您现在的位置是:主页 > news > 网站内容批量替换/百度最新版本2022
网站内容批量替换/百度最新版本2022
![]() admin2025/5/14 3:35:44【news】
admin2025/5/14 3:35:44【news】
简介网站内容批量替换,百度最新版本2022,自己搞个网站需要多少钱,吉林建设监理协会网站Mysql版本:8.0.26 可视化客户端:sql yog 编译软件:IntelliJ IDEA 2019.2.4 x64 运行环境:win10 家庭中文版 jdk版本:1.8.0_361 目录一、DAO是什么?二、案例演示2.1 准备数据2.2 创建bean包2.3 建立DAO包2.2…
Mysql版本:8.0.26
可视化客户端:sql yog
编译软件:IntelliJ IDEA 2019.2.4 x64
运行环境:win10 家庭中文版
jdk版本:1.8.0_361
目录
- 一、DAO是什么?
- 二、案例演示
- 2.1 准备数据
- 2.2 创建bean包
- 2.3 建立DAO包
- 2.2.1 建立BaseDAOImpl类
- 2.2.2 建立部门DAO接口及其实现类
- 2.2.3 建立员工DAO接口及其实现类
- 2.4 建立JDBCTools工具类
- 2.4.1 JDBCTools1.0
- 2.4.2 JDBCTools2.0
- 2.5 代码结构分析
- 2.6 测试结果演示
- 2.6.1 测试部门DAO实现类
- 三、Dbutils优化代码
- 3.1 Dbutils简介
- 3.2 如何使用Dbutils?
- 3.3 BaseDAOImply优化版
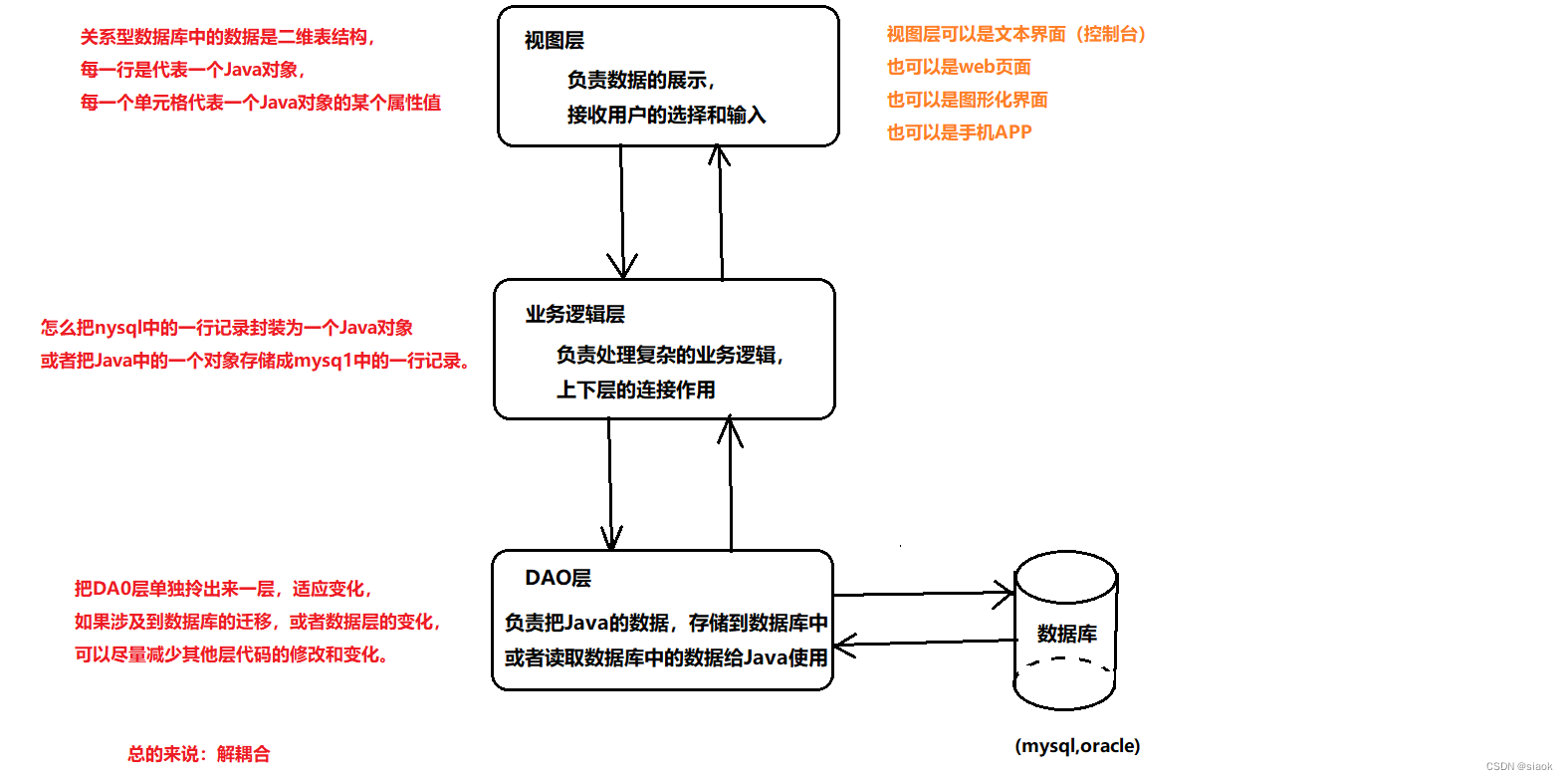
一、DAO是什么?
众所周知,Java是面向对象语言,数据在Java中通常是以对象的形式存在。而在数据库中,它的每张数据表我们可以视作是Java中的一个个类,而表的每一行记录和相应的字段,便可视作是一个个的对象和对象的属性。相应地字段值,便是对象的属性值。反之,Java的对象也可看作是数据库中数据表的每一行记录,而Java对象的属性名和属性值,就是记录的字段名和相应的字段值。
当Java程序通过JDBC与数据库交互时,我们把涉及
访问数据库的代码封装起来,这些类称为DAO,英文全称为Data Access Object。它相当于是一个数据访问接口,夹在业务逻辑与数据库资源中间,这样使得代码结构更加清晰、易于维护和扩展。
如下图所示:
二、案例演示
案例:尝试连接数据库0225db,以DAO层的封装思想的形式进行编码,访问部门表与员工表,实现增删改查相应的功能
2.1 准备数据
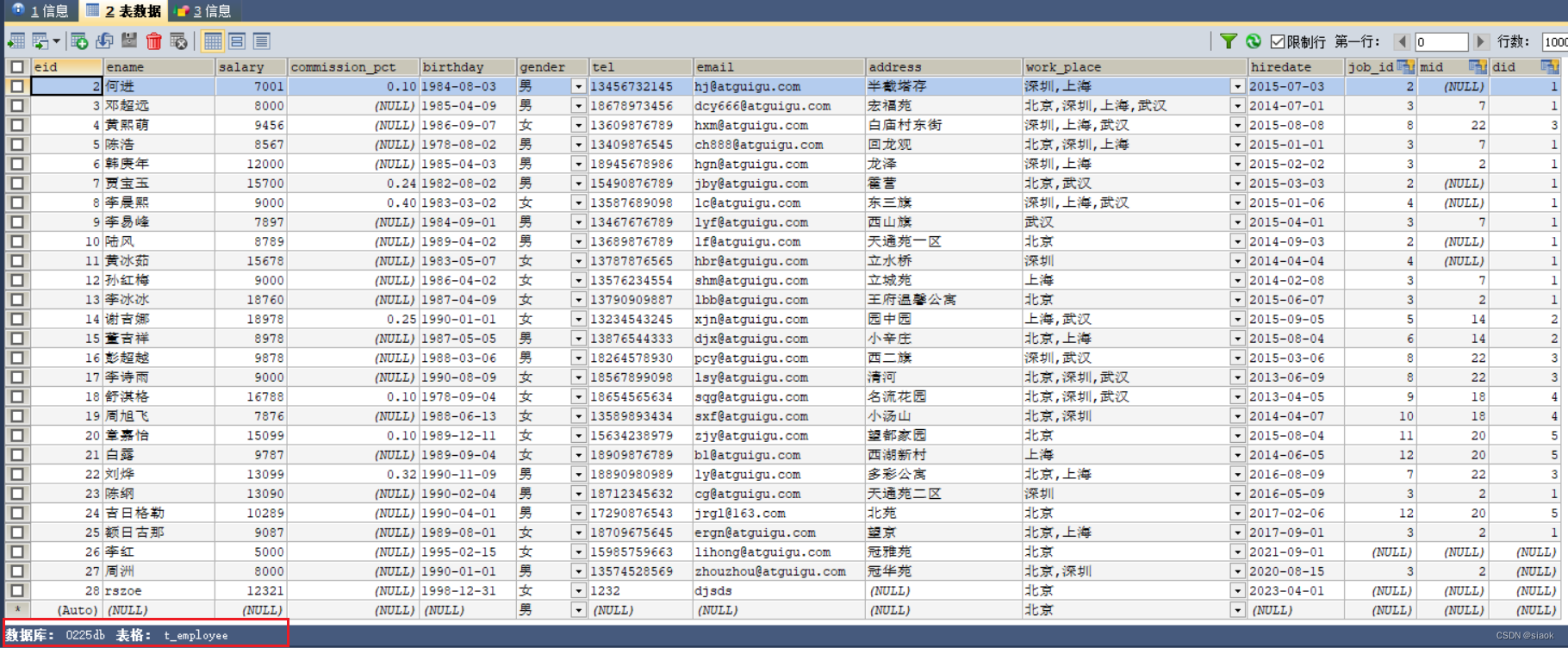
①建立员工表t_employee
Create TableCREATE TABLE `t_employee` (`eid` int NOT NULL AUTO_INCREMENT COMMENT '员工编号',`ename` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '员工姓名',`salary` double NOT NULL COMMENT '薪资',`commission_pct` decimal(3,2) DEFAULT NULL COMMENT '奖金比例',`birthday` date NOT NULL COMMENT '出生日期',`gender` enum('男','女') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '男' COMMENT '性别',`tel` char(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '手机号码',`email` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '邮箱',`address` varchar(150) DEFAULT NULL COMMENT '地址',`work_place` set('北京','深圳','上海','武汉') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '北京' COMMENT '工作地点',`hiredate` date NOT NULL COMMENT '入职日期',`job_id` int DEFAULT NULL COMMENT '职位编号',`mid` int DEFAULT NULL COMMENT '领导编号',`did` int DEFAULT NULL COMMENT '部门编号',PRIMARY KEY (`eid`),KEY `job_id` (`job_id`),KEY `did` (`did`),KEY `mid` (`mid`),CONSTRAINT `t_employee_ibfk_1` FOREIGN KEY (`job_id`) REFERENCES `t_job` (`jid`) ON DELETE SET NULL ON UPDATE CASCADE,CONSTRAINT `t_employee_ibfk_2` FOREIGN KEY (`did`) REFERENCES `t_department` (`did`) ON DELETE SET NULL ON UPDATE CASCADE,CONSTRAINT `t_employee_ibfk_3` FOREIGN KEY (`mid`) REFERENCES `t_employee` (`eid`) ON DELETE SET NULL ON UPDATE CASCADE,CONSTRAINT `t_employee_chk_1` CHECK ((`salary` > 0)),CONSTRAINT `t_employee_chk_2` CHECK ((`hiredate` > `birthday`))
) ENGINE=InnoDB AUTO_INCREMENT=29 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
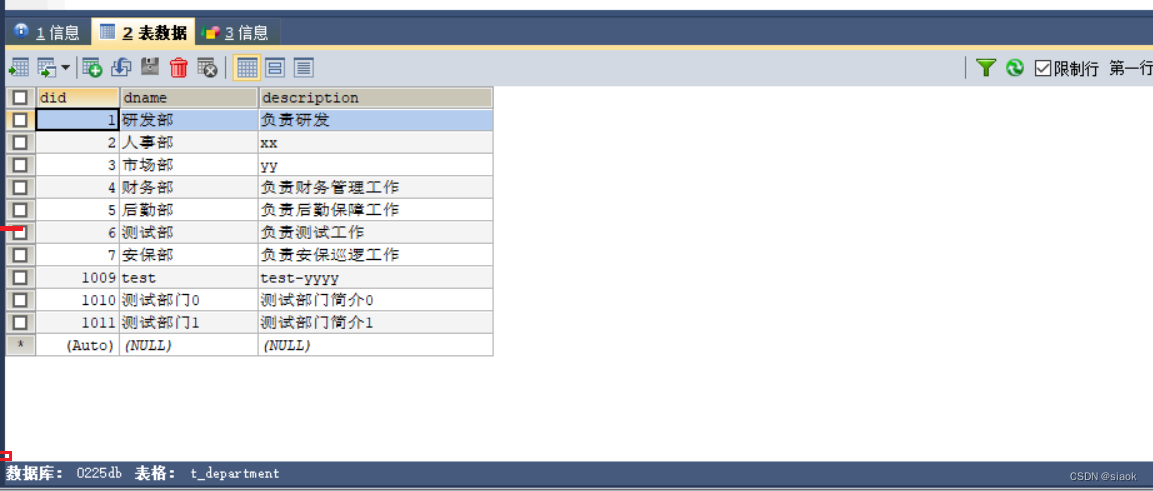
②建立部门表t_department
CREATE TABLE `t_department` (`did` int NOT NULL AUTO_INCREMENT COMMENT '部门编号',`dname` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '员工名称',`description` varchar(200) DEFAULT NULL COMMENT '员工简介',PRIMARY KEY (`did`),UNIQUE KEY `dname` (`dname`)
) ENGINE=InnoDB AUTO_INCREMENT=1012 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
2.2 创建bean包
目的:
创建两个类用于封装从t_employee和t_department拿过来的每一行记录
代码演示如下:
①创建department类,用于封装从t_department拿过来的每一行记录,同时一个department类的对象可以写入t_department表里
