您现在的位置是:主页 > news > 买app的网站建设/精准网络营销推广
买app的网站建设/精准网络营销推广
![]() admin2025/5/4 23:48:47【news】
admin2025/5/4 23:48:47【news】
简介买app的网站建设,精准网络营销推广,台州知名网站,仿做网站的网站文章目录一.为什么要用NoSql二.NoSql能干嘛易扩展大数量高性能多样灵活的数据模式传统的 RDBMS VS NOSQL三.NoSql数据如何存放?NoSQL数据库的四大分类CAPCAP 概念CAP的三进二BASE分布式 集群简介四.启动后的杂项基础测压命令单进程五.五大数据类型类型含义各种命令…
文章目录
- 一.为什么要用NoSql
- 二.NoSql能干嘛
- 易扩展
- 大数量高性能
- 多样灵活的数据模式
- 传统的 RDBMS VS NOSQL
- 三.NoSql数据如何存放?
- NoSQL数据库的四大分类
- CAP
- CAP 概念
- CAP的三进二
- BASE
- 分布式 + 集群简介
- 四.启动后的杂项基础
- 测压命令
- 单进程
- 五.五大数据类型
- 类型含义
- 各种命令:
- 六.redis 的持久化
- 七. redis 的缓存穿透和雪崩
- 缓存的穿透:
- 缓存击穿
- 缓存雪崩
- 参考文献
一.为什么要用NoSql
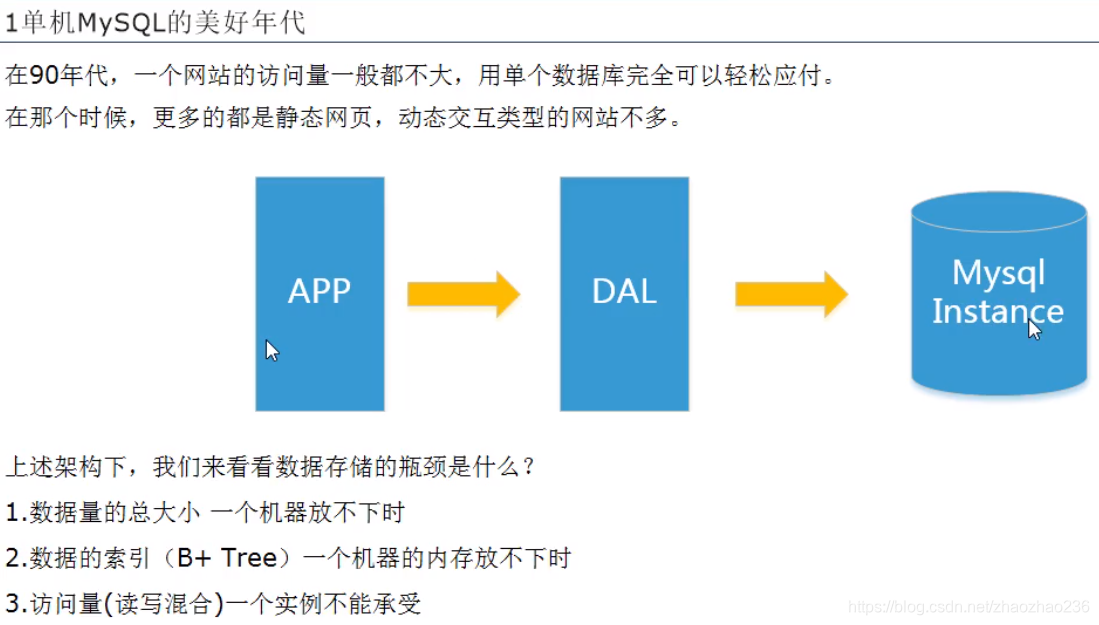
单击mysql的美好年代:
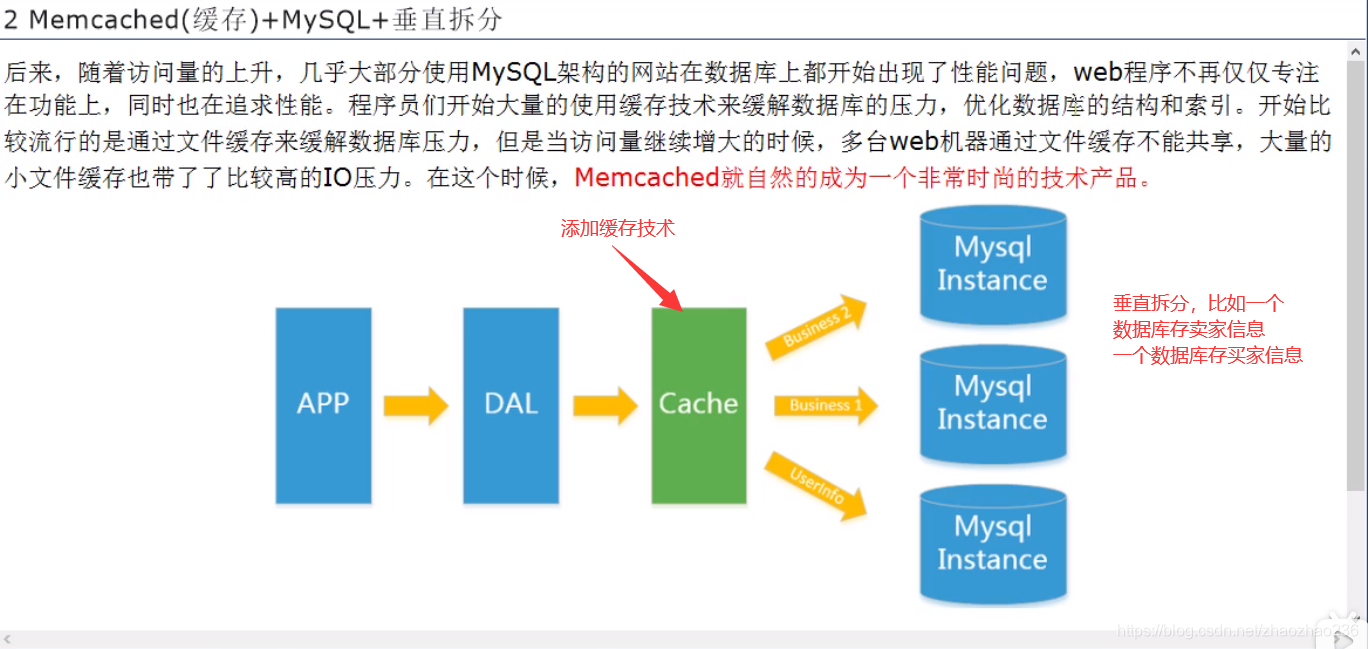
mysql+cache+垂直拆分:
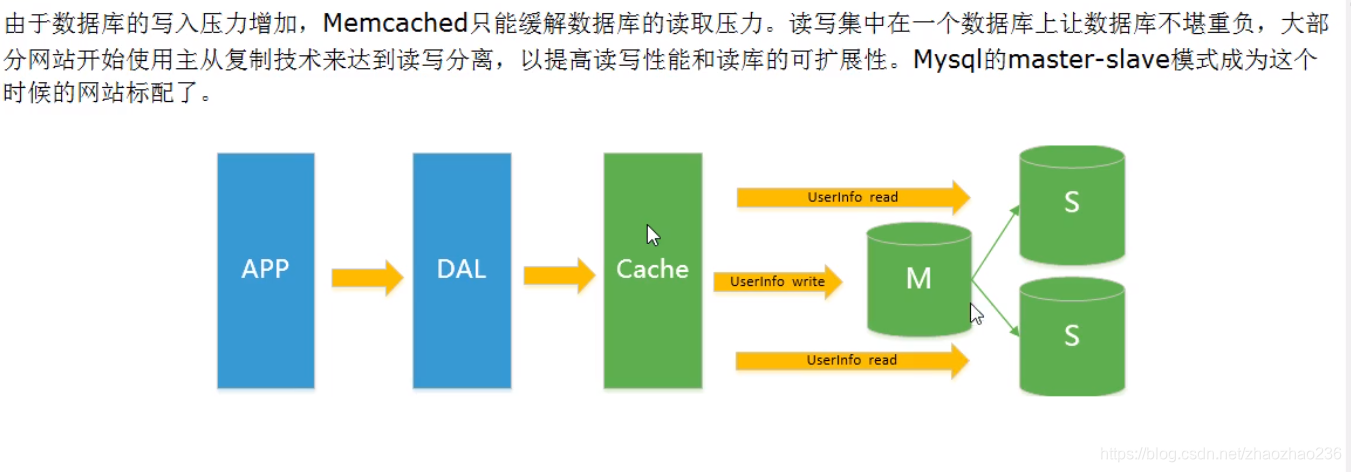
mysql主从读写分离:
主数据库里只管写,从数据库里只管读。
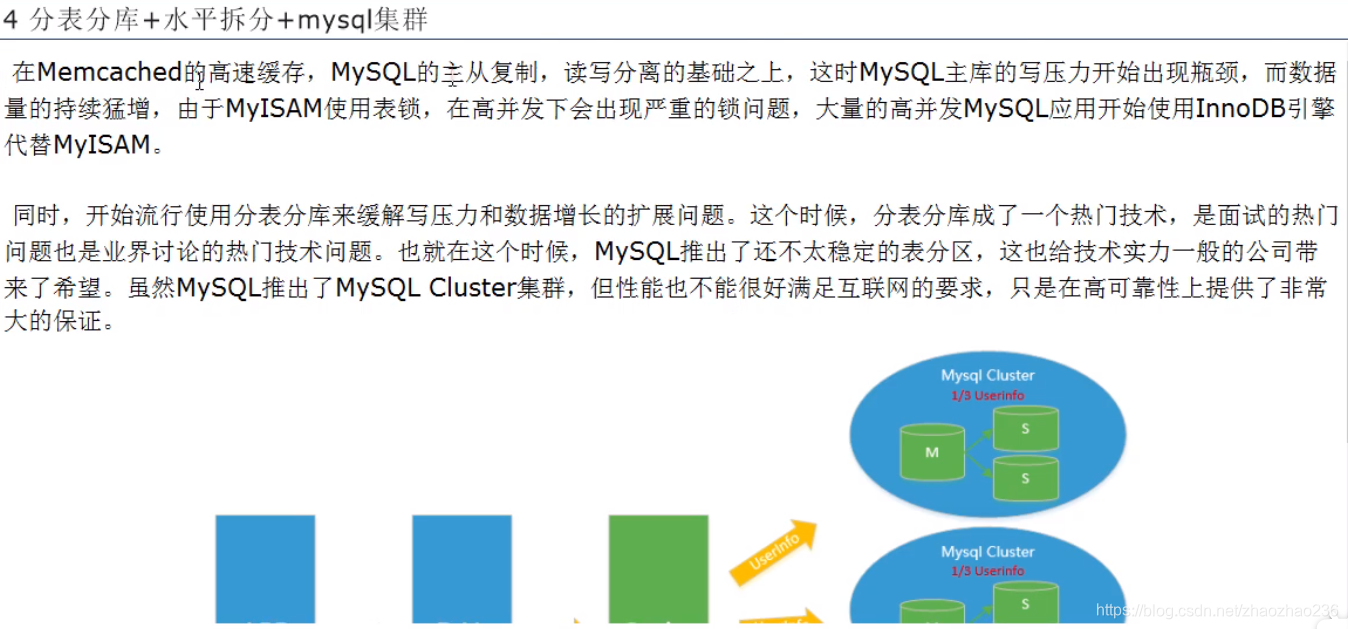
分表分库+水平拆分+mysql集群
今天的样子:
二.NoSql能干嘛
易扩展
数据库的种类繁多,他们的共同特征都是去掉了关系型数据库的关系型特征,数据非常容易扩展。
大数量高性能
写的话,最快一秒8万次,读的话可以达到11万次。
多样灵活的数据模式
NoSql 无需事前为要存储的数据建立字段,随时可以存储自定义的数据格式,而在关系型数据库里,增删字段是非常麻烦的,如果非常大数据量的表,增加字段简直就是一个噩梦。
传统的 RDBMS VS NOSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语句(SQL)
- 数据和关系都存储在单独的表中
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非
ACID属性 CAP定理- 非结构化和不可预知的数据
- 高性能,高可用和可伸缩性
三.NoSql数据如何存放?
