您现在的位置是:主页 > news > 贵州软件开发 网站开发/如何提高搜索引擎优化
贵州软件开发 网站开发/如何提高搜索引擎优化
![]() admin2025/5/12 19:02:12【news】
admin2025/5/12 19:02:12【news】
简介贵州软件开发 网站开发,如何提高搜索引擎优化,专业定制网站开发,免费2级域名注册朴素贝叶斯的优缺点 优点:在数据较少的情况下仍然有效,可以处理多类别问题 缺点:对于输入数据的准备方式较为敏感 使用数据类型:标称型数据 贝叶斯决策理论 假设我们有一个数据集,它由两类数据组成,现在…
朴素贝叶斯的优缺点
优点:在数据较少的情况下仍然有效,可以处理多类别问题
缺点:对于输入数据的准备方式较为敏感
使用数据类型:标称型数据
贝叶斯决策理论
假设我们有一个数据集,它由两类数据组成,现在用p1(x,y)表示数据点(x,y)属于类别1的概率,用p2(x,y)表示数据点(x,y)属于类别2的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y) > p2(x,y),那么类别为1
- 如果p2(x,y) > p1(x,y),那么类别为2
也就是我们会选择高概率对应的类别,这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
条件概率及贝叶斯公式


简化贝叶斯公式,可以写成如下形式:
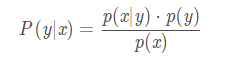
即

关于贝叶斯公式的理解,可以看看这个视频,非常推荐https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1R7411a76r
使用条件概率来分类
上面有提到,贝叶斯决策理论要求计算两个概率p1(x,y)和p2(x,y)
- 如果p1(x,y) > p2(x,y),那么类别为1
- 如果p2(x,y) > p1(x,y),那么类别为2
上面使用p1和p2是为了简化描述,真正需要计算和比较的是p(c1 | x,y)和p(c2 | x,y),即给定某个由x,y表示的数据点,计算该数据点来自类别c1及c2的概率。由于这些概率无法直接得到,而p(x,y | c1)却可以通过对给出的数据点信息计算得到。
而贝叶斯公式可以交换概率中的条件与结果,此时应用贝叶斯公式可得:
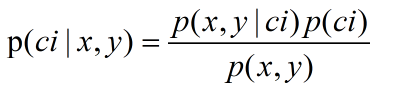
使用该公式,可以定义贝叶斯分类准则为:
- 如果p(c1 | x,y) > p(c2 | x,y),那么类别为1
- 如果p(c2 | x,y) > p(c1 | x,y),那么类别为2
此时便可以通过已知的三个概率值来计算未知的概率值。像上面的x,y对应于样本的特征,设样本的特征用x表示,样本的类别用y表示,上式可进一步转换为:
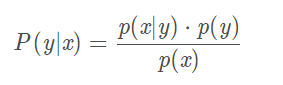
其中,P(y)是先验概率,P(x∣y) 是样本x相对于类别y的条件概率(也称似然),P(x)是一个与y无关的归一化因子,因此它对所有类别来说都是相同的,其实就是个常数,因此:P(y∣x)∝p(x∣y)⋅p(y)P(y∣x)∝p(x∣y)⋅p(y)P(y∣x)∝p(x∣y)⋅p(y)
如果每个样本有n个特征为:x1,x2,…,xn,则有P(y∣x1 ,…,xn)∝P(y)P(x1,…xn| y),根据条件概率的公式有,对于似然概率P(x1,…xn| y)来说,由于它涉及关于x所有属性的联合概率,直接根据样本出现的频率来估计将会遇到严重的困难,例如:假设这n个属性都是二值的,则样本空间将有2n2^n2n种可能的取值,这个值往往要比训练样本的数目还要大,很多样本取值在训练集中根本没有出现,因此直接根据频率来估计P(x1,…xn| y)是不可行的,因为“未被观测到”与“出现概率为零”通常是不同的。
朴素贝叶斯
由上面的内容,可以知道基于贝叶斯公式估计后验概率P(y∣x1 ,…,xn)的主要困难在于似然概率P(x1,…xn| y)是所有属性上的联合概率,难以直接估计得到,为了避开这个障碍,朴素贝叶斯分类器采用了"属性条件独立假设":对于已知类别,假设所有属性相互独立,即每个属性独立地对分类结果发生影响。而"朴素"一词的含义正是这种属性独立性的假设。(根据我们的常识也知道,样本的特征之间几乎不太可能是相互独立的,因此朴素贝叶斯效果肯定不好,但结果却恰恰相反,无数的实验证明朴素贝叶斯在一些任务上效果都很好。)
基于属性独立假设有:P(x1,…xn| y)=P(x1|y)P(x2|y)P(x3|y)…P(xn|y),最终有:
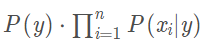
这里的推导如下:
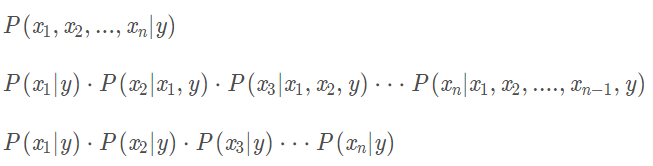
再结合贝叶斯判定原则,最终我们只要最大化后验概率即可预测样本属于哪个类别,这也是朴素贝叶斯分类器的表达式:
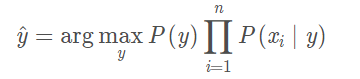
可以看出来朴素贝叶斯的训练过程就是基于训练集D来估计先验概率P(y)的及似然概率p(xi|y),它并不需要像神经网络那样去根据训练数据学习参数。
对于朴素贝叶斯分类器中的P(y)与p(xi|y)的求法如下,例如预测样本属于类别c的概率:
- 令Dc表示训练集D中类别为c样本组成的集合,若样本量充足,则P(c )= |Dc|/|D|
- 对于离散属性而言,Dc,xi表示Dc中在第i个属性上取值为xi的样本组成的集合,则条件概率p(xi|c)可估计为:p(xi|c)=|Dc,xi|/|Dc|
- 对于连续属性可以考虑概率密度函数,假定p(xi|c)属于正态分布,该正太分布的均值和方差分别是第c类样本在第i个属性上取值的均值和方差,则利用概率密度函数即可计算p(xi|c)
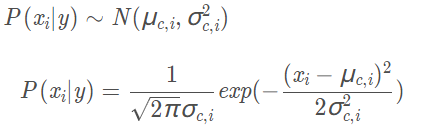
分类示例
这里的例子来自西瓜书,数据集如下:

