您现在的位置是:主页 > news > 做网站如何安全 博客/seo关键词优化工具
做网站如何安全 博客/seo关键词优化工具
![]() admin2025/5/7 16:14:20【news】
admin2025/5/7 16:14:20【news】
简介做网站如何安全 博客,seo关键词优化工具,微店网站链接怎么做,超大网站制作素材Kafka概述Kafka整体架构Kafka原理和使用的文章网上很多了,这里只做总体性的概述,拉齐下知识背景。不是本文的重点。Kafka是LinkedIn公司使用Scala语言开发,后来捐献给apache的项目。官网地址是http://kafka.apache.org/。是常用的以高吞吐、可…
Kafka概述
Kafka整体架构
Kafka原理和使用的文章网上很多了,这里只做总体性的概述,拉齐下知识背景。不是本文的重点。
Kafka是LinkedIn公司使用Scala语言开发,后来捐献给apache的项目。官网地址是http://kafka.apache.org/。是常用的以高吞吐、可持久化、可水平扩展、支持流处理的分布式消息系统。
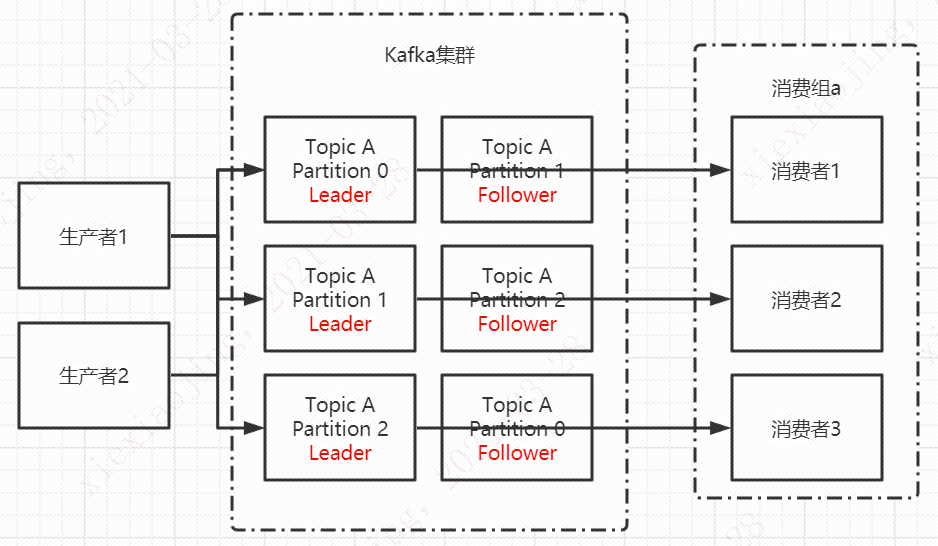
Kafka的一个简单架构图如上面所示,生产端:逻辑层生产者将消息发到指定的topic中,物理层,生产者先找到相应的集群和对应的leader partition建立连接发送消息。消费端:逻辑层消费组接收此topic的所有消息,物理层消费组的消费者连接到固定的partition来消费消息。
在物理层上包装逻辑层也是一个比较常见的解耦方法:比如很多公司都是多地域多中心的多活容灾架构。在物理层北京亦庄数据中心、上海桂桥数据中心等物理数据中心上划分逻辑数据中心,数据中心的迁移可以做到应用服务不感知。底层的实现原理也很简单就是标签+路由层。
Kafka集群服务端架构
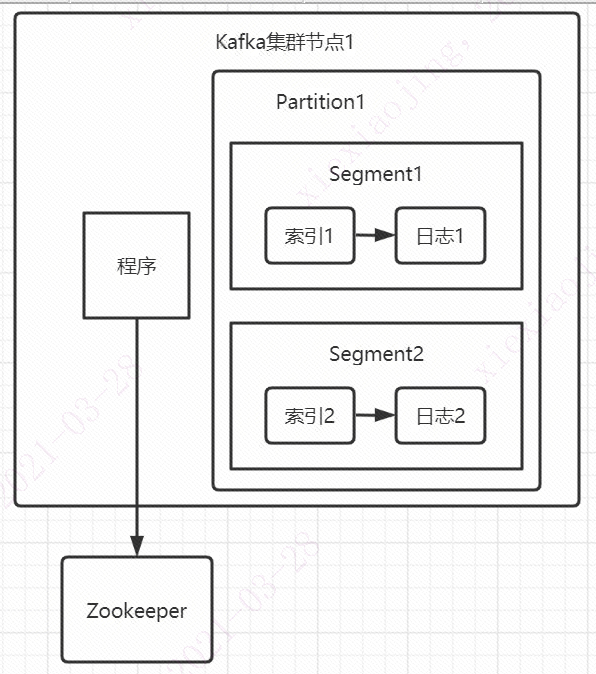
Kafka集群的一台服务端和其他应用一样,是由应用+数据组成,可以算作是一个分布式文件系统。大多数的分布式文件系统就是主从架构如Mysql、Kubernetes和Kafka,个别是对等式的架构如ElasticSearch。Kafka的主节点被称为Controller,负责和Zookeeper通信、集群成员管理(Broker上下线)和Topic管理(增删改查)。Zookeeper里存储的是集群的元数据信息。简而言之,Controller的功能可以类比Kubernetes等集群的Controller功能,差不多的。
数据存储上,每个partition物理上是一个文件夹,相当于将一个巨型文件分成多个大小相等的segment文件。每个文件的消息数不一定相等。每个partition文件由于是顺序读写,所以老的segment文件可以快速被删除。
一个segment文件由一个index文件和一个数据文件组成。文件名为上一个文件的最后一条消息的offset值。索引文件是稀疏索引。所谓稀疏索引说白了就是说不是每条消息都有索引,间隔几条才会有。数据文件也叫日志文件,里面都是一条条消息数据。

需要查找一条消息的时候,先用二分查询在索引文件里查找到最接近的小于要查询的索引地址,然后去日志文件里定位到这条最接近的数据,之后顺序查找到真正需要查找的数据。
Kafka实际项目遇到的一个问题:加代理之后的通信
