您现在的位置是:主页 > news > 商贸行业网站建设公司/营销软件网
商贸行业网站建设公司/营销软件网
![]() admin2025/5/13 11:59:55【news】
admin2025/5/13 11:59:55【news】
简介商贸行业网站建设公司,营销软件网,dede做的网站被植入广告,网站做外链的方式Scrapy是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便。Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。 以上是网上摘录的一段介绍…

Scrapy是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便。Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。
以上是网上摘录的一段介绍scrapy框架的文字,大过年的,懒癌高发期…
安装scrapy,pip可以解决你的问题: pip install scrapy。
这里插一句,如果你运行代码后看到这个错误:
ImportError: No module named win32api
深坑出现,你需要安装pywin32,如果已经安装了pywin32,还出现错误,你仍需手动将你python安装目录下\Lib\site-packages\pywin32_system32下:pythoncom27.dll, pywintypes27.dll两个文件复制到c:\windows\system32下!当然如果不是windows系统的话,请无视!最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
话不多说,开始我们的爬虫吧!
首先来分析网页结构:
1、url:https://you.autohome.com.cn 打开旅行家的主页,这里我用的是火狐浏览器,看下图
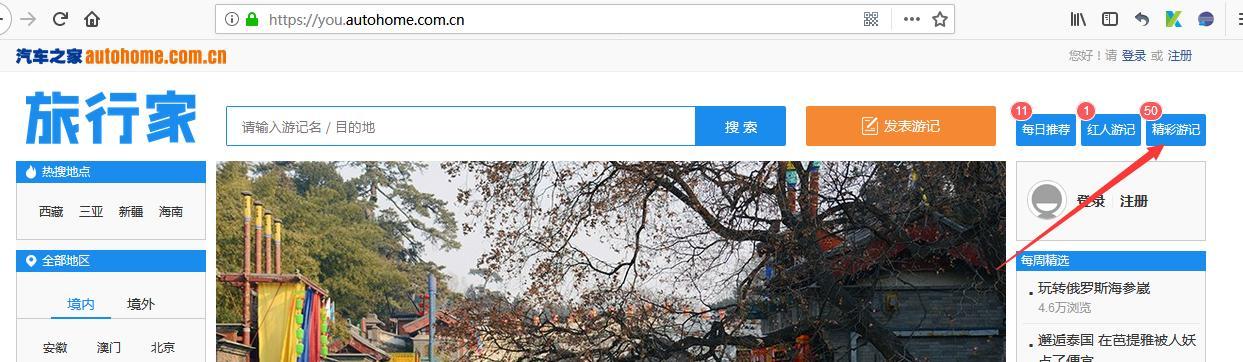
点击精彩游记,然后跳出游记页面,
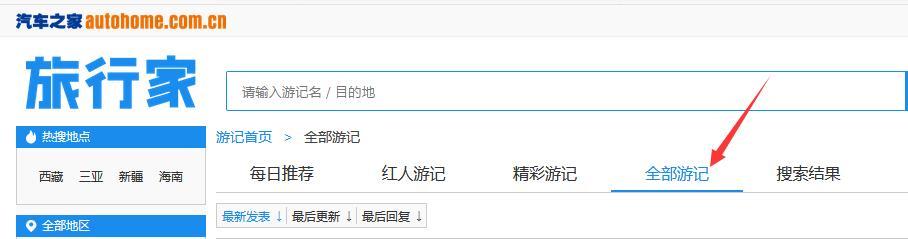
然后在点击全部游记,我们的目标就出现了,拉到最下面,一共3993页,1页20篇

很简单的一个网站
2、我们开始分析每页的数据,直接打开F12抓包,然后刷新网页或者点击其他页,看看服务器返回的请求都有哪些!
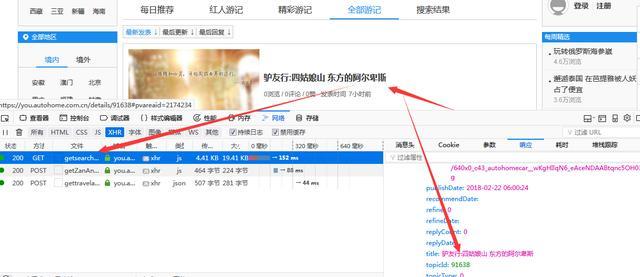
找到一个get请求,里面是json格式的内容,里面有游记的作者、标题、缩略图等等内容,ok,我们可以开始写代码了!