我们对如下测试样本进行分类


需要注意,若某个属性值在训练集中没有与某个类同时出现过,则直接计算该属性的条件概率会得到0,而由于似然概率为所有属性的条件概率的乘积,故似然概率的计算结果为0。例如:我们有个测试样本的特征为:敲声=清脆,基于上面的数据集,能够发现:
P(清脆∣是)=P(敲声=清脆∣好瓜=是)=0/8=0
此时,即使其他所有特征都很符合好瓜,但是也会被判定为坏瓜,这显然是不合理的,因此此时就需要用到平滑技术,对这个概率值进行平滑。
拉普拉斯修正
为了避免其他属性携带的信息被训练集中未出现的属性值抹去,在估计条件概率值时通常需要进行平滑处理,拉普拉斯修正就是常用的一种方式。
具体来说,令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值个数,则有如下修正:

对于上面的例子,加入拉普拉斯修正后,即有:
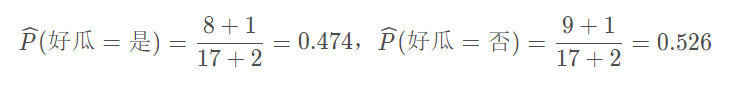

参考:https://blog.csdn.net/u012328159/article/details/89065793
半朴素贝叶斯
为了降低贝叶斯公式中属性的条件概率的计算,朴素贝叶斯分类器采用了属性条件独立性假设,但这在现实任务中这个假设往往很难成立,于是人们尝试对属性条件独立性假设进行一定程度的放松,由此产生了一系列称为“半朴素贝叶斯分类器”的学习方法。
半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信息,从而既不需要进行完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。“独依赖估计”(One-Dependent Estimator, ODE)是半朴素贝叶斯分类器最常用的一种策略,独依赖就是假设每个属性在类别之外最多依赖一个其他属性,即:
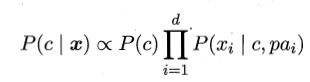
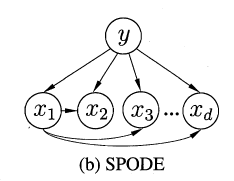
其中pai为属性xi所依赖的属性,称为xi的父属性,此时对于每个属性xi,若其父属性pai已知,则可以进一步估计似然概率。问题的关键转化为如何确定每个属性的父属性,不同的做法产生不同的独依赖分类器。最直接的做法就是假设所有属性都依赖于同一个父属性,成为“超父”(super-parent),然后通过交叉验证等模型选择方法来确定超父属性,由此形成了SPODE(super-parent ODE)方法。例如:下图中x1为超父属性。
AODE(Averaged One-Dependent Estimator)是一种基于集成学习机制、更为强大的独依赖分类器,与SPODE通过模型选择超父属性不同,AODE尝试将每个属性作为超父来构建SPODE,然后将那些具有足够训练数据支撑的SPODE集成起来作为最终结果,即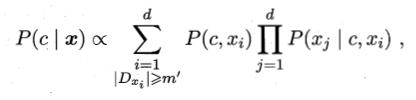
其中DxiD_{xi}Dxi是在第i个属性上取值为xi的样本集合,m’为阈值常数,AODE需要估计P(c, xi)和P(xj | c,xi),他们的计算方式如下:
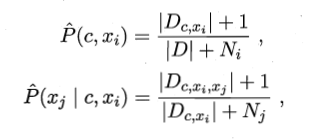
其中N是D中可能的类别数,Ni是第i个属性可能的取值数,Dc,xiD_{c,xi}Dc,xi是类别为c且在第i个属性上取值为xi的样本集合,Dc,xi,xjD_{c,xi,xj}Dc,xi,xj是类别为c且在第i和第j个属性上取值分别为xi和xj的样本集合,例如对于西瓜数据集有:

可以看出AODE与朴素贝叶斯分类器类似,在训练数据集上对符合条件的样本进行计数的过程,与SPODE相比,AODE无需模型选择,既能通过预计算节省预测时间,又能采取懒惰学习方式在预测时再进行计数,并且易于实现增量学习。