public class department {private Integer did;private String dname;private String description;public department() {}public department(int did) {this.did = did;}public department(int did, String dname, String description) {this.did = did;this.dname = dname;this.description = description;}public department(String dname, String description) {this.dname = dname;this.description = description;}public int getDid() {return did;}public void setDid(int did) {this.did = did;}public String getDname() {return dname;}public void setDname(String dname) {this.dname = dname;}public String getDescription() {return description;}public void setDescription(String description) {this.description = description;}@Overridepublic String toString() {return "department{" +"did=" + did +", dname='" + dname + '\'' +", description='" + description + '\'' +'}';}
}②创建employee类,用于封装从t_employee拿过来的每一行记录,同时一个employee类的对象可以写入t_employee表里
import java.math.BigDecimal;
import java.util.Date;public class employee {private Integer eid;private String ename;private Double salary;private BigDecimal commissioPct;private Date birthday;private String gender;private String tel;private String email;private String address;private String workPlace="北京";private Date hiredate;private Integer jobId;private Integer mid;private Integer did;public employee() {}public employee(Integer eid) {this.eid = eid;}public employee(String ename, Double salary, BigDecimal commissioPct, Date birthday, String gender, String tel, String email, String address, String workPlace, Date hiredate, Integer jobId, Integer mid, Integer did) {this.ename = ename;this.salary = salary;this.commissioPct = commissioPct;this.birthday = birthday;this.gender = gender;this.tel = tel;this.email = email;this.address = address;this.workPlace = workPlace;this.hiredate = hiredate;this.jobId = jobId;this.mid = mid;this.did = did;}public employee(Integer eid, String ename, Double salary, BigDecimal commissioPct, Date birthday, String gender, String tel, String email, String address, String workPlace, Date hiredate, Integer jobId, Integer mid, Integer did) {this.eid = eid;this.ename = ename;this.salary = salary;this.commissioPct = commissioPct;this.birthday = birthday;this.gender = gender;this.tel = tel;this.email = email;this.address = address;this.workPlace = workPlace;this.hiredate = hiredate;this.jobId = jobId;this.mid = mid;this.did = did;}public Integer getEid() {return eid;}public void setEid(Integer eid) {this.eid = eid;}public String getEname() {return ename;}public void setEname(String ename) {this.ename = ename;}public Double getSalary() {return salary;}public void setSalary(Double salary) {this.salary = salary;}public BigDecimal getCommissioPct() {return commissioPct;}public void setCommissioPct(BigDecimal commissioPct) {this.commissioPct = commissioPct;}public Date getBirthday() {return birthday;}public void setBirthday(Date birthday) {this.birthday = birthday;}public String getGender() {return gender;}public void setGender(String gender) {this.gender = gender;}public String getTel() {return tel;}public void setTel(String tel) {this.tel = tel;}public String getEmail() {return email;}public void setEmail(String email) {this.email = email;}public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}public String getWorkPlace() {return workPlace;}public void setWorkPlace(String workPlace) {this.workPlace = workPlace;}public Date getHiredate() {return hiredate;}public void setHiredate(Date hiredate) {this.hiredate = hiredate;}public Integer getJobId() {return jobId;}public void setJobId(Integer jobId) {this.jobId = jobId;}public Integer getMid() {return mid;}public void setMid(Integer mid) {this.mid = mid;}public Integer getDid() {return did;}public void setDid(Integer did) {this.did = did;}@Overridepublic String toString() {return "employee{" +"eid=" + eid +", ename='" + ename + '\'' +", salary=" + salary +", commission_pct=" + commissioPct +", birthday=" + birthday +", gender='" + gender + '\'' +", tel='" + tel + '\'' +", email='" + email + '\'' +", address='" + address + '\'' +", work_place='" + workPlace + '\'' +", hiredate=" + hiredate +", job_id=" + jobId +", mid=" + mid +", did=" + did +'}';}