我们线上有用Kafka与其他公司进行通信的地方。这里,我们只是负责生产消息,其他公司负责消费消息。搭建测试环境的时候,涉及到生产区与测试区的通信,加了一层代理。
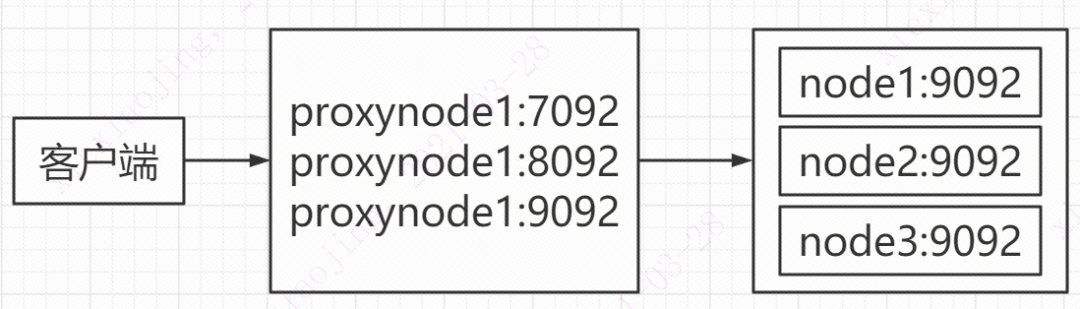
外部提供的Kafka集群测试服务器是三台,对应node1:9092\node2:9092\node3:9092。而代理服务器只有1台。所以映射的时候,是映射成三个端口:proxyNode1:7092\proxyNode1:8092\proxyNode1:9092。结果,发送消息的时候,会1/3的概率,消息发送失败。

因为第一步和第三步不是同一个会话,防火墙drop。第一步和第三步访问外部同一个服务器,服务器不处理。所以我们给SA提了一个改造需求,请他们在代理服务器上增加虚拟网卡,使用三个IP来代理。解决问题。
这里面的内部原理再解释一下:客户端与kafka集群建立连接,第一步做的是获取元数据信息。查看客户端的trace日志可以看到服务端返回的broker的node、partition、controller等信息。客户端通过返回的信息与服务端建立连接。所以要解决这个问题,并且代理层不改造的话,需要改服务端的配置,让一个topic只有一个partition,并且客户端只和这个partition所在服务器建立连接。
Kafka实际项目使用的思考:切换加密集群
安全上的需要,连接Kafka集群需要加密,使用的SASL简单认证和安全层。假设说我们使用的是用户名密码+SSL认证。
假设我们没有专门存储加密信息的基础设施,只能将密码放到配置文件里。那最基础的一个隐性需求是密码需要加密,不能明文存放。这个可能不会写到需求文档里,但作为工程师是自己需要考虑的。
集群加密其他问题就是平滑上线的问题。我们采用灰度上线的方案。生产环境上,Kafka服务端保留原始集群,新建加密集群。加密集群有两个topic,一个是正式topic,一个是测试topic。测试topic的数据将被丢弃不做处理。上线时先保持发送数据到原始集群不变,手工发测试数据到加密集群的测试topic。如果测试没有问题,说明加密集群和与加密集群之间的通信都没有问题。这时候可以打开开关,将数据同时发送到原始集群和加密集群正式topic观察。并行一段时间没有问题则切换到正式topic。
其实加密Kafka和普通Kafka性能上有明显的下降。所以需要压测,并且对数据做抓包比对,看每一个阶段的延迟是否符合预期。比如业界统计数据SSL认证会增加20%到30%的链路耗时。
后记
前段时间有朋友好心提醒我,我的文章被别人盗用,没有标出处。我很感谢,但是微信公众号有限制超过多久就不能回复了。所以这里表达一下谢意。另外说一下我自己对这件事情的看法:几年前刚写文章的时候我也挺介意这件事的,后来就看淡了,反正都是分享知识,从谁那里分享来的不是分享。
不过有次,我的文章被授权同步到别的平台,收到留言说文章的内容人家看过,问我怎么好意思标原创,我就坐不住了,回复了一个:别人抄我的好吗?不过现在的话,我会看开很多。解释还是要解释的,语气就变了:本文是我于XX年XX月XX日首发于【编程一生】技术公众号的文章,其他如有雷同,大概率是人家抄了我的吧[偷笑]
工作也好,写文章也好,能坚持下来就是一种修行。悟道修炼,不问一生缘劫。所谓得道,我的理解是活成自己喜欢的样子。修炼中……
推荐阅读