Ps:这里我们只做个简单的页面目录的爬虫,就不一 一抓取文章内容了(如果有需要的小伙伴可以自行添加相关内容)。
3、打开cmd新建一个scrapy框架,命令为:scrapy startproject autohome ,然后系统自动帮我们建立好相关的目录和py文件,我们仍需手动建立一个spider.py(文件名可自取)来放入我们的爬虫
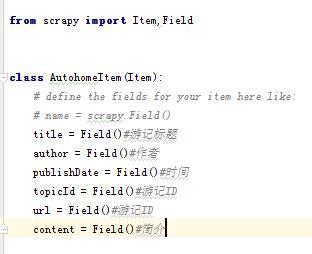
先打开item.py,这里存放的是我们的目标,告诉爬虫我们要爬取的内容是什么!代码如下:
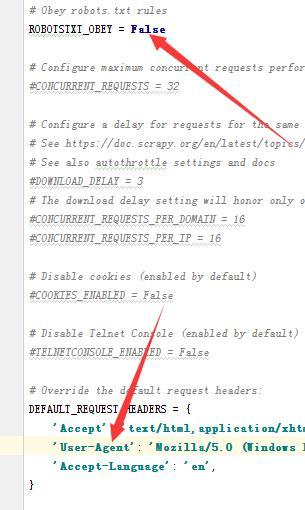
然后打开setting.py(如无必要,不要修改这里的内容),将ROBOTSTXT_OBEY的值改为False(不改的话,有些内容爬不到,这里是选择是否遵循robots协议),然后将你的UA写入下面的头部信息中!最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
其他都不用管了。最后打开spider文件夹,在这里我们要开始写我们的爬虫了!
4、打开新建的py文件,先导入用到的模块
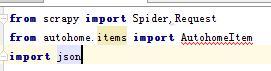
(导入模块后有错误提示可以不用理会),写入如下代码:
