您现在的位置是:主页 > news > seo排名优化软件有用吗/关键词点击优化工具
seo排名优化软件有用吗/关键词点击优化工具
![]() admin2025/5/7 12:35:11【news】
admin2025/5/7 12:35:11【news】
简介seo排名优化软件有用吗,关键词点击优化工具,网络优化工程师需要具备哪些能力,html 类似淘宝购物网站上加载时获取属性并可多选过滤 代码Masked Autoencoders Are Scalable Vision Learners MAE提出一种自监督的训练方法,该方法可以有效地对模型进行与训练,提升模型性能。本项目实现了自监督训练部分,并且可视化了训练过程。 网络结构 MAE的结构较为简单,它由编码器…
Masked Autoencoders Are Scalable Vision Learners
MAE提出一种自监督的训练方法,该方法可以有效地对模型进行与训练,提升模型性能。本项目实现了自监督训练部分,并且可视化了训练过程。
网络结构
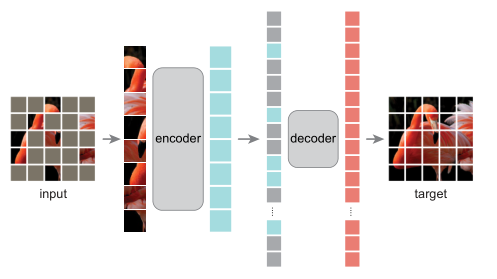
MAE的结构较为简单,它由编码器和解码器组成,这里编码器和解码器都采用了Transformer结构。对于输入图片,将其划分为patches后,对一定比例的patch进行masked(论文中比例为75%),将unmasked patches送入encoder得到encoded patches,引入masked tokens和encoded patches结合,送入decoder,decoder的输出目标是原图像,损失仅在masked patches上计算。
需要注意的细节:
1、Masking:将图像划分为不重叠的patches后,masked patches选择服从均匀分布;
2、Encoder: encoder仅作用在unmasked patches,embedding patches需要加上postion embeddings;
3、Decoder: decoder的输入由encoded patches和mask tokens组成,mask token是一个参数共享的可学习参数,同时为了mask tokens加上postion embeddings表示位置信息;
4、重构目标:decoder输出目标图片(输入原图)的每个像素值,损失仅在masked patches计算;
5、实现:
(1)对每个patch生成token;
(2)对所有token进行shuffle,然后按照masking ratio移除一部分token;
(3)得到encoded tokens后,将mask tokens和encoded tokens合并,注意这里不需要unshuffle,简单concat就可以;
本项目的内容
本项目在ImageNet 1K的验证机训练,将5W张图片的4W张用作训练数据,剩下的1W留作验证。由于训练比较慢,这里只对MAE进行预训练,masking ratio为0.5,仅训练了200个epoch,由于数据少,epoch小,效果并不是太好,但是可以看到mae的输出变化过程,没有fine-tuning过程。
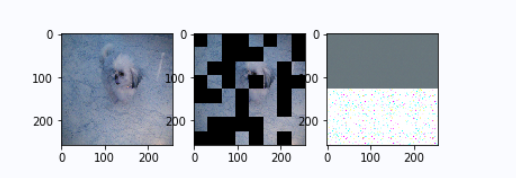
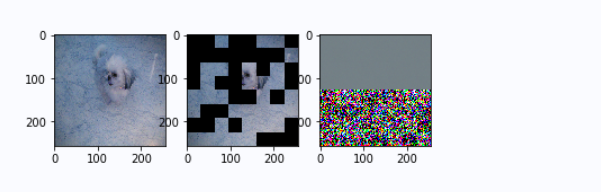
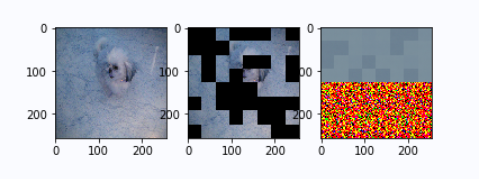
输出变化
左图是原图,中间是masked image, 右面是mae的预测结果。
epoch 1:
epoch 10:
epoch 200:
其他
参考:vit-pytorch
非常感谢朱欤老师的课程(朱老师牛逼):从零开始学视觉Transformer
Aistudio个人主页:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/312316
路过的老爷们,求求点一下喜欢,给老弟加点战斗力。
# 处理数据集
%cd ~/data/data89857/
!tar -xf ILSVRC2012mini.tar
%cd ~/# 数据集的txt文件有点问题,修正train_list内容, 运行一次就可以
import ostrain_file_path = '/home/aistudio/data/data89857/ILSVRC2012mini/train_list.txt'
data = []
with open(train_file_path, 'r') as f:lines = f.readlines()for line in lines:_, info = line.split('/')data.append(info)with open(train_file_path, 'w') as f:f.writelines(data)
ViT
ViT的实现不做过多解释,需要注意: 由于MAE的重构目标是原图的像素值,所以不要使用卷积来进行patch embedding,先对原图划分patches,然后使用linear embedding。
# VIT
import paddle
from paddle import nnclass PreNorm(nn.Layer):def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x):return self.fn(self.norm(x))class Mlp(nn.Layer):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.mlp = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout),)def forward(self, x):x = self.mlp(x)return xclass Identity(nn.Layer):def __init__(self):super().__init__()def forward(self, x):return xclass Attention(nn.Layer):def __init__(self, dim, heads=8, dim_head=64, dropout=0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** (-0.5)self.attend = nn.Softmax(axis = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias_attr=False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout),) if project_out else Identity()def forward(self, x):B, N, _ = x.shapeqkv = self.to_qkv(x).chunk(3, axis=-1)q, k, v = map(lambda t: t.reshape([B, N, self.heads, -1]).transpose([0, 2, 1, 3]), qkv)dots = paddle.matmul(q, k.transpose([0, 1, 3, 2])) * self.scaleattn = self.attend(dots)out = attn.matmul(v)out = out.transpose([0, 2, 1, 3]).flatten(2)out = self.to_out(out)return outclass Transformer(nn.Layer):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):super().