}2.3 建立DAO包
2.2.1 建立BaseDAOImpl类
目的:
基本上每一个数据表都应该有一个对应的DAO接口及其实现类,发现对所有表的操作(增、删、改、查)代码重复度很高,所以可以抽取公共代码,给这些DAO的实现类可以抽取一个公共的父类,称为BaseDAOImpl。该类包含通用的增删改查的方法。
代码演示如下:
import util.JDBCTools;
import util.JDBCTools2;import java.lang.reflect.Field;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;public abstract class BaseDAOImpl {//通用的曾,删,改操作//sql中包含? 参数,需要设置?的值//如果sgL中没有?,那么调用这个方法时,不用传args对应的实参// 如果sgL中有5个?,那么调用这个方法时,要给args传入对应的5个实参//实现流程 : java程序 ----> mysql数据库中的数据表public int update(String sql,Object ...args) throws SQLException {//连接数据库,类似于网络编程中的socket//使用JDBCTools(1.0)获取的连接对象Connection conn = JDBCTools.getConnection();//使用JDBCTools2(2.0)获取的连接对象// Connection conn = JDBCTools2.getConnection();//将sql语句预编译PreparedStatement pst = conn.prepareStatement(sql);if (args!=null && args.length>0) {for (int i = 0; i < args.length; i++) {pst.setObject(i+1,args[i]);//设置?的值}}int len= pst.executeUpdate();//执行sql语句并返回同步更新的记录条数//释放连接
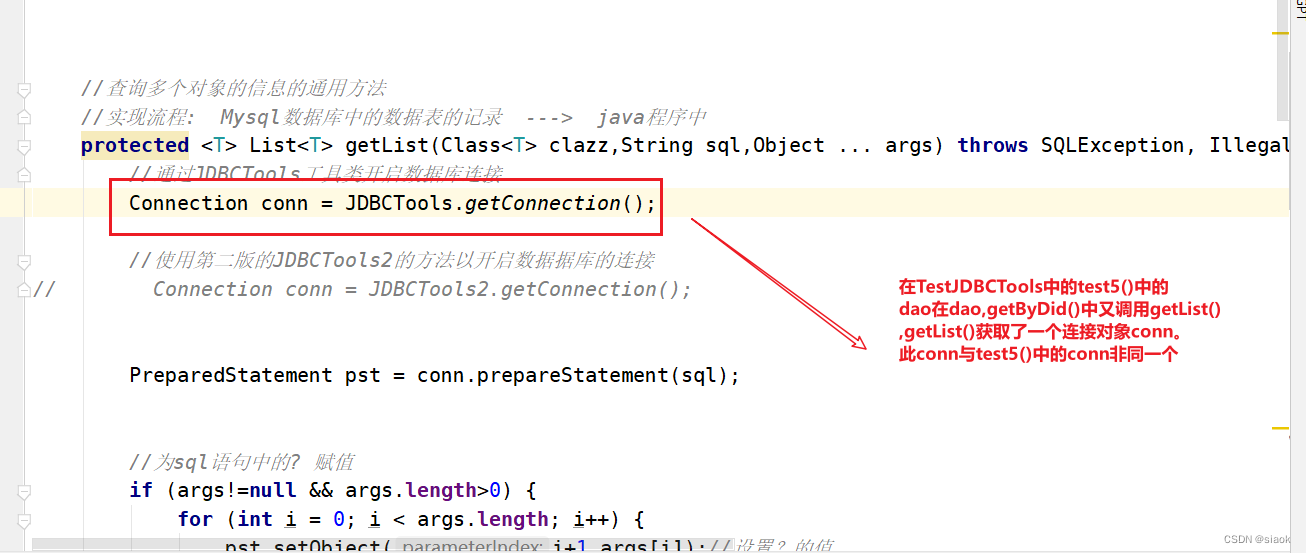
// JDBCTools.freeConnection(conn);return len;}//查询多个对象的信息的通用方法//实现流程: Mysql数据库中的数据表的记录 ---> java程序中protected <T> List<T> getList(Class<T> clazz,String sql,Object ... args) throws SQLException, IllegalAccessException, InstantiationException, NoSuchFieldException { //泛型方法//通过JDBCTools工具类开启数据库连接//使用JDBCTools(1.0)获取的连接对象Connection conn = JDBCTools.getConnection();//使用第二版的JDBCTools2(2.0)的方法以开启数据据库的连接// Connection conn = JDBCTools2.getConnection();PreparedStatement pst = conn.prepareStatement(sql);//为sql语句中的? 赋值if (args!=null && args.length>0) {for (int i = 0; i < args.length; i++) {pst.setObject(i+1,args[i]);//设置?的值}}//从数据库中查到的表t_department的数据返回来是个结果集ResultSet resultSet = pst.executeQuery();//装从结果集遍历得到的对象List<T> list =new ArrayList<>();//得到结果集中的元数据对象【元数据:描述数据的数据】,取数据表中每一个字段名的名称,同样它返回的是元数据对象的结果集,一个表的元数据绝大数是多个,而非一个ResultSetMetaData metaData = resultSet.getMetaData();//得到元数据对象的结果集的列数,即有多少个元数据int columnCount = metaData.getColumnCount();//遍历结果集while (resultSet.next()){ //每一行是一个对象//利用反射来确定每一行对象的类型,但是反射的class对象,我们并不知道,所以希望别人传参告诉我们T t = clazz.newInstance();//通过Class对象的newInsatnce()得到类的实例化对象for (int i = 1; i <= columnCount ; i++) {//得到每一行的某一列,value是t对象的属性的值Object value = resultSet.getObject(i);//获取结果集中第i列的值//结果集中第i列的列名称恰好对于T类中的属性
// String columnName = metaData.getColumnClassName(i);//获取元数据结果集中的第i列的列名称String columnName = metaData.getColumnLabel(i);//获取元数据结果集中的第i列的列名称,如果指定了列的别名,就用别名//Class对象根据列名称找到对应类类型的类的某个属性Field field = clazz.getDeclaredField(columnName);field.setAccessible(true);field.set(t,value);//设置t对象的field属性值}list.add(t);}//释放连接
// JDBCTools.freeConnection(conn);
// JDBCTools2.freeConnection();/这里不关闭连接,交给事务提交或回滚之后再去关闭连接return list;}//查询一个对象(一条记录)的通用方法protected <T> T getBean(Class<T> clazz,String sql,Object ... args) throws SQLException, NoSuchFieldException, InstantiationException, IllegalAccessException {List<T> list = getList(clazz, sql, args);if(list!=null && list.size()>0){return list.get(0);}return null;}}
2.2.2 建立部门DAO接口及其实现类
①在DAO包中建立部门DAO接口
代码演示如下:
import bean.department;import java.util.List;public interface DepartmentDAO {//根据部门编号修改一个部门信息boolean addDepartment(department d);//根据部门编号删除一个部门信息boolean removeDepart(department d);//根据部门编号修改部门的信息boolean updateDepartment(department d);//查询所有的部门信息List<department> getAllDepartment();//根据部门编号查询一个部门的信息department getBydid(int did);}
②在DAO包中建立部门DAO接口的实现类
代码演示如下:
import bean.department;import java.sql.SQLException;
import java.util.List;public class DepartmentDAOlmpl extends BaseDAOImpl implements DepartmentDAO {@Override//添加记录public boolean addDepartment(department d) {String sql="INSERT INTO t_department VALUES(null,?,?)";try {int len = update(sql,d.getDname(),d.getDescription());return len>0;} catch (SQLException e) {//目的:不希望其他层出现sql exception,只希望在本层有异常就抛出,这时只需要在DAO层try了//该sql exception是编译异常,需要转换为运行时异常throw new RuntimeException(e);}}@Override//删除记录public boolean removeDepart(department d) {String sql="delete from t_department where did=?";try {int len =update(sql,d.getDid());return len>0;} catch (SQLException e) {throw new RuntimeException(e);}}@Override//更新记录public boolean updateDepartment(department d) {//下列update的sql是通过did作为条件定位更改对于的记录行的字段值String sql="UPDATE t_department SET dname=?, description=? WHERE did=?";try {int len=update(sql,d.getDname(),d.getDescription(),d.getDid());return len>0;} catch (SQLException e) {throw new RuntimeException(e);}}@Override//查询所有记录public List<department> getAllDepartment() {String sql="select * from t_department";try {return getList(department.class, sql);} catch (Exception e) {throw new RuntimeException(e);}}@Override//查询单个记录public department getBydid(int did) {String sql="select * from t_department where did=?";try {return getBean(department.class,sql,did);} catch (Exception e) {throw new RuntimeException(e);}}
}
2.2.3 建立员工DAO接口及其实现类
①在DAO包中建立员工DAO接口
代码演示如下:
import bean.employee;import java.util.List;public interface EmployeeDAO {//实现在t_employee中增加记录并判断实现结果(即是不是真的在表中增加了记录)boolean addEmployee(employee e);//实现在t_employee中删除记录并判断实现结果boolean removeEmployee(employee e);//实现在t_employee中修改记录并判断实现结果boolean updateEmployee(employee e);//实现在t_employee中查询所有记录并判断实现结果List<employee> getAllEmployee();//实现在t_employee中查询指定的一行记录并判断实现结果employee getBydid(int did);}
②在DAO包中建立员工DAO接口的实现类
代码演示如下:
import bean.employee;import java.sql.SQLException;
import java.util.List;public class EmployeeDAOImpl extends BaseDAOImpl implements EmployeeDAO {@Override//添加记录public boolean addEmployee(employee e) {String sql="INSERT INTO t_employee(eid,ename,salary,commission_pct,birthday,gender,tel," +"email,address,work_place,hiredate,job_id,`mid`,did) VALUES(NULL, ?, ? " +", ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";try {int update = update(sql, e.getEname(), e.getSalary(), e.getCommissioPct(), e.getBirthday(), e.getGender(), e.getTel(),e.getEmail(), e.getAddress(), e.getWorkPlace(), e.getHiredate(), e.getJobId(), e.getMid(), e.getDid());return update>0;} catch (Exception ex) {//目的:不希望在其他层出现sql exception,只需要在DAO层try了//将编译异常转换为运行时异常throw new RuntimeException(ex);}}@Override//删除记录public boolean removeEmployee(employee e) {String sql="DELETE FROM t_employee WHERE eid= ?";try {int len = update(sql, e.getEid());return len>0;} catch (SQLException ex) {throw new RuntimeException(ex);}}@Override//更新记录public boolean updateEmployee(employee e) {String sql="UPDATE t_employee SET ename=?,salary=?,commission_pct=?,birthday=?,gender=?," +"tel=?,email=?,address=?,work_place=?,hiredate=?,job_id=?,`mid`=?,did=?" +"WHERE