"当系统的每一部分都由最优解或相对优解组成,那么系统最终也将是最完美的。"
这句话是在参加莫技术分享会上听到的,这句话吸引我占在人群后面听完了她的分享,确实受益良多。
本文也旨在描述自己在项目演变中对一处公共处理逻辑优化的过程,周期略长最近有时间整理如下。
业务系统数据传递过程中,会抽取一些公共的属性和方法封装为特定基类以便于后续开发进行继承。
这些被抽象出来的拥有公共属性的基类,在业务流转过程中的赋值也应当进行统一妥善的处理。
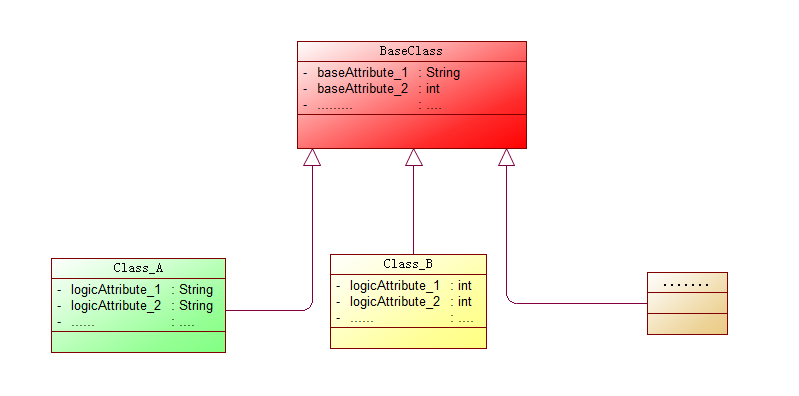
看到这里的小伙伴们可能心中有点疑惑,在业务组织 Class_A/Class_B/...将基类中基本属性顺势填充不就可以了吗?
实际业务中 BaseClass 中的属性需要根据各种不同的场景进行演变和推算,你确定将这些公共推算方式放入业务逻辑中合适吗??
随着系统扩展继承 BaseClass 的子类会膨胀,所有的子类都需要进行父类基本属性赋值,代码看起来是不是有点重复?
当公共属性推算方式发生变化,修改所有子类计算方式和修改公共方法,工作量孰重孰轻?
抽取成公共方法这点毋庸置疑的,但怎样高效和优雅的书写代码呢?
本文试结合实例,简述在业务流转中对拥有公共属性基类赋值的方法以及后续持续优化。
例子将省略公共属性的判断推算过程,实际项目中的公共属性和业务对象过于复杂,自己简单抽象对象如下(关注点为公共属性的赋值)。
public class BaseStudentVO {private String stu_id;private String stu_name;private Integer stu_age;private Date stu_birthday;.......getter/setter }public class PrimaryScholar extends BaseStudentVO {.......logicAttribute }
BaseStudentVO 为抽取公共属性的基类,业务中使用的为 PrimaryScholar,业务开始流转时需要将基类的公共属性填充进去。
起初编写函数时采用反射方式,由子类反射获取超类并迭代超类公共方法,获取特定 set 方法进行调用,代码思路如下:
private Object setBaseAtrByReflect(Map<String, Object> baseParam, Class clazz) throws Exception {Object instance = clazz.newInstance();Class superclass = clazz.getSuperclass();Method[] declaredMethods = superclass.getDeclaredMethods();for (Method declaredMethod : declaredMethods) {if (declaredMethod.getName().contains("set")) {if (declaredMethod.getName().contains("Stu_id")) {declaredMethod.invoke(instance, baseParam.get("stu_id"));continue;}if (declaredMethod.getName().contains("Stu_name")) {declaredMethod.invoke(instance, baseParam.get("stu_name"));continue;}if (declaredMethod.getName().contains("Stu_age")) {declaredMethod.invoke(instance, (Integer) baseParam.get("stu_age"));continue;}if (declaredMethod.getName().contains("Stu_birthday")) {declaredMethod.invoke(instance, (Date) baseParam.get("stu_birthday"));}}}return instance;}
起初这种方式大概是最差的,需要强转类型/随属性增多的的判断/迭代超类的所有的公共方法....简直不忍直视。
后面空闲时间采用 java 内省重新编码了函数, java 内省通俗来说是 jdk 提供给程序员一种更优雅的方式获取 java-bean 的 getter/setter 方法。
内省和反射是两码事请区别对待,但毋容置疑内省是由反射实现,只不过代码实现由 sun 公司的 java 团队,并经过很严格测试。
private Object setBaseAtrByIntrospect(Map<String, Object> baseParam, Class clazz) throws Exception {Object instance = clazz.newInstance();Class superclass = clazz.getSuperclass();PropertyDescriptor propDesc;Method methodSetUserName;for (Field field : superclass.getDeclaredFields()) {propDesc = new PropertyDescriptor(field.getName(), clazz);methodSetUserName = propDesc.getWriteMethod();methodSetUserName.invoke(instance, baseParam.get(field.getName()));}return instance;}
采用内省后比 assembleBaseAtrByReflect 反射时的代码是不是清爽了很多,而且摈弃了很多难堪的地方,比如 强制类型转换/随属性增多的判断。
当后来偶然瞥见 apache.beanutil 中几个有意思的 API 时,我觉得是时候优化下原项目中对应函数的编码。
private Object setBaseAtrByBeanUtil(Map<String, Object> baseParam, Class clazz) throws Exception {Object instance = clazz.newInstance();BeanUtils.setProperty(instance, "stu_id", baseParam.get("stu_id"));BeanUtils.setProperty(instance, "stu_name", baseParam.get("stu_name"));BeanUtils.setProperty(instance, "stu_age", baseParam.get("stu_age"));BeanUtils.setProperty(instance, "stu_birthday", baseParam.get("stu_birthday"));return instance;}
代码是不是简单明快了很多?看起来一目了然,而且进行了精准打击,没有多余迭代判断。
如果你反编译 BeanUtil 中的对应方法,你还是会找到 内省的影子。
最近瞅见了分层中对泛型的抽象使用,难免让人浮想联翩,忍不住使用泛型调整了该函数的实现。
private <T extends BaseStudentVO> T setBaseAtrByGenenic(Map<String, Object> baseParam, T t) {t.setStu_id(baseParam.get("stu_id").toString());t.setStu_name(baseParam.get("stu_name").toString());t.setStu_age((Integer) baseParam.get("stu_age"));t.setStu_birthday((Date) baseParam.get("stu_birthday"));return t;}
泛型中的边界限定很切合了该业务场景,使入参泛型 t 能顺畅的使用基类中的 set 方法,彻底摆脱了反射。
反射的执行效率偏低,早已成为不争的事实,使用泛型重写后出现了类型强转的问题,但这已经是最优解了。
从开始的反射到后面的内省到最终的泛型,想法都是在翻看其他人的分享或撸一段实现时突然蹦出来。








