:主页 > news > 局网站建设/朝阳网站seo
局网站建设/朝阳网站seo
![]() admin2025/5/15 10:36:47【news】
admin2025/5/15 10:36:47【news】
简介局网站建设,朝阳网站seo,做企业网站选百度云还是阿里云,廊坊做网站的公司Main函数的最佳实践既然您已经了解两种执行方式上的差异,那么掌握一些最佳实践方案还是很有用的。它们将适用于编写作为脚本运行的代码或者在另一个模块导入的代码。如下是四种实践方式:将大部分代码放入函数或类中。使用__name__控制代码的执行。创建名…

Main函数的最佳实践
既然您已经了解两种执行方式上的差异,那么掌握一些最佳实践方案还是很有用的。它们将适用于编写作为脚本运行的代码或者在另一个模块导入的代码。
如下是四种实践方式:
将大部分代码放入函数或类中。
使用__name__控制代码的执行。
创建名为main()的函数来包含要运行的代码。
在main()中调用其他函数。
将大部分代码放入函数或类中
请记住,Python解释器在导入模块时会执行模块中的所有代码。有时如果想要实现用户可控的代码,会导致一些副作用,例如:
运行计算时间过长的程序
将文件写入磁盘
打印会扰乱用户终端的信息
在这种情况下,想要实现用户控制触发此代码的执行,而不是让Python解释器在导入模块时执行代码。
因此,最佳方法是将大部分代码包含在函数或类中。这是因为当Python解释器遇到def或class关键字时,它只存储这些定义供以后使用,并且在用户通知之前不会实际执行。
将如下代码保存在best_practices.py以证明这个想法:
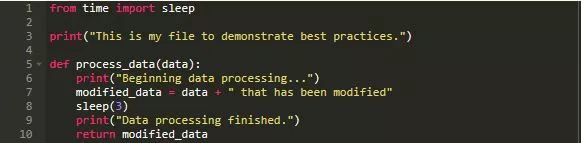
在此代码中,首先从time模块中导入sleep()。
在这个示例中,参数以秒的形式传入sleep()函数中,解释器将暂停一段时间再运行。随后,使用print()函数打印关于代码描述的语句。
之后,定义一个process_data()函数,执行如下五项操作:
打印一些输出信息以通知用户数据处理正在启动
修改输入数据
暂停执行3秒sleep()函数
打印一些输出信息以通知用户处理已完成
返回修改后的数据
在命令行中执行
当你将此文件作为脚本用命令行执行时会发生什么呢?
Python解释器将执行函数定义之外的from time import sleep和print(),之后将创建函数process_data()。然后,脚本将退出而不做任何进一步的操作,因为脚本没有任何执行process_data()的代码。
如下是这段脚本的执行结果:

我们在这里看到的输出是第一个print()的结果。注意,从time导入和定义process_data()函数不产生结果。具体来说,调用定义在process_data()内部的print()不会打印结果。
导入模块或解释器执行
在会话(或其他模块)中导入此文件时,Python解释器将执行相同的步骤。
Python解释器导入文件后,您可以使用已导入模块中定义的任何变量,类或函数。为了证明这一点,我们将使用可交互的Python解释器。启动解释器,然后键入import best_practices:

导入best_practices.py后唯一的输出来自process_data()函数外定义的print()。导入模块或解释器执行与基于命令行执行类似。
使用__name__控制代码的执行
如何实现基于命令行而不使用Python解释器导入文件来执行呢?
您可以使用__name__来决定执行上下文,并且当__name__等于"__main__"时才执行process_data()。在best_practices.py文件中添加如下代码:

这段代码添加了一个条件语句来检验__name__的值。当值为"__main__"时,条件为True。记住当__name__变量的特殊值为"__main__"时意味着Python解释器会执行脚本而不是将其导入。
条件语块内添加了四行代码(第12,13,14和15行):
第12和13行:创建变量data,用于存储从Web获取的数据并打印。
第14行:处理数据。
第15行:打印修改后的数据。
现在,在命令行中运行best_practices.py,并观察输出的变化:

首先,输出显示了process_data()函数外的print()的调用结果。
之后,data的值被打印。因为当Python解释器将文件作为脚本执行时,变量__name__具有值"__main__",因此条件语句被计算为True。
接下来,脚本将调用process_data()并传入data进行修改。当process_data执行时,将输出一些状态信息。最终,将输出modified_data的值。
现在您可以验证从解释器(或其他模块)导入best_practices.py后发生的事情了。如下示例演示了这种情况:

注意,当前结果与将条件语句添加到文件末尾之前相同。因为此时__name__变量的值为"best_practices",因此条件语句结果为False,Python将不执行process_data()。
英文原文:https://realpython.com/python-main-function/
译者:我是昵称耶~