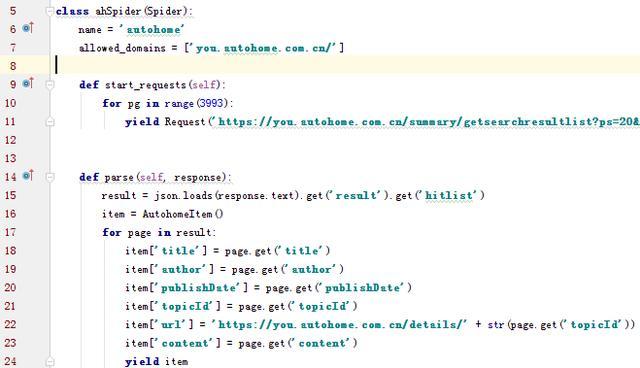
第6行的name是唯一的,可自行命名
第7行为定义爬虫的范围,也就是允许执行的url范围是:autohome.com.cn,注意这里是列表形式
第9.10.11行为抓取的内容所在url,通过yield Request返回,上图未截全部分为:
yield Request('https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg={}&type=3&tagCode=&tagName=&sortType=3'.format(pg),self.parse)
因为只有3993页,直接for循环取到所有页码,定义了start_requests函数后可省略start_urls列表也就是起始列表
第14行开始定义爬取方法
第15行,将json格式的内容赋值给一个变量
第16行,初始化导入的Items文件中所定义的类
第17-24行,循环json格式的内容,并将相应的值赋值给item,这里item是一个字典格式,然后返回给items文件
到这里就写完了这个爬虫,为方便使用,我们直接将结果写入json格式
打开cmd,命令:scrapy crawl autohome -o autohome.json -t json