did=?";try {int update = update(sql, e.getEname(), e.getSalary(), e.getCommissioPct(), e.getBirthday(), e.getGender(), e.getTel(),e.getEmail(), e.getAddress(), e.getWorkPlace(), e.getHiredate(), e.getJobId(), e.getMid(), e.getDid());return update>0;} catch (Exception ex) {//目的:不希望在其他层出现sql exception,只需要在DAO层try了//将编译异常转换为运行时异常throw new RuntimeException(ex);}}@Override//查询多个记录public List<employee> getAllEmployee() {// java.lang.RuntimeException: java.lang.NoSuchFieldException: commission_pct/*解决方案:1.给commission_pct AS commissionPct 取别名2.在BaseDAOImpl类的通用的查询方法中,获取字段名的方法要处理String columnName = metaData.getColumnName(i);//获取第i列的列名称换成String columnNgme = metaData.getColumnLabel(i)://获第列的列名称或别名,如果指定了别名就按照别名来处理*/String sql="SELECT `eid`,`ename`,`salary`,`commission_pct` AS commissioPct,`birthday`,`gender`,\n" +"`tel`,`email`,`address`,`work_place` AS workPlace,`hiredate`,`job_id` AS jobId,`mid`,`did` from t_employee" ;try {return getList(employee.class, sql);} catch (Exception e) {throw new RuntimeException(e);}}@Override//查询单个记录public employee getBydid(int eid) {String sql="SELECT `eid`,`ename`,`salary`,`commission_pct` AS commissioPct,`birthday`,`gender`,\n" +"`tel`,`email`,`address`,`work_place` AS workPlace,`hiredate`,`job_id` AS jobId,`mid`,`did`\n" +"FROM t_employee\n" +"WHERE eid= ?;";try {return getBean(employee.class,sql,eid);} catch (Exception e) {throw new RuntimeException(e);}}
}2.4 建立JDBCTools工具类
目的:
凡涉及对数据库的操作(增、删、改、查),都需要先获取数据库连接,数据库连接可以通过DriverManager工具类获取,也可以从数据库连接池中获取。所以
把数据库连接对象的获取和释放封装到此类中。
2.4.1 JDBCTools1.0
注意:
JDBCTools1.0版本不能处理事务问题,有缺陷。
JDBCTools1.0 原版代码如下所示:
import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;public class JDBCTools {//思考:为什么dataSource后面不写代码,只是声明,// 因为它不是简单的new对象,数据库连接池的创建之前要涉及很多代码,只能用静态代码块来实现private static DataSource dataSource;static {Properties properties=new Properties();try {/*properties.load()里是要放输入流对象,那为何不直接放“druid.properties”的路径在其中?"properties.load(new FileInputStream(new File("druid.properties")))"不能这样写,写它的相对路径,在main方法里会默认在项目根目录下去找,找不到会报异常,test方法下会默认在该模块下去寻找,找不到会报异常写相对路径不行,那写该文件的绝对路径?不合适因为后期在部署web项目,不会这样写,后期在tomcat服务器上访问web项目时,不是在本地项目中src下找该文件,而是通过访问部署在服务器上的war包【本地web项目经过编译后的压缩包】)这时用类加载器去获取druid.properties,就比较合适,不容易出现问题*/properties.load(JDBCTools.class.getClassLoader().getResourceAsStream("druid.properties"));//getResourceAsStream() 返回读取指定资源的输入流//properties.load()读取配置文件中的数据dataSource= DruidDataSourceFactory.createDataSource(properties);//创建连接池} catch (Exception e) {e.printStackTrace();}}//在连接池中获取连接对象public static Connection getConnection() throws SQLException {return dataSource.getConnection();}//释放连接对象并归还至连接池中public static void freeConnection(Connection conn) throws SQLException {if (conn!=null){conn.setAutoCommit(true);//每次丢连接对象到连接池之前,都要把数据库设为自动提交模式conn.close();//丢进连接池}}
}修改之前的部门表:

测试JDBCTools1.0的代码如下演示:
//模拟触发事务问题
import Dao.DepartmentDAOlmpl;
import bean.department;
import org.junit.Test;
import util.JDBCTools;import java.sql.Connection;
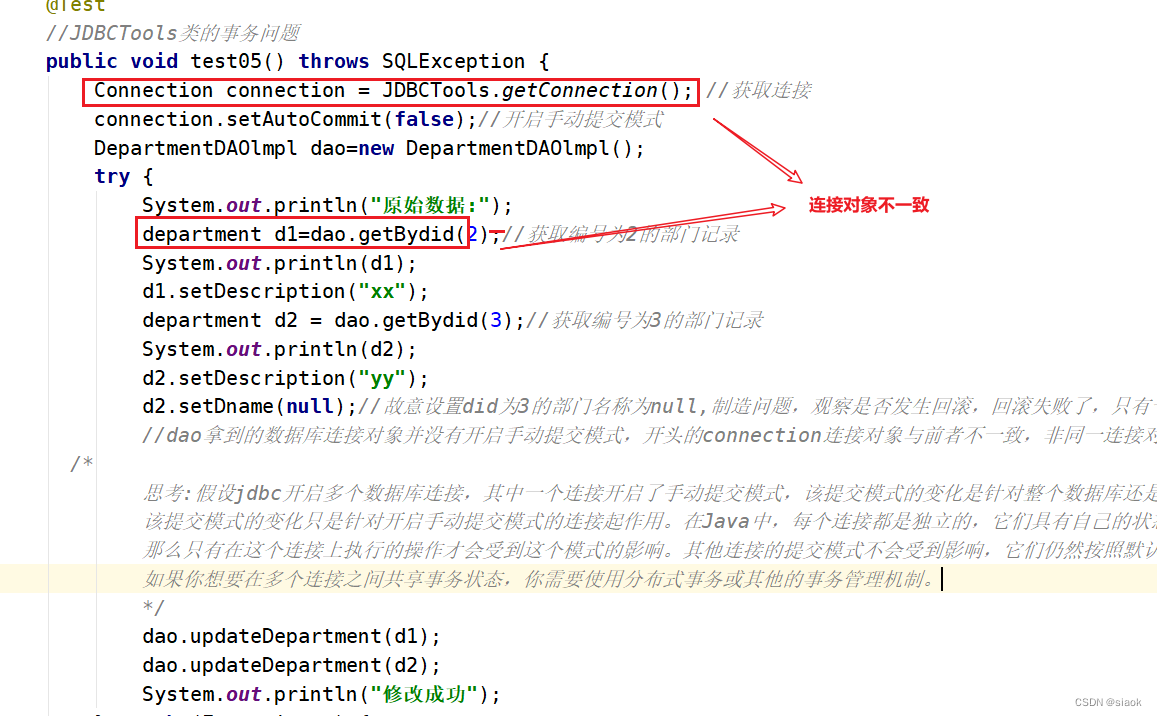
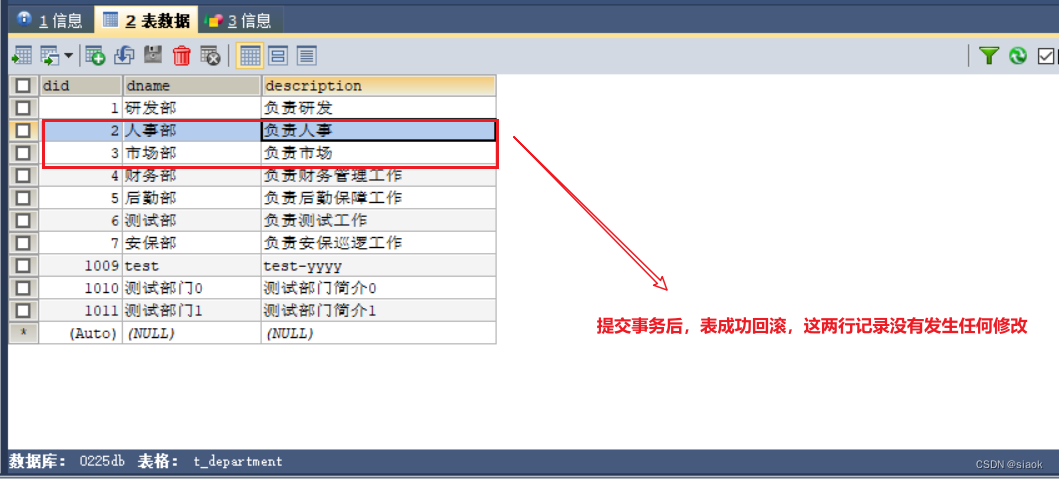
