您现在的位置是:主页 > news > 做c2c网站的弊端/网站设计与网页制作
做c2c网站的弊端/网站设计与网页制作
![]() admin2025/5/9 1:24:55【news】
admin2025/5/9 1:24:55【news】
简介做c2c网站的弊端,网站设计与网页制作,东昌网站建设,王也扮演者Python版本:3.6.4相关模块:scrapy模块;requests模块;fake_useragent模块;以及一些python自带的模块。环境搭建安装Python并添加到环境变量,pip安装需要的相关模块即可。相关文件新手学习,Python…
Python版本:3.6.4
相关模块:
scrapy模块;
requests模块;
fake_useragent模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
相关文件
新手学习,Python 教程/工具/方法/解疑+V:itz992
原理简介
原理其实蛮简单的,因为之前就知道知乎有个api一直可以用:
https://www.zhihu.com/node/QuestionAnswerListV2
post请求这个链接,携带的数据格式如下:
data = {
就可以获得该问题下的所有回答啦,然后用正则表达式提取每个回答下的所有图片链接就OK了。
具体实现的时候用的scrapy,先新建一个scrapy项目:
scrapy startproject zhihuEmoji
然后在spiders文件夹下新建一个zhihuEmoji.py文件,实现我们的爬虫主程序:
'''知乎表情包爬取'''
其中ZhihuemojiItem()用来存储我们爬取的所有图片链接和对应的回答id,具体定义如下:
class ZhihuemojiItem(scrapy.Item):
OK,大功告成,完整源代码详见相关文件(我爬的表情包也在相关文件里提供了QAQ)~
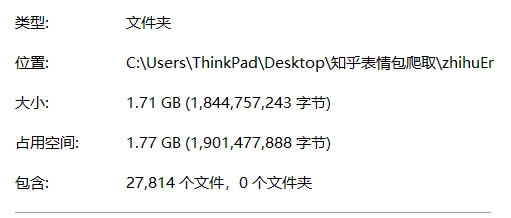
效果展示
在cmd窗口运行如下命令即可:
scrapy crawl zhihuEmoji -o infos.json -t json
我代码跑了两个多小时,最后大概爬了几万张表情包,截图如下: