您现在的位置是:主页 > news > seo品牌优化整站优化/广州网站建设技术外包
seo品牌优化整站优化/广州网站建设技术外包
![]() admin2025/5/9 2:51:39【news】
admin2025/5/9 2:51:39【news】
简介seo品牌优化整站优化,广州网站建设技术外包,网络营销方案分析,网站建设彩铃之前一直在使用train_test_split函数划分训练集和测试集,但是一直不清楚它是怎么划分的,有没有打乱数据集,如果直接在最后取部分数据作为测试集在某些数据集中是很影响训练效果的。验证如下: import numpy as np from sklearn.mod…
之前一直在使用train_test_split函数划分训练集和测试集,但是一直不清楚它是怎么划分的,有没有打乱数据集,如果直接在最后取部分数据作为测试集在某些数据集中是很影响训练效果的。验证如下:
import numpy as np
from sklearn.model_selection import train_test_splitdata = np.array([[1,5,9],[2,8,6],[3,8,6],[4,2,6],[5,2,9],[6,7,9]])
data

label = np.array([1,2,3,4,5,6])
label
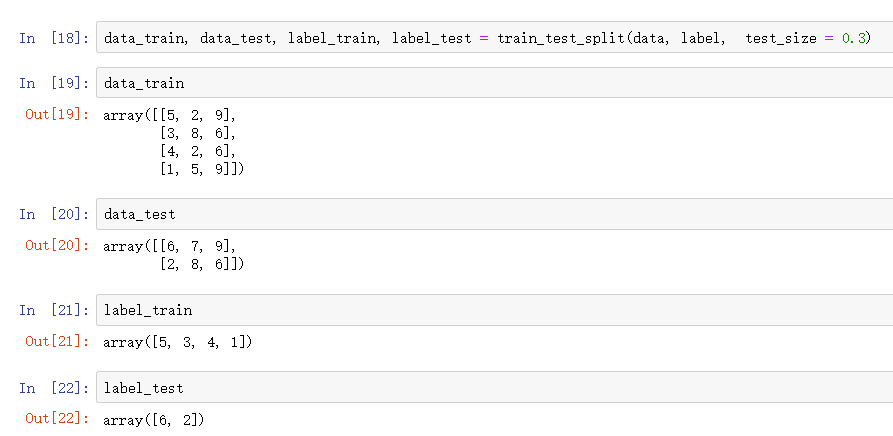
data_train, data_test, label_train, label_test = train_test_split(data, label, test_size = 0.3)
结果发现,训练数据是被打乱了的
训练集和测试集划分
实际上train_test_split函数有三个参数:train_test_split (*arrays,test_size, train_size, rondom_state=None, shuffle=True, stratify=None)shuffle默认为True,所以数据集是打乱的。
===========================参数如下===============================
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
stratify是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。如果train_test_split(… test_size=0.25, stratify = y_all), 那么split之后数据如下:
training: 75个数据,其中60个属于A类,15个属于B类。
testing: 25个数据,其中20个属于A类,5个属于B类。
用了stratify参数,training集和testing集的类的比例是 A:B= 4:1,等同于split前的比例(80:20)。通常在这种类分布不平衡的情况下会用到stratify。
将stratify=X就是按照X中的比例分配
将stratify=y就是按照y中的比例分配
整体总结起来各个参数的设置及其类型如下:
主要参数说明:
*arrays:可以是列表、numpy数组、scipy稀疏矩阵或pandas的数据框
test_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示测试集占总样本的百分比
②若为整数时,表示测试样本样本数
③若为None时,test size自动设置成0.25
train_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示训练集占总样本的百分比
②若为整数时,表示训练样本的样本数
③若为None时,train_size自动被设置成0.75
random_state:可以为整数、RandomState实例或None,默认为None
①若为None时,每次生成的数据都是随机,可能不一样
②若为整数时,每次生成的数据都相同
stratify:可以为类似数组或None
①若为None时,划分出来的测试集或训练集中,其类标签的比例也是随机的
②若不为None时,划分出来的测试集或训练集中,其类标签的比例同输入的数组中类标签的比例相同,可以用于处理不均衡的数据集
链接:https://www.jianshu.com/p/861c757a1312