以 阿里巴巴 中文网为例
- 商品基本信息: 基本不变的信息,就放在
mysql中。 - 商品的描述,评价信息: 多文字,像长文本一样的东西,就放在
文档型数据库MongDB中 - 商品的图片: 分布式的文件系统中,淘宝自己的
TFS - 商品的关键字: 搜索引擎
ISearch - 商品的波段性和热点高频信息: 比如情人节的巧克力,可以使用
内存数据库Redis - 商品的交易、价格计算、积分累计:
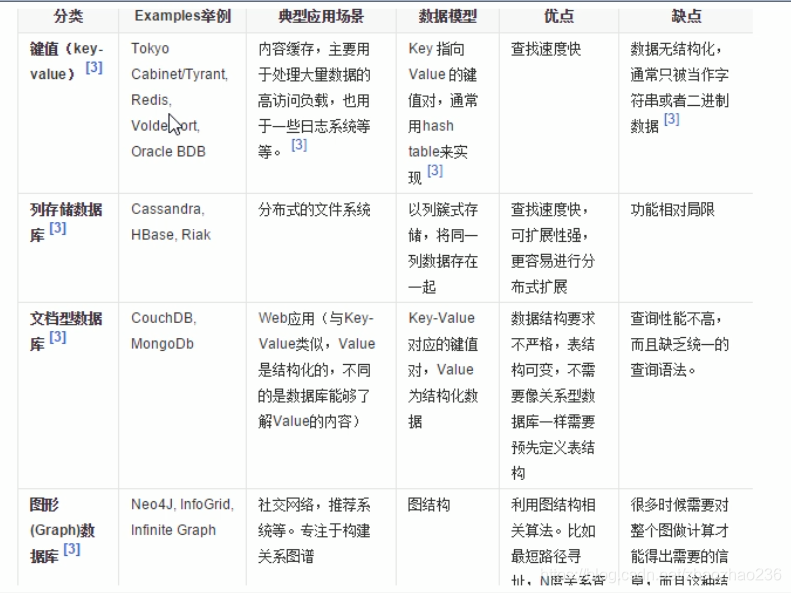
NoSQL数据库的四大分类
- KV键值
- 文档型数据库
- 列存储数据库
- 图关系数据库
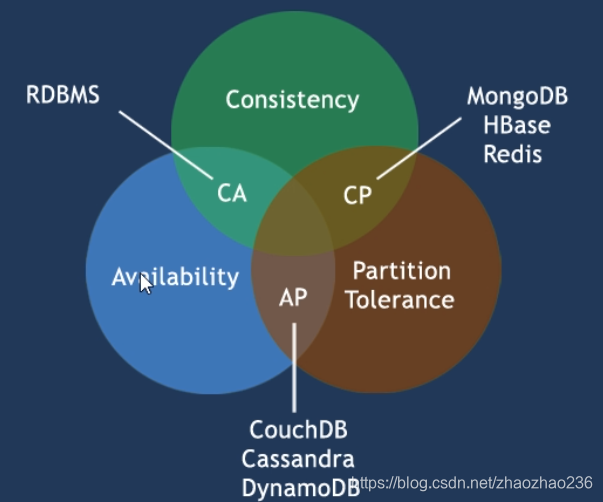
CAP
CAP 概念
- C:
Consistency(强一致性)数据是什么就是什么。在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本) - A:
Availability(可用性)保证每个请求不管成功或者失败都有响应。 - P:
Partition tolerance(分区容错性)系统中任意信息的丢失或失败不会影响系统的继续运作。
CAP的三进二

BASE
- 基本可用(Basically Available)
- 软状态 (Soft state)
- 最终一致 (Eventually consistent)
分布式 + 集群简介
- 分布式: 不同的多台服务器上面部署不同的服务模块(工程),他们之间通过
Rpc/Rmi之间通信和调用,对外提供服务和组内协作。 - 集群: 不同的服务器上面部署不同的服务模块,通过分布式调用软件进行统一的调度,对外提供服务和访问。
四.启动后的杂项基础
测压命令
向一百个线程中测试十万个数据
redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
单进程
单进程模型来处理客户端的请求,对读写等事件的相应,是通过对epoll 函数的包装来做到的,Redis 的实际处理速度,完全依靠主进程的执行速度。
默认有16个数据库:
select 2 // 表示选择的是第3个数据库,因为下表示从0开始的。keys * // 查看当前数据库下所有的的keydbsize // 整个数据库所有的键值对的个数keys k? // 使用占位符查找flushall //清空所有的数据
flushdb // 清空当前数据库的数据
五.五大数据类型
- string
- hash
- list
- set
- zset
类型含义
string 类型是redis的基本类型,一个key 对应一个 value 。
string 类型的二进制是安全的,也就是redis可以包含任何类型,比如jpg图片,还有序列化后的对象 。
string 最大可以支持 512 M 。
Hash(哈希)是一个键值对集合,是一个string对象的
field和value的映射表,hash特别适合用于存储对象
List :字符串列表,按照插入的顺序排序
set : 无序的字符串列表,无序无重复。
zset::有序集合:zset 和 set 一样,也是string 类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个 double 类型的分数。redis 正式通过分数为集合中的成员进行从小到大排序。zset 的成员是唯一的,但分数却是可以重复的。
各种命令:
对key的操作:
get k3keys *exists k1是否存在k1这个键ttl k1time to list 到什么时候到期 ,返回 -1 表示永远有效,返回 -2 表示已经被删除。expire k3 10将k3的过期时间设置为 10sset k3 m1将 k3 的值进行覆盖type k1查看 key 的类型
sting类型
get、set、del、append、strlenIncr、decr、incrby、decrby一定要是数字才能加减setex(set with expire)、setnx(set if not exist)mset、mget、msetnx同时设置多个。
List:
list:的性能总结
他是一个字符串链表,左右都可以插,如果键不存在,创建新的链表,如果键已经存在,新增内容,如果值全移除了,对应的键也消失了,无论是从头还是尾插都效率极高,但是从中间插的话,效率就惨淡了。