__init__()self.layers = nn.LayerList()for _ in range(depth):self.layers.append(nn.LayerList([PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),PreNorm(dim, Mlp(dim, mlp_dim, dropout=dropout)),]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass PatchEmbedding(nn.Layer):def __init__(self, image_size, patch_size, embed_dim=768, in_channels=3):super().__init__()image_height, image_width = image_size if isinstance(image_size, tuple) else (image_size, image_size) self.patch_height, self.patch_width = patch_size if isinstance(patch_size, tuple) else (patch_size, patch_size)assert image_height % self.patch_height == 0 and image_width % self.patch_width == 0, "Image dimensions must be divisible by the patch size."self.p1, self.p2 = (image_height // self.patch_height), (image_width // self.patch_width)self.num_patches = (image_height // self.patch_height) * (image_width // self.patch_width)self.patch_embed = nn.Linear(in_channels * self.patch_height * self.patch_width, embed_dim)def forward(self, x):N, C, H, W = x.shapepatches = x.reshape([N, C, self.p1, self.patch_height, self.p2, self.patch_width]).transpose([0, 2, 4, 1, 3, 5]).reshape([N, self.num_patches, -1])x = self.patch_embed(patches)x = x.flatten(2)return x, patchesclass ViT(nn.Layer):def __init__(self, image_size, patch_size, num_classes, depth, heads,mlp_dim, embed_dim=768,pool='cls',channels=3,dim_head=64,dropout=0,embed_dropout=0.,):super().__init__()assert pool in {'cls', 'mean'}, 'pool type nums be either cls(cls token) or mean (mean pooling).'self.embed_dim = embed_dimself.patch_embedding = PatchEmbedding(image_size, patch_size, embed_dim=embed_dim, in_channels=channels)self.num_patches = self.patch_embedding.num_patchesself.pos_embedding = self.create_parameter(shape=[1, self.num_patches + 1, embed_dim], default_initializer=nn.initializer.KaimingNormal(0.02))self.cls_token = self.create_parameter(shape=[1, 1, embed_dim])self.dropout = nn.Dropout(embed_dropout)self.transformer = Transformer(embed_dim, depth, heads, dim_head, mlp_dim, dropout)self.pool = poolself.to_latent = Identity()self.mlp_head = nn.Sequential(nn.LayerNorm(embed_dim),nn.Linear(embed_dim, num_classes),)def forward(self, x):x, patches = self.patch_embedding(x)B, N, _ = x.shapecls_tokens = paddle.tile(self.cls_token, [B, 1, 1])x = paddle.concat([cls_tokens, x], axis=1)x += self.pos_embedding[:, :(N + 1)]x = self.dropout(x)x = self.transformer(x)x = x.mean(axis=1) if self.pool == 'mean' else x[:, 0]x = self.to_latent(x)x = self.mlp_head(x)return x# if __name__ == '__main__':
# model = ViT(image_size=(256,256),
# patch_size=(32,32),
# num_classes=1000,
# embed_dim=1024,
# heads=8,
# depth=6,
# mlp_dim=2048, )
# x = paddle.randn([2, 3, 256, 256])# y = model(x)
# print(x.shape, y.shape)
# paddle.summary(model, (4, 3, 256, 256))MAE
MAE的encoder就是ViT,decoder是一个transformer模型。
import paddle
from paddle import nn
import paddle.nn.functional as Fclass MAE(nn.Layer):def __init__(self, encoder, decoder_dim, masking_ratio=0.75, decoder_depth=1, decoder_heads=8, decoder_dim_head=64):super().__init__()assert masking_ratio > 0 and masking_ratio < 1, 'masking ratio must in range (0, 1), but got {}.'