import java.sql.SQLException;public class TestJDBCTools {@Test//JDBCTools类的事务问题public void test05() throws SQLException {Connection connection = JDBCTools.getConnection(); //获取连接connection.setAutoCommit(false);//开启手动提交模式DepartmentDAOlmpl dao=new DepartmentDAOlmpl();try {System.out.println("原始数据:");department d1=dao.getBydid(2);//编号为2的部门System.out.println(d1);d1.setDescription("xx");department d2 = dao.getBydid(3);//编号为3的部门System.out.println(d2);d2.setDescription("yy");d2.setDname(null);//故意设置did为3的部门名称为null,制造问题,观察是否发生回滚,回滚失败了,只有一处修改了//问题思考:dao拿到的数据库连接对象并没有开启手动提交模式,开头的connection连接对象与前者不一致,非同一连接对象/*思考:假设jdbc开启多个数据库连接,其中一个连接开启了手动提交模式,该提交模式的变化是针对整个数据库还是针对开启手动提交模式的连接起作用?该提交模式的变化只是针对开启手动提交模式的连接起作用。在Java中,每个连接都是独立的,它们具有自己的状态和属性。因此,如果你在一个连接中设置了手动提交模式,那么只有在这个连接上执行的操作才会受到这个模式的影响。其他连接的提交模式不会受到影响,它们仍然按照默认的提交模式进行提交。如果你想要在多个连接之间共享事务状态,你需要使用分布式事务或其他的事务管理机制。*/dao.updateDepartment(d1);dao.updateDepartment(d2);System.out.println("修改成功");} catch (Exception e) {e.printStackTrace();System.out.println("修改失败");connection.rollback();}JDBCTools.freeConnection(connection);//释放连接}
}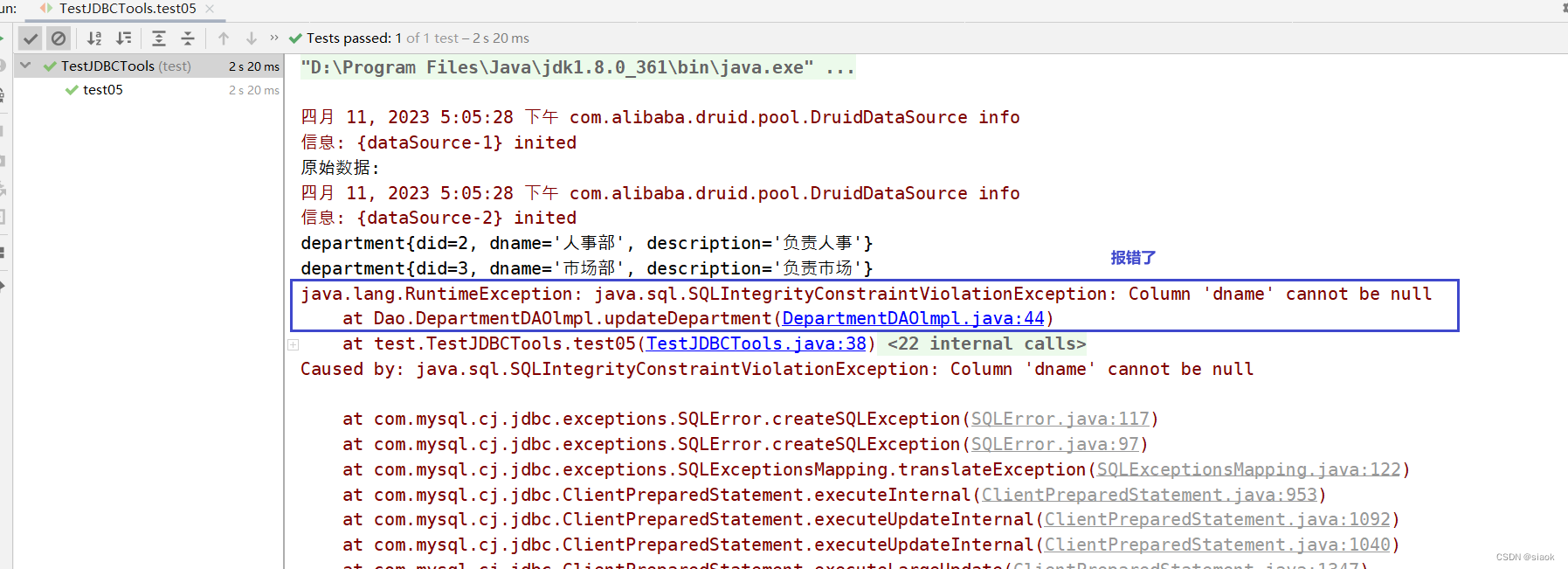
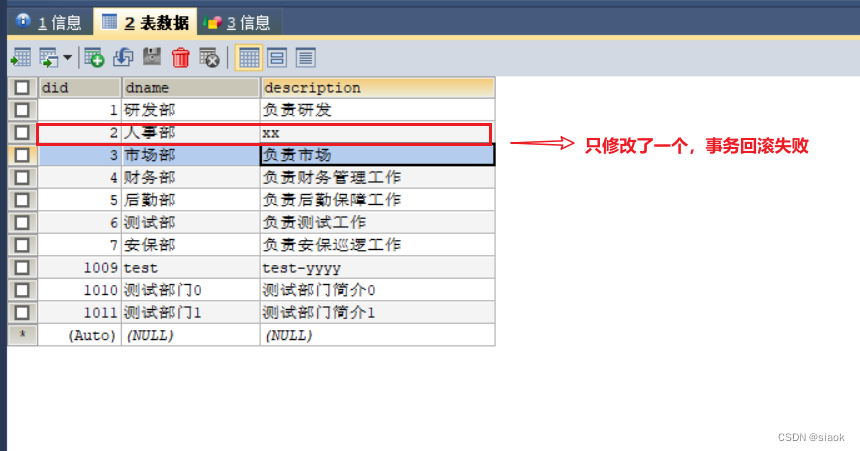
why?为何会回滚失败?
原因分析:
在MySQL数据库中,数据库默认开启自动提交模式,要想开启事务回滚,前提必须是数据库要开启手动提交模式。在上述测试代码中test5()开头获取的连接对象和dao拿到的连接对象非同一个。
在Java中,每个连接都是独立的,它们具有自己的状态和属性 。因此,如果你在一个连接中设置了手动提交模式,那么只有在这个连接上执行的操作才会受到这个模式的影响。其他连接的提交模式不会受到影响,它们仍然按照默认的提交模式进行提交。
因此在test5()中连接对象conn开启了手动提交模式,但实际执行更新操作的dao所使用的连接对象却没开启,还是自动提交模式
2.4.2 JDBCTools2.0
目的:
为了解决JDBCTools 1.0遇到的事务处理问题,引入ThreadLocal类来解决上述问题
ThreadLocal类是什么?
JDK 1.2的版本中提供java.lang.ThreadLocal类,为解决多线程程序的并发问题,通常用于在多线程中管理共享数据库连接、Session等。
ThreadLocal用于保存某个线程共享变量,原因是在Java中,每一个线程对象中都有一个ThreadLocalMap<ThreadLocal, Object>,其key就是一个ThreadLocal,而Object即为该线程的共享变量。 而这个map是通过ThreadLocal的set和get方法操作的。对于同一个static ThreadLocal,不同线程只能从中get,set,remove自己的变量,而不会影响其他线程的变量。
-
ThreadLocal对象.get: 获取ThreadLocal中当前线程共享变量的值。 -
ThreadLocal对象.set: 设置ThreadLocal中当前线程共享变量的值。 -
ThreadLocal对象.remove: 移除ThreadLocal中当前线程共享变量的值。
JDBCTools2.0 代码如下所示:
import com.alibaba.druid.pool.DruidDataSourceFactory;import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;public class JDBCTools2 {//思考:为什么dataSource后面不写代码,只是声明,// 因为它不是简单的new对象,数据库连接池的创建之前要涉及很多代码,只能用静态代码块来实现private static DataSource dataSource;private static ThreadLocal<Connection> threadLocal=new ThreadLocal<>();static {Properties properties=new Properties();try {properties.load(JDBCTools2.class.getClassLoader().getResourceAsStream("druid.properties"));//getResourceAsStream() 返回读取指定资源的输入流//properties.load()读取配置文件中的数据dataSource= DruidDataSourceFactory.createDataSource(properties);//创建连接池} catch (Exception e) {e.printStackTrace();}}//获取连接对象public static Connection getConnection() throws SQLException {Connection connection=threadLocal.get();if (connection==null){connection = dataSource.getConnection();threadLocal.set(connection);//让当前线程存储这个共享的连接,存储到内部的threadlocalmap中,key是threadlocal对象,value是connection对象(数据库的连接)}return connection;}//释放连接对象public static void freeConnection() throws SQLException {Connection connection = threadLocal.get();connection.setAutoCommit(true);//释放连接之前重新恢复为自动提交模式connection.close();threadLocal.remove();}
}
修改之前的部门表:
测试JDBCTools2.0的代码如下演示:
前提:
需要在BaseDAOImpl类的各个方法中使用JDBCTools2.0获取连接对象
import Dao.DepartmentDAOlmpl;
import bean.department;
import org.junit.Test;
import util.JDBCTools;
import util.JDBCTools2;import java.sql.Connection;
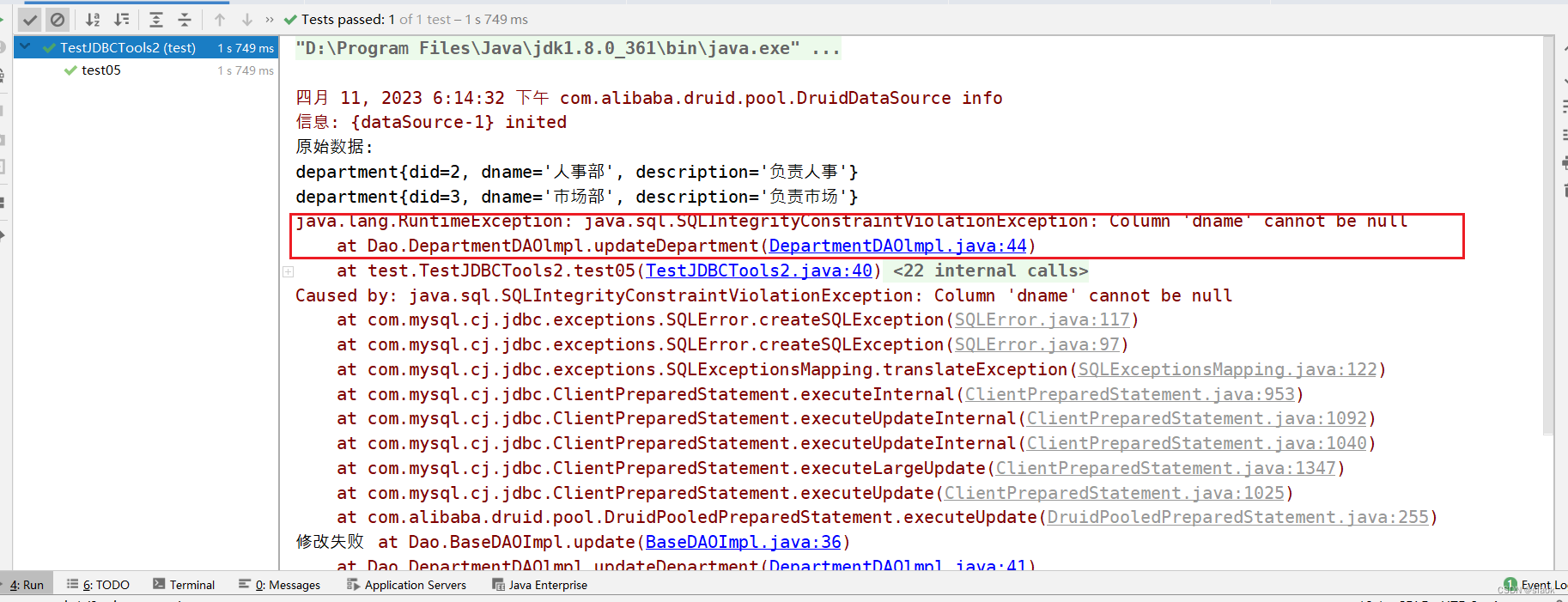
import java.sql.SQLException;public class TestJDBCTools2 {@Test//解决JDBCTools类的事务问题public void test05() throws SQLException {Connection connection = JDBCTools2.getConnection(); //获取连接connection.setAutoCommit(false);//开启手动提交模式try {DepartmentDAOlmpl dao=new DepartmentDAOlmpl();System.out.println("原始数据:");department d1=dao.getBydid(2);//编号为2的部门System.out.println(d1);d1.setDescription("xx");department d2 = dao.getBydid(3);//编号为3的部门System.out.println(d2);d2.setDescription("yy");d2.setDname(null);//故意设置did为3的部门名称为null,制造问题,观察是否发生回滚,回滚成功,值未修改dao.updateDepartment(d1);dao.updateDepartment(d2);System.out.println("修改成功");} catch (Exception e) {e.printStackTrace();System.out.println("修改失败");connection.rollback();}