因为我们爬取的内容很少,所以速度还是很快的
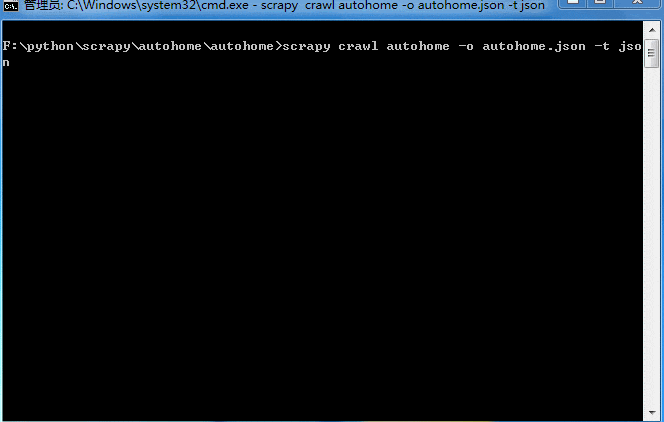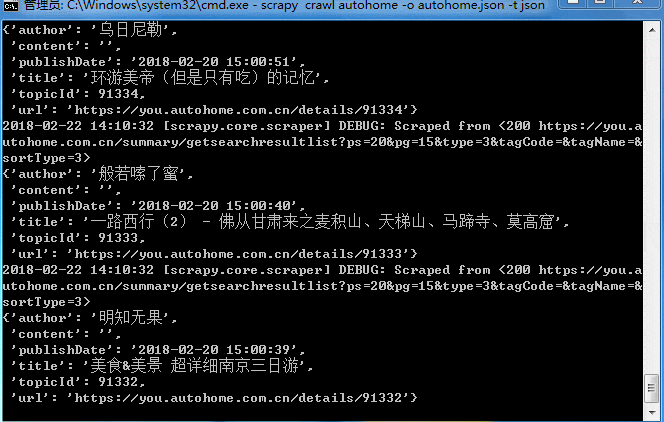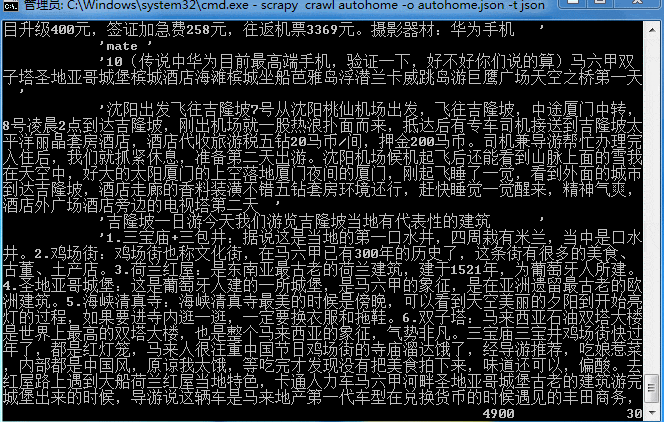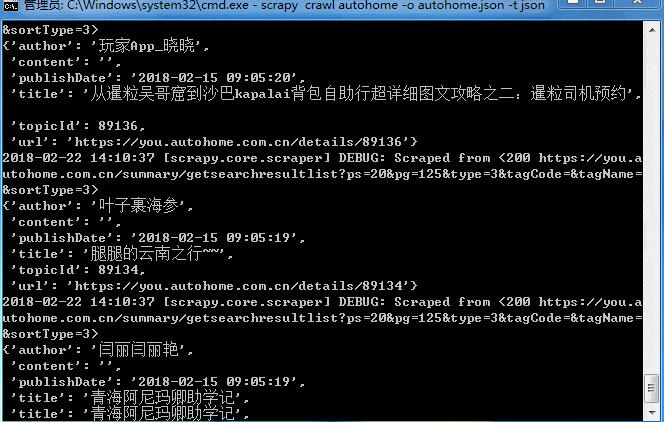
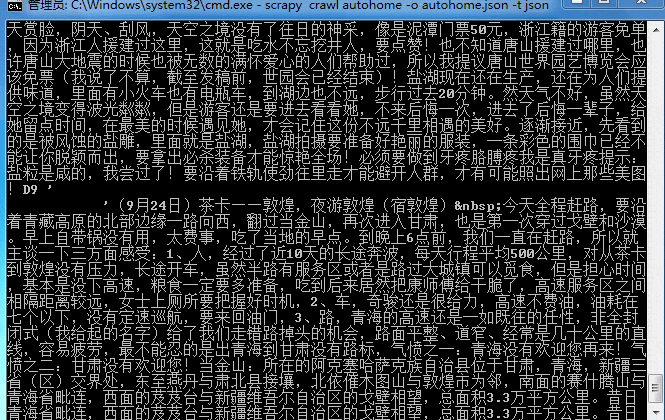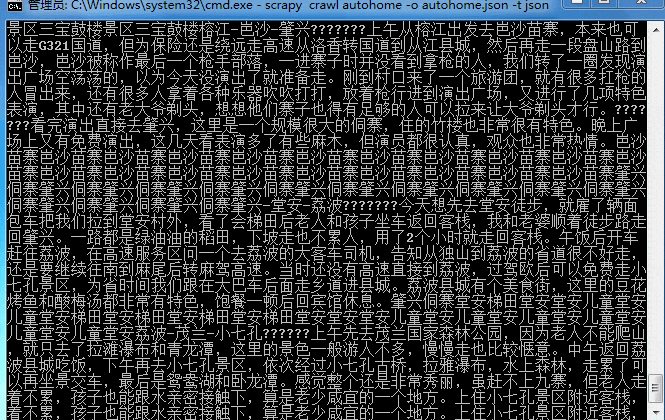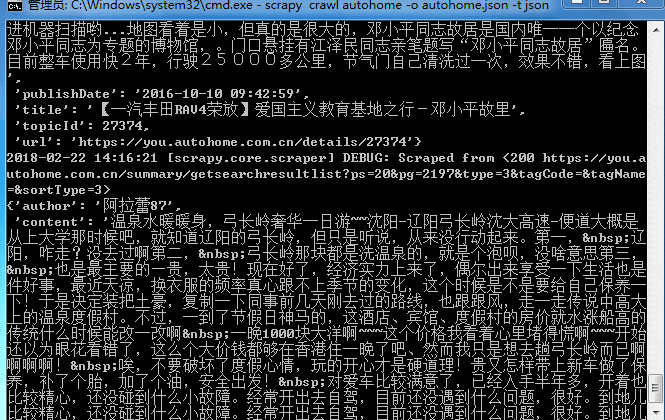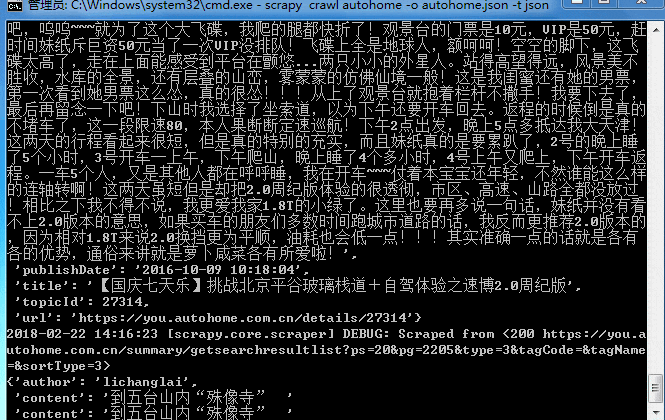
大概十来分钟吧,数据就抓取完成!来看看结果,因为是json格式,截取一小段找个在线解析的网页就可以看了
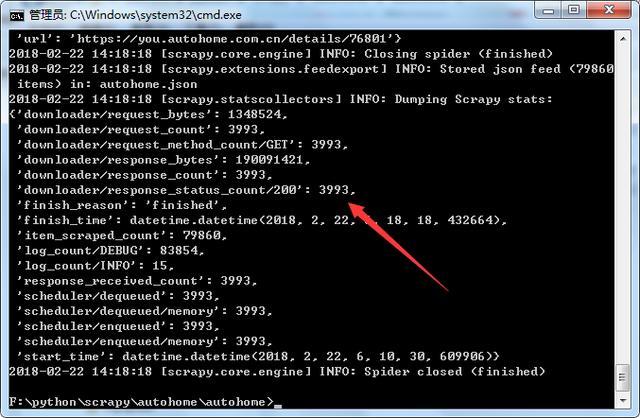
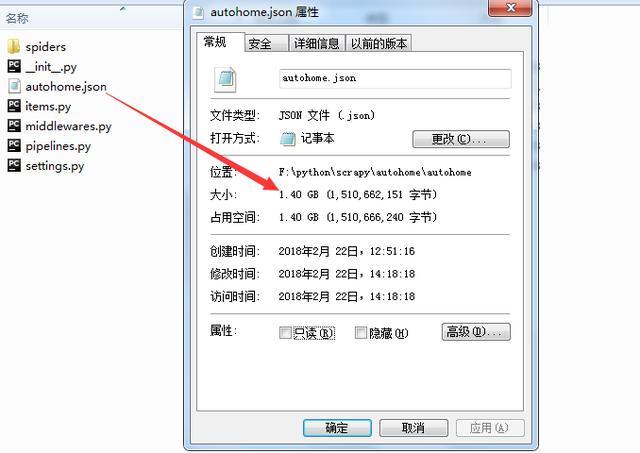

验证一下:
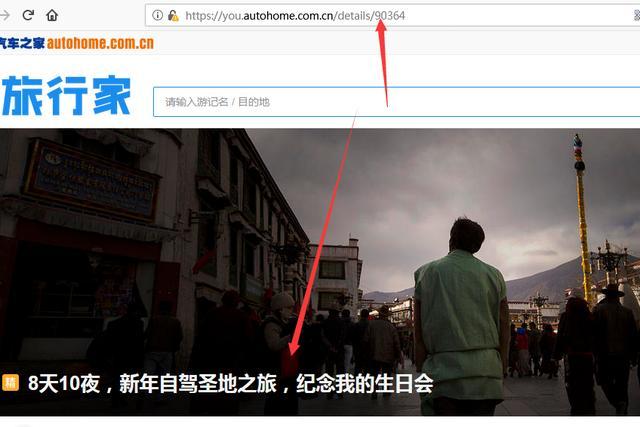
So easy!
喜欢就关注下呗(;°○° )!