.format(masking_ratio)self.masking_ratio = masking_ratioself.encoder = encoderpatch_dim = self.encoder.patch_embedding.patch_embed.weight.shape[0] # 划分后每个patches的dimself.enc_to_dec = nn.Linear(encoder.embed_dim, decoder_dim) if encoder.embed_dim != decoder_dim else Identity()self.mask_token = self.create_parameter(shape=(1, 1, decoder_dim)) # mask_token 共享的可学习参数self.decoder = Transformer(dim=decoder_dim, depth=decoder_depth, heads=decoder_heads, dim_head=decoder_dim_head, mlp_dim=decoder_dim*4) # 解码器self.decoder_pos_emb = nn.Embedding(encoder.num_patches, decoder_dim) # decoder position embeddingself.to_pixels = nn.Linear(decoder_dim, patch_dim)def forward(self, x):tokens, patches = self.encoder.patch_embedding(x) # patches 是在原图划分的patches,用作targetbatch, num_patches, _ = tokens.shape # batch_size, num_patches, _tokens = tokens + self.encoder.pos_embedding[:, 1:(num_patches + 1)]# mask part of patches,均匀分布采样num_masked = int(self.masking_ratio * num_patches)rand_indices = paddle.rand(shape=[batch, num_patches]).argsort(axis=-1)masked_indices, unmasked_indices = rand_indices[:, :num_masked], rand_indices[:, num_masked:]# unmasked tokens to be encodedbatch_range = paddle.arange(batch)[:, None]tokens = tokens[batch_range, unmasked_indices]# masked_patchesmasked_patches = patches[batch_range, masked_indices] # 仅在masked patches计算损失# transformerencoded_tokens = self.encoder.transformer(tokens)decoder_tokens = self.enc_to_dec(encoded_tokens)# decoder embedmask_tokens = paddle.tile(self.mask_token, [batch, num_masked, 1]) # decoder position embeddingmask_tokens = mask_tokens + self.decoder_pos_emb(masked_indices) # learned mask tokendecoder_tokens = paddle.concat([mask_tokens, decoder_tokens], axis=1) # 不需要unshuffledecoded_tokens = self.decoder(decoder_tokens)if self.training:mask_tokens = decoded_tokens[:, :num_masked]pred = self.to_pixels(mask_tokens) # N, num_unmasked, dimloss = F.mse_loss(pred, masked_patches)return losselse:image = patches.clone() # 采样后的图image.stop_gradient = Trueimage[batch_range, masked_indices] = 0 # mask sampling areapred = self.to_pixels(decoded_tokens)return pred, image# if __name__ == '__main__':
# encoder = ViT(image_size=256,
# patch_size=32,
# num_classes=1000,
# embed_dim=1024,
# heads=8,
# depth=6,
# mlp_dim=2048)
# model = MAE(encoder, masking_ratio=0.75, decoder_dim=512, decoder_depth=6)
# x = paddle.randn([4, 3, 256, 256])
# y = model(x)
# print(x.shape, y.shape)
# paddle.summary(model, (4, 3, 256, 256))
dataset
# 构建dataset
from paddle.io import Dataset, DataLoader
import paddle.vision.transforms as T
import cv2
import osclass ImageNetDataset(Dataset):def __init__(self, data_dir, info_txt, mode='train', transforms=None):self.data_dir = data_dirself.image_paths, self.labels = self.get_info(info_txt)self.mode = modeself.transforms = transformsdef get_info(self, file_path):paths = []labels = []with open(file_path, 'r') as f:lines = f.readlines()for line in lines:image_name, label = line.strip().split(' ')paths.append(os.path.join(self.data_dir, image_name))labels.append(int(label))return paths, labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):image_path = self.image_paths[idx]label = self.labels[idx]image = cv2.imread(image_path)if self.transforms:image = self.transforms(image)if self.mode == 'train':return image, labelelse:return image# mae_train_trans = T.Compose(
# [
# T.Resize((256, 256)),
# T.RandomHorizontalFlip(),
# T.RandomVerticalFlip(),
# T.Transpose([2, 0, 1]),
# ]
# )# if __name__ == '__main__':
# dataset = ImageNetDataset('/home/aistudio/data/data89857/ILSVRC2012mini/train', '/home/aistudio/data/data89857/ILSVRC2012mini/train_list.txt', mode='val', transforms=mae_train_trans)
# print(len(dataset))
# image = dataset[0]
# import matplotlib.pyplot as plt
# plt.imshow(image)
# plt.show()预训练MAE
# 辅助类
class AverageMeter:def __init__(self):self.val = 0.self.count = 0.def update(self, value, n=1):self.val += valueself.count += ndef reset(self):self.val = 0.self.count = 0.def __call__(self):return self.val / self.count
