您现在的位置是:主页 > news > 建设银行网站维修图片/网站建设规划书
建设银行网站维修图片/网站建设规划书
![]() admin2025/5/6 9:44:34【news】
admin2025/5/6 9:44:34【news】
简介建设银行网站维修图片,网站建设规划书,平台电商和专业电商区别,嘉兴网站制作方案文本分类是一项常见的 NLP 任务,它根据文本的内容定义文本的类型、流派或主题。Huggingface🤗 Transformers 提供 API 和工具来轻松下载和训练最先进的预训练模型。Huggingface Transformers 支持 PyTorch、TensorFlow 和 JAX 之间的框架互操作性。模型还…
文本分类是一项常见的 NLP 任务,它根据文本的内容定义文本的类型、流派或主题。Huggingface🤗 Transformers 提供 API 和工具来轻松下载和训练最先进的预训练模型。Huggingface Transformers 支持 PyTorch、TensorFlow 和 JAX 之间的框架互操作性。模型还可以导出为 ONNX 和 TorchScript 等格式,以便在生产环境中部署。
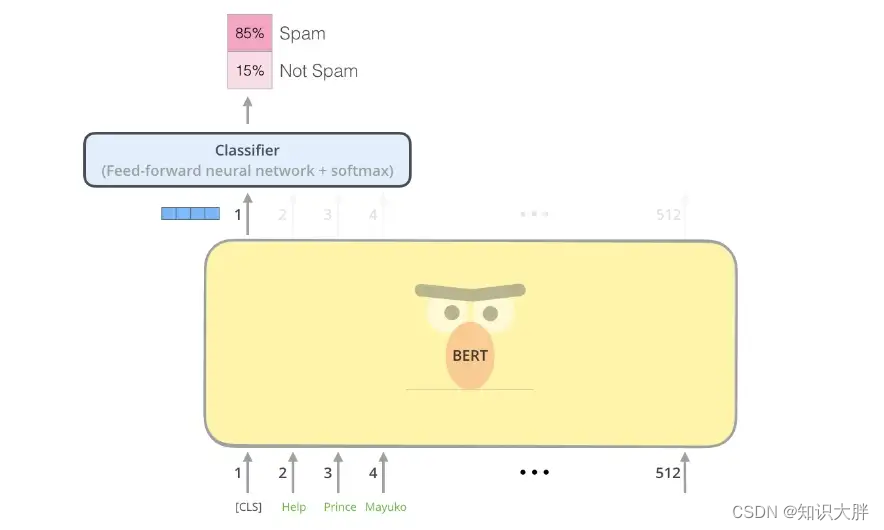
此博客将指导您使用 Huggingface Transformers 对自定义数据集的 Distillbert 进行微调。
DistilBERT 是一种小型、快速、便宜且轻便的 Transformer 模型,通过提取 BERT 基础进行训练。它比bert-base-uncased少了 40% 的参数,运行速度提高了 60%,同时保留了 BERT 在 GLUE 语言理解基准测试中超过 95% 的性能
本博客源代码:Google Colab
1.安装transformers库
按照以下链接中的这些说明安装 huggingface 库:https 😕/huggingface.co/docs/datasets/v1.11.0/installation.html
!pip install transformers
!pip install sentencepiece
我们将在本教程中使用 IMDb 数据集。IMDB 数据集是一个大型电影评论数据集。这是一个用于二元情感分类的数据集,包含比以前的基准数据集多得多的数据。他们提供了一组 25,000 条高度极端的电影评论用于训练,25,000 条用于测试。还有其他未标记的数据可供使用。我们可以通过以下步骤下载数据集。
2.下载数据集
!wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xf aclImdb_v1.tar.gz
此数据被组织到每个示例一个文本文件的文件夹中pos。read_imdb_split函数将帮助我们读取和处理数据集。neg
from pathlib import Pathdef read_imdb_split(split_dir):split_dir = Path(split_dir)texts = []labels = []for label_dir in ["pos", "neg"]:for text_file in (split_dir/label_dir).iterdir():texts.append(text_file.read_text())labels.append(0 if label_dir is "neg" else 1)return texts, labelstrain_texts, train_labels = read_imdb_split('aclImdb/train')
test_texts, test_labels = read_imdb_split('aclImdb/test')
让我们使用 Scikit-learn 中的train_test_split实用程序从训练数据集创建训练和验证集。我们将使用验证数据集使用自定义度量函数来评估和调整我们的模型。
from sklearn.model_selection import train_test_split
train_texts, val_texts, train_labels, val_labels = train_test_split(train_texts, train_labels, test_size=.2)
3.预处理输入数据
下一步是对模型的输入数据进行预处理。与清理数据一起,标记化是任何 NLP 管道中的第一步。Tokenizer 将非结构化字符串转换为适合机器学习的数字数据结构。由于我们将使用预训练的 DistilBert,因此我们将使用 DistilBert 分词器进行分词。
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)
4.数据集对象
torch.utils.data.Dataset 是 Pytorch 中表示数据集的抽象类。我们的自定义数据集将继承Dataset并覆盖以下方法:
__len__以便len(dataset)返回数据集的大小。
__getitem__支持索引,这样dataset[i]可以用来获取第i个样本。
import torchclass IMDbDataset(torch.utils.data.Dataset):def __init__(self, encodings, labels):self.encodings = encodingsself.labels = labelsdef __getitem__(self, idx):item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}item['labels'] = torch.tensor(self.labels[idx])return itemdef __len__(self):return len(self.labels)train_dataset = IMDbDataset(train_encodings, train_labels)
val_dataset = IMDbDataset(val_encodings, val_labels)
test_dataset = IMDbDataset(test_encodings, test_labels)