// JDBCTools.freeConnection(connection);//释放连接JDBCTools2.freeConnection();}
}
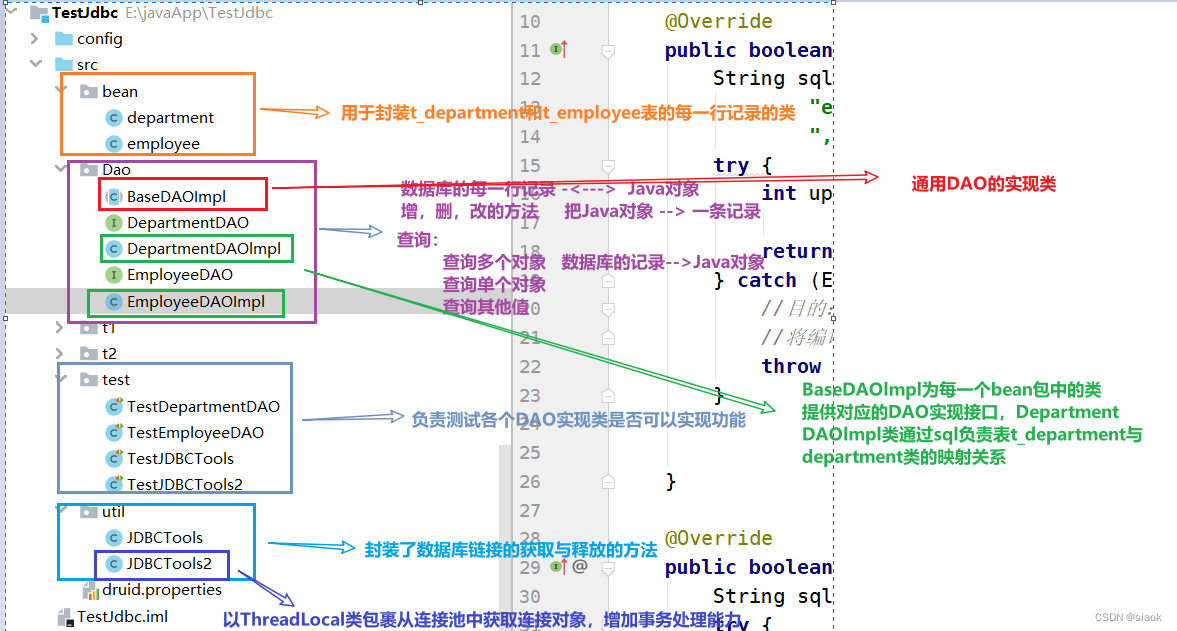
2.5 代码结构分析
2.6 测试结果演示
ps:
以下测试功能按部门表为例详细展示,员工表亦是相同做法,故不做员工表做详细演示
2.6.1 测试部门DAO实现类
①尝试添加数据到t_department中
更新数据前:
代码演示如下:
@Test//测试添加数据public void test01(){Scanner input=new Scanner(System.in);System.out.print("请输入部门名称:");//注:这里要么全用nextLine(),要么全不用String dname=input.nextLine();System.out.print("请输入部门简介:");String description=input.nextLine();department d=new department(dname,description);DepartmentDAOlmpl dao=new DepartmentDAOlmpl();boolean b = dao.addDepartment(d);System.out.println(b?"添加成功":"添加失败");input.close();}
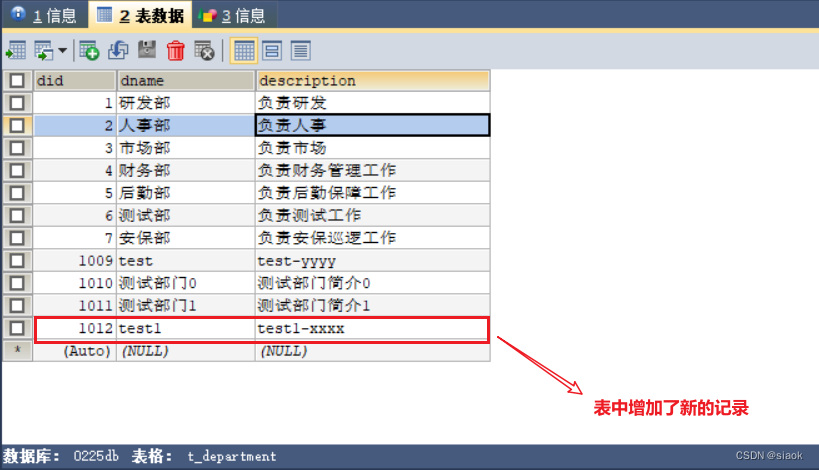
②查询t_department所有的数据
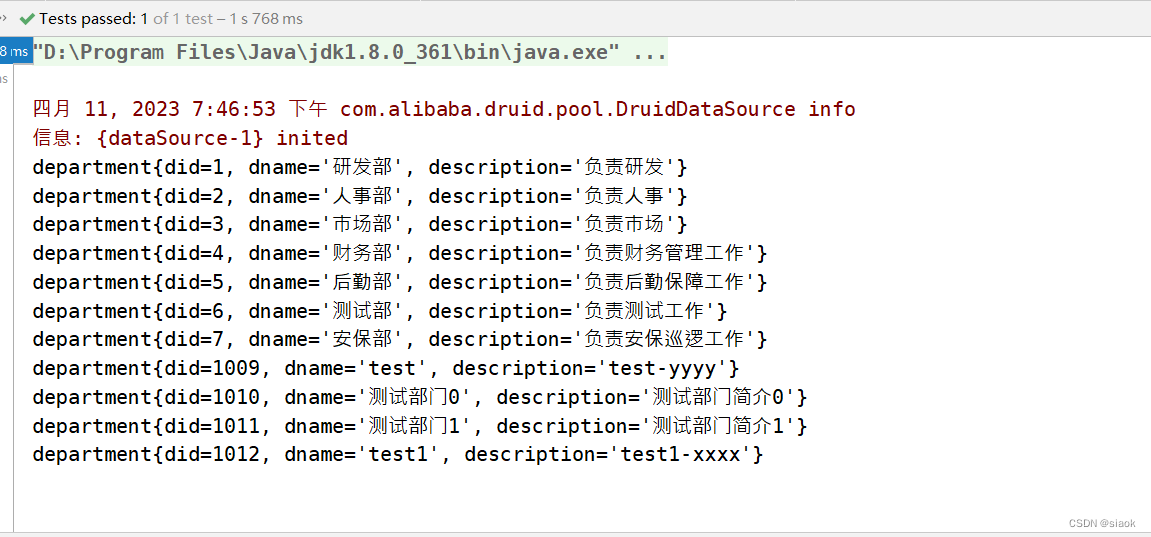
@Test//查询t_employee表中所有的信息public void test04(){DepartmentDAOlmpl dao=new DepartmentDAOlmpl();List<department> allDepartment = dao.getAllDepartment();allDepartment.forEach(t -> System.out.println(t));}
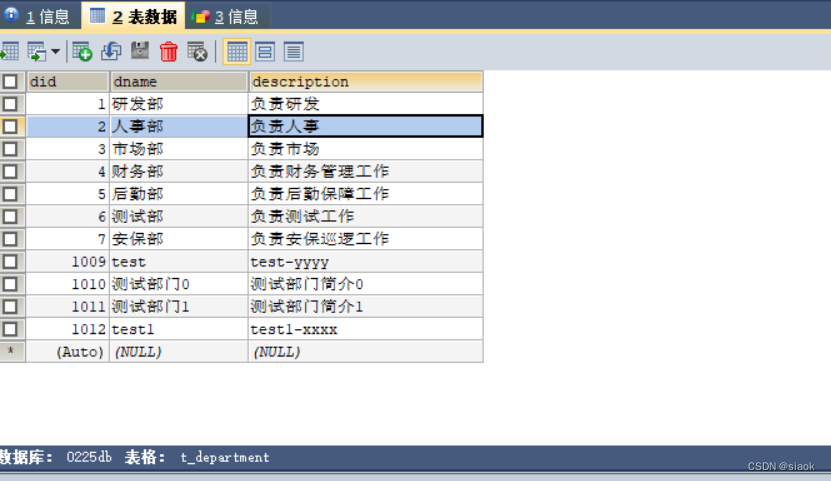
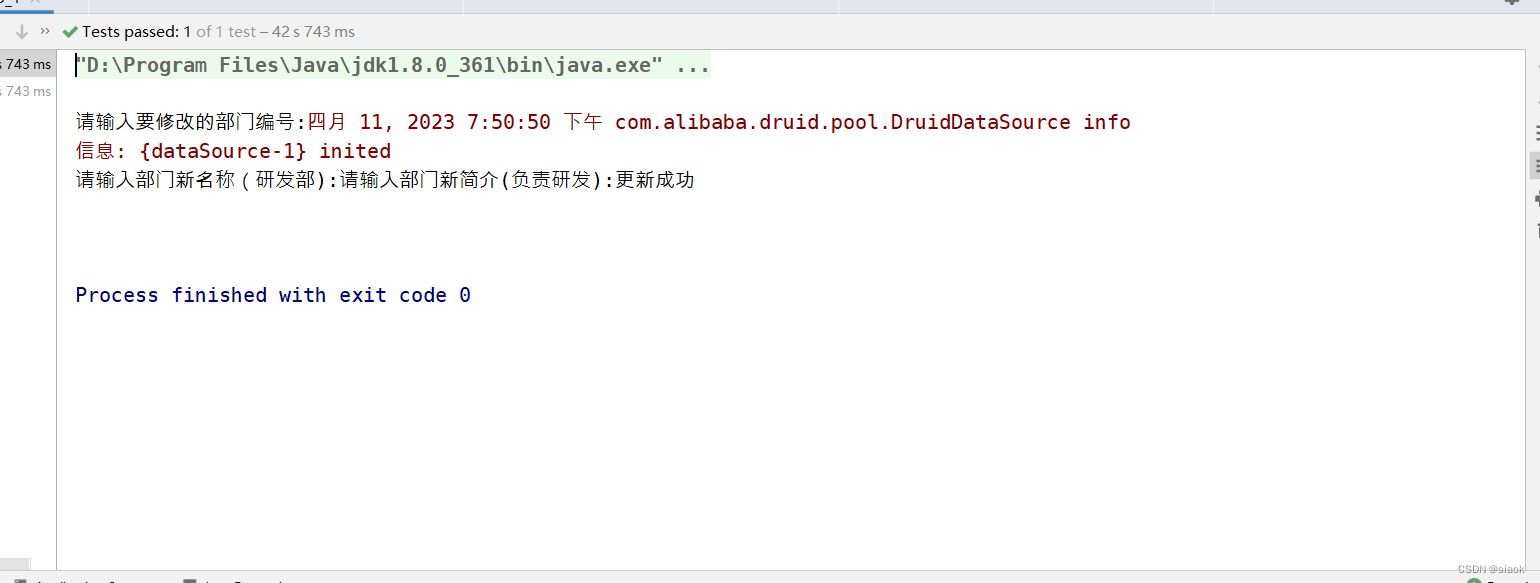
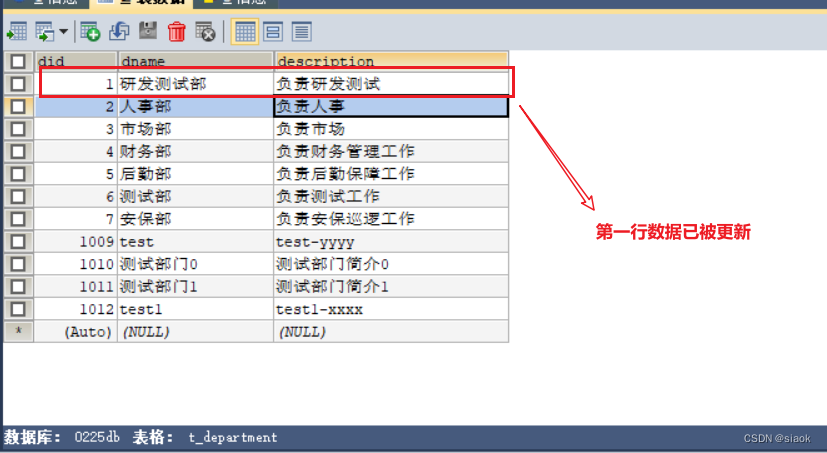
③尝试更新数据,修改t_department表的用户指定的did字段那行的dname与description字段的值
更新之前:
更新数据代码演示如下:
@Test//测试方法test3的优化版//尝试修改t_department表的用户指定的did字段那行的dname与description字段的值public void test03_1(){DepartmentDAOlmpl dao=new DepartmentDAOlmpl();Scanner input=new Scanner(System.in);System.out.print("请输入要修改的部门编号:");int did=input.nextInt();input.nextLine();department department = dao.getBydid(did);System.out.print("请输入部门新名称("+department.getDname()+"):");//注:这里要么全用nextLine(),要么全不用String dname=input.nextLine();//如果什么都输入,就默认使用原来的部门名称if (dname.trim().length()==0){dname=department.getDname();}System.out.print("请输入部门新简介("+department.getDescription()+"):");String description=input.nextLine();if (description.trim().length()==0){description=department.getDescription();}input.close();department=new department(department.getDid(),dname,description);boolean b = dao.updateDepartment(department);System.out.println(b?"更新成功":"更新失败");/*参数索引越界异常java.lang.RuntimeException: java.sql.SQLException: Parameter index out of range (3 > number of parameters, which is 2).可能原因:可能是update的sql语句的标点写了中文的标点符号
*/}
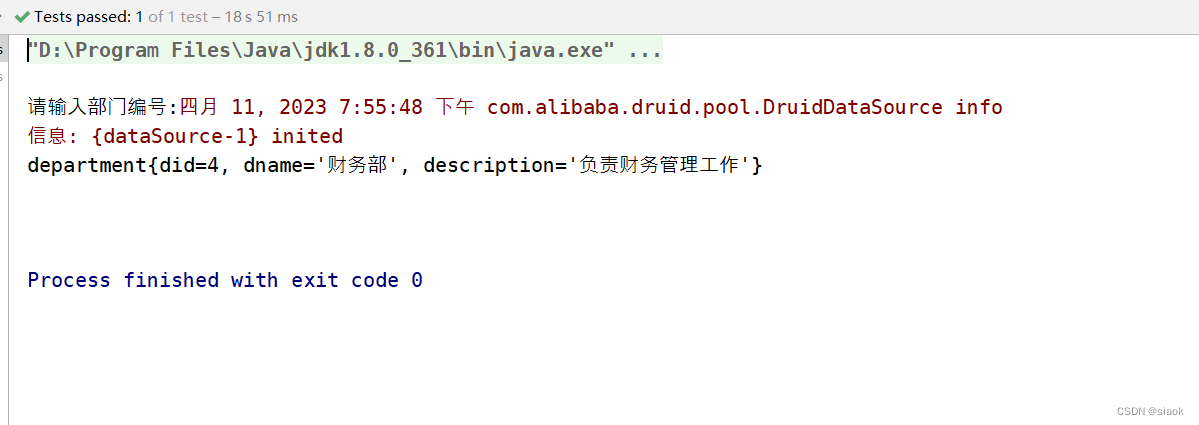
④尝试查询部门编号为4的数据
代码演示如下:
@Test//查询t_department表指定did的行的记录public void test05(){Scanner input=new Scanner(System.in);System.out.print("请输入部门编号:");int did=input.nextInt();DepartmentDAOlmpl dao=new DepartmentDAOlmpl();department department = dao.getBydid(did);System.out.println(department);input.close();}
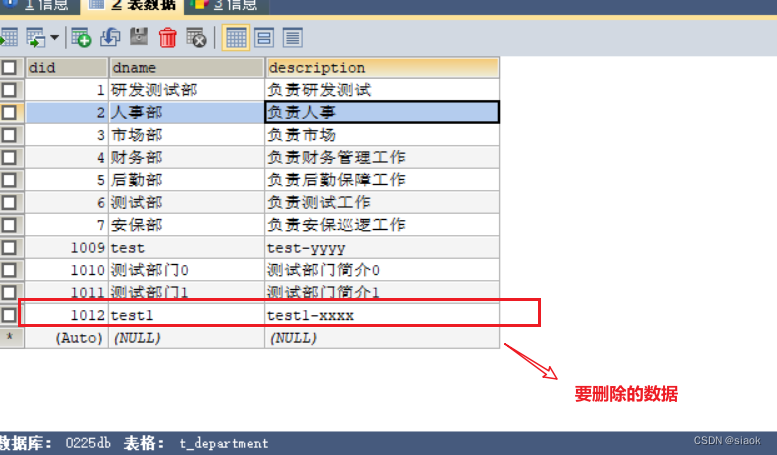
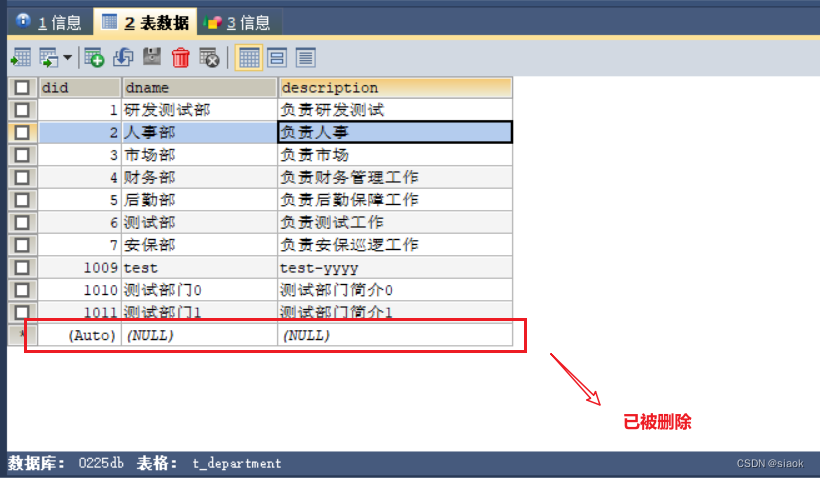
⑤尝试删除部门编号为1012的数据
删除之前:
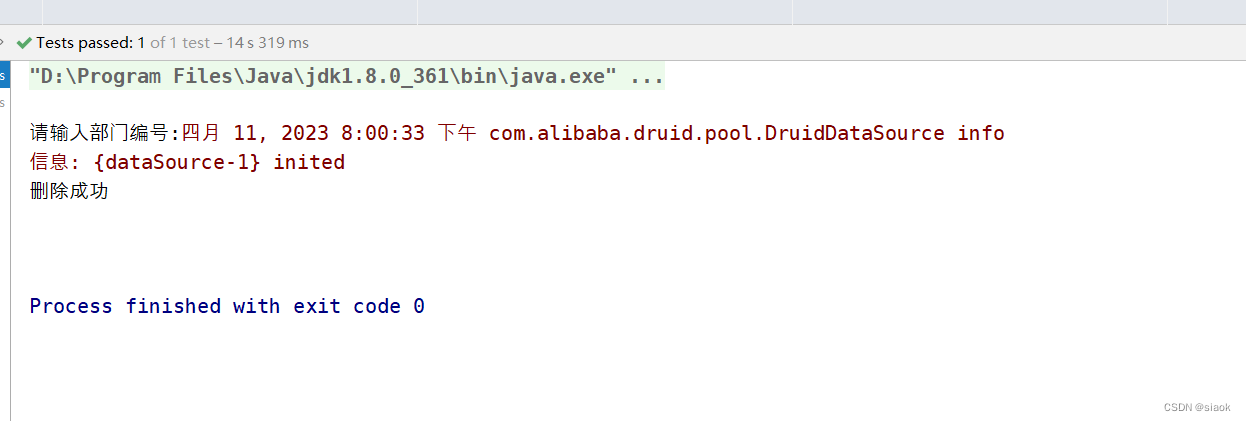
删除代码演示如下:
@Test//测试删除数据public void test02(){Scanner input=new Scanner(System.in);System.out.print("请输入部门编号:");//注:这里要么全用nextLine(),要么全不用int did=input.nextInt();department d=new department(did);DepartmentDAOlmpl dao=new DepartmentDAOlmpl();boolean b = dao.removeDepart(d);System.out.println(b?"删除成功":"删除失败");input.close();}
三、Dbutils优化代码
可引入Dbutils对DAO层的BaseDAOImpl类进行优化,其余代码不变,实现的功能亦是相同
3.1 Dbutils简介
dbutils,全称commons-dbutils,它 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用dbutils能极大简化jdbc编码的工作量,同时也不会影响程序的性能。
其中QueryRunner类封装了SQL的执行,是线程安全的。
- 可以实现增、删、改、查、批处理。