# 设置相关参数
import timeepoches = 2000
batch_size = 256
learning_rate = 0.00001
grad_clip_value = 10# encoder param
patch_size = (32, 32)
image_size = (256, 256)
num_classes = 1000
encoder_embed_dim = 1024
encoder_heads = 8
encoder_depth = 6
encoder_mlp_dim = 2048# decoder params
masking_ratio = 0.5
decoder_dim = 512
decoder_depth = 6mae_train_trans = T.Compose([T.Resize((256, 256)),T.RandomHorizontalFlip(),T.RandomVerticalFlip(),T.Transpose([2, 0, 1]),]
)
# mode = 'val',因为预训练不需要label,加上也可以
mae_dataset = ImageNetDataset('/home/aistudio/data/data89857/ILSVRC2012mini/train', '/home/aistudio/data/data89857/ILSVRC2012mini/train_list.txt', mode='val', transforms=mae_train_trans)
mae_dataloader = DataLoader(mae_dataset,batch_size=batch_size,shuffle=True,drop_last=True,
)# MAE model
encoder = ViT(image_size=image_size, patch_size=patch_size, num_classes=num_classes, embed_dim=encoder_embed_dim,heads=encoder_heads,depth=encoder_depth, mlp_dim=encoder_mlp_dim)
model = MAE(encoder, masking_ratio=masking_ratio, decoder_dim=decoder_dim, decoder_depth=decoder_depth)
# paddle.summary(model, (4, 3, 256, 256))
clip = paddle.nn.ClipGradByValue(min=-grad_clip_value, max=grad_clip_value)
optimizer = paddle.optimizer.Momentum(learning_rate=learning_rate, parameters=model.parameters(), grad_clip=clip)# 测试函数,用一张图片可视化训练过程
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlinedef reconstruct(x, image_size, patch_size):"""reconstrcunt [batch_size, num_patches, embedding] -> [batch_size, channels, h, w]"""B, N, _ = x.shape # batch_size, num_patches, dimp1, p2 = image_size[0] // patch_size[0], image_size[1] // patch_size[1] x = x.reshape([B, p1, p2, -1, patch_size[0], patch_size[1]]).transpose([0, 3, 1, 4, 2, 5]).reshape([B, -1, image_size[0], image_size[1]])return xdef test(model):"""使用模型预测一个图片,查看效果,可以看出模型训练过程预测的变化趋势"""model.eval()image_path = '/home/aistudio/data/data89857/ILSVRC2012mini/val/ILSVRC2012_val_00040043.JPEG'source_image = cv2.imread(image_path)trans = T.Compose([T.Resize((256, 256)),T.Transpose([2, 0, 1]),])source_image = trans(source_image)image = paddle.to_tensor(source_image, dtype='float32').unsqueeze(0)pred, masked_img = model(image)pred_img = reconstruct(pred, image_size, patch_size)masked_img = reconstruct(masked_img, image_size, patch_size)masked_img = masked_img[0].numpy()masked_img = np.clip(masked_img, 0, 255).astype('uint8')masked_img = np.transpose(masked_img, [1, 2, 0])pred_img = pred_img[0].numpy()pred_img = np.clip(pred_img, 0, 255).astype('uint8')pred_img = np.transpose(pred_img, [1, 2, 0])plt.subplot(1, 3, 1)plt.imshow(source_image.transpose([1, 2, 0]))plt.subplot(1, 3, 2)plt.imshow(masked_img)plt.subplot(1, 3, 3)plt.imshow(pred_img)plt.show()return pred_img# 训练model.train()
for epoch in range(1, epoches + 1):losses = AverageMeter()for batch_id, image in enumerate(mae_dataloader):image = image.astype('float32')loss = model(image)losses.update(loss.numpy()[0])loss.backward()optimizer.step()optimizer.clear_grad()lr = optimizer.get_lr()if batch_id % 50 == 0:print(time.asctime( time.localtime(time.time()) ), "Epoch: {}/{}, Batch id: {}, lr: {}, loss: {}".format(epoch, epoches, batch_id, lr, losses()))obj = {'model': encoder.state_dict(),'epoch': epoch,}paddle.save(obj, 'model.pdparams')obj = {'model': model.state_dict(),'epoch': epoch,}paddle.save(obj, 'mae.pdparams')test(model) # 这里会变成eval模式model.train() # 转成train模式
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.