lpush list01 1 2 3 4 5 6 7 8 9 // 插入值lrange list01 0 -1 // 查看值lpop //从栈顶取出一个值LINDEX list01 3 //查看指定位置的数据llen list01 //长度ltrim list01 0 3 // 把 从 0 到 3 的值都剪掉LREM list01 1 8 //删掉连续的值RPOPLPUSH list01 list02 // 从左边的地下取下来一个压到第二个的顶上linsert list01 before 6 csharp //在前边插入linsert list01 after 6 golang // 在后面插入
Set
无序无重复
sadd set01 1 2 3 4 5 6 7 8 9 //创建一个sadd set02 1 2 3 4 5 a b c d // 创建一个smembers set01 // 查看成员sismember set01 12 // 查看是否包含该成员scard set01 // 成员的容量srem set01 1 // 删除一个srandmember set01 3 //随机的选出来三个spop set01 2 //随机的抛出两个smove set02 set01 a // 把set02 中的某个值,放到set01中sdiff set01 set02 //求差集sinter set01 set02 // 求交集sunion set01 set02 //求并集
hash
1. hget student01 name // 添加值
2. hmset student01 name zhang age 18 gender boy //批量添加值
3. hmget student01 name age //批量获得值
4. hgetall student01 //获得所有属性
5. hdel student01 gender //删除某个属性
6. hexists student01 name //查看某个属性是否存在
7. hkeys student01 //获得所有的key
8. hvals student01 //获得所有的value
9. hincrby student01 age 2 //某个值加+2
10. hsetnx student01 email 136.com //不存在的话+1,存在的话添加失败
zset
1. zadd zset01 60 v1 70 v2 80 v3 // 复制
2. zrange zset01 0 -1 //产看key
3. zrange zset01 0 -1 withscores //带着key-vule 一块看
4. zrangebyscore zset01 60 70 //产看分数在这个范围内的
5. zrangebyscore zset01 60 (70 //不包含70
6. zrangebyscore zset01 60 70 limit 0 1 //从0开始选一个
7. zcard zset01 // 求长度
8. zcount zset01 60 80 // 60-80之间的长度
9. zrank zset01 v2 //v2的排序号
10. zscore zset01 v1 //v1的分数
11. zrevrange zset01 0 -1 //将数据反着来
六.redis 的持久化
- rdb
- aof
七. redis 的缓存穿透和雪崩
这都是涉及到服务器的高可用的部分。
缓存的穿透:
缓存穿透的概念很简单,如果用户想要查询一个数据,发现 redis 内存数据库里没有,那么 就会向mysql 查询,结果也没有,于是本次查询失败,当用户很多的时候,缓存都没有命中,于是都去请求 mysql 数据库,这会给 mysql 数据库造成很大的压力,这时候就相当于出现了缓存穿透。

解决方案: 布隆过滤器

缓存空对象

缓存击穿
缓存击穿是指一个 key 非常的热点,在不停的扛着大并发,大并发集中对一个点进行访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在屏障上凿开一个洞。 当某 key 在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新的数据,并写会缓存,会导致使服务器瞬间压力过大。
解决方案:
使用分布式锁。加锁只保证只有一个线程加进去。其余的都在等待。
缓存雪崩
产生雪崩的是指一个时间段内,缓存集中过期失效,redis 宕机了!
参考文献
https://www.bilibili.com/video/BV1oW411u75R?share_source=copy_web