- 考虑了事务处理需要共用Connection。
- 该类最主要的就是简单化了SQL查询,它与ResultSetHandler组合在一起使用可以完成大部分的数据库操作,能够大大减少编码量。
- 不需要手动关闭连接,runner会自动关闭连接,释放到连接池中
3.2 如何使用Dbutils?
使用前提:
使用之前先导入Dbutils的jar包,导入步骤可参考我的这篇博客Java SE: JUnit快速入门指南,导入的步骤和它一模一样,只是jar包的名字不一样而已
(1)更新
public int update(Connection conn, String sql, Object... params) throws SQLException:用来执行一个更新(插入、更新或删除)操作。
…
(2)插入
public T insert(Connection conn,String sql,ResultSetHandler rsh, Object… params) throws SQLException:只支持INSERT语句,其中 rsh - The handler used to create the result object from the ResultSet of auto-generated keys. 返回值: An object generated by the handler.即自动生成的键值
…
(3)批处理
public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: INSERT, UPDATE, or DELETE语句
public T insertBatch(Connection conn,String sql,ResultSetHandler rsh,Object[][] params)throws SQLException:只支持INSERT语句
…
(4)使用QueryRunner类实现查询
public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throws SQLException:执行一个查询操作,在这个查询中,对象数组中的每个元素值被用来作为查询语句的置换参数。该方法会自行处理 PreparedStatement 和 ResultSet 的创建和关闭。
…
ResultSetHandler接口用于处理 java.sql.ResultSet,将数据按要求转换为另一种形式。
ResultSetHandler 接口提供了一个单独的方法:Object handle (java.sql.ResultSet rs)该方法的返回值将作为QueryRunner类的query()方法的返回值。
该接口有如下实现类可以使用:
- BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。
BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里。ScalarHandler:查询单个值对象- MapHandler:将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。
- MapListHandler:将结果集中的每一行数据都封装到一个Map里,然后再存放到List
- ColumnListHandler:将结果集中某一列的数据存放到List中。
- KeyedHandler(name):将结果集中的每一行数据都封装到一个Map里,再把这些map再存到一个map里,其key为指定的key。
- ArrayHandler:把结果集中的第一行数据转成对象数组。
- ArrayListHandler:把结果集中的每一行数据都转成一个数组,再存放到List中。
3.3 BaseDAOImply优化版
代码演示如下:
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import util.JDBCToolsFinal;import java.sql.SQLException;
import java.util.List;public class BaseDAOImpl {private QueryRunner queryRunner=new QueryRunner();//通用的增,删,改的方法/**** @param sql : 执行的sql语句* @param args :sql中有多少个?,就有多少个args,用来替代?并赋值* @return int : 影响的记录条数* @throws SQLException : 可能出现的sql异常*/protected int update(String sql,Object ...args) throws SQLException{return queryRunner.update(JDBCToolsFinal.getConnection(),sql, args);}/*** 通用查询多个JavaBean对象的方法* @param clazz Class JavaBean.对象的类型的Class对象* @param sql 执行的sql语句* @param args Object ...为sqL中的?赋值,如果没有?,可以不传args实参* @param <T> java.Been包中类的类型* @return List<T> 里面包含查询出来的多个的T对象* @throws Exception : 可能出现的sql异常*/protected <T> List<T> getList(Class clazz,String sql,Object ...args) throws Exception{return queryRunner.query(JDBCToolsFinal.getConnection(),sql,new BeanListHandler<T>(clazz),args);}/*** 通用查询单个JavaBean对象的方法* @param clazz Class JavaBean.对象的类型的Class对象* @param sql 执行的sql语句* @param args Object ...为sqL中的?赋值,如果没有?,可以不传args实参* @param <T> java.Been包中类的类型* @return T 一个JavaBean对象* @throws Exception : 可能出现的sql异常*/protected <T> T getBean(Class clazz,String sql,Object ...args) throws Exception{return queryRunner.query(JDBCToolsFinal.getConnection(),sql,new BeanHandler<T>(clazz),args);/*BeanHandler.类的对象作用是把数据库中的表中的一条记录封装为一个JavaBean.对象,这条记录对应的是T类型的对象,如果创建T类型的对象,是通过clazz对象来完成,clazz是T类型的Class对象。*/}//通用的查询某个值的方法protected Object getValue(String sql,Object ... args) throws SQLException {return queryRunner.query(JDBCToolsFinal.getConnection(),sql,new ScalarHandler(),args);//ScalarHandler对象的作用是把sgL查询结果中的单个值返回}//批处理:批量执行一组sql命令protected void batch(String sql,Object[][] args) throws SQLException {queryRunner.batch(JDBCToolsFinal.getConnection(),sql,args);}}







