您现在的位置是:主页 > news > 扬州做网站的公司哪个好/企业官网推广
扬州做网站的公司哪个好/企业官网推广
![]() admin2025/5/2 12:43:14【news】
admin2025/5/2 12:43:14【news】
简介扬州做网站的公司哪个好,企业官网推广,搭建网站详细步骤,仿素材下载网站源码一、heapq库简介heapq 库是Python标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法。堆是一种基本的数据结构,堆的结构是一棵完全二叉树,并且满足堆积的性质&am…
扬州做网站的公司哪个好,企业官网推广,搭建网站详细步骤,仿素材下载网站源码一、heapq库简介heapq 库是Python标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法。堆是一种基本的数据结构,堆的结构是一棵完全二叉树,并且满足堆积的性质&am…

一、heapq库简介
heapq 库是Python标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法。堆是一种基本的数据结构,堆的结构是一棵完全二叉树,并且满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点。堆结构分为大顶堆和小顶堆,在heapq中使用的是小顶堆:1. 大顶堆:每个节点(叶节点除外)的值都大于等于其子节点的值,根节点的值是所有节点中最大的。2. 小顶堆:每个节点(叶节点除外)的值都小于等于其子节点的值,根节点的值是所有节点中最小的。在heapq库中,heapq使用的数据类型是Python的基本数据类型 list ,要满足堆积的性质,则在这个列表中,索引 k 的值要小于等于索引 2*k+1 的值和索引 2*k+2 的值(在完全二叉树中,将数据按广度优先插入,索引为k的节点的子节点索引分别为2*k+1和2*k+2)。在heapq库的源码中也有介绍,可以读一下heapq的源码,代码不多。使用Python实现堆排序可以参考:Python实现堆排序完全二叉树的特性可以参考:二叉树简介二、使用heapq创建堆
# coding=utf-8import heapqarray = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]heap = []for num in array: heapq.heappush(heap, num)print("array:", array)print("heap: ", heap)heapq.heapify(array)print("array:", array)array: [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]heap: [5, 7, 21, 15, 10, 24, 27, 45, 17, 30, 36, 50]array: [5, 7, 21, 10, 17, 24, 27, 45, 15, 30, 36, 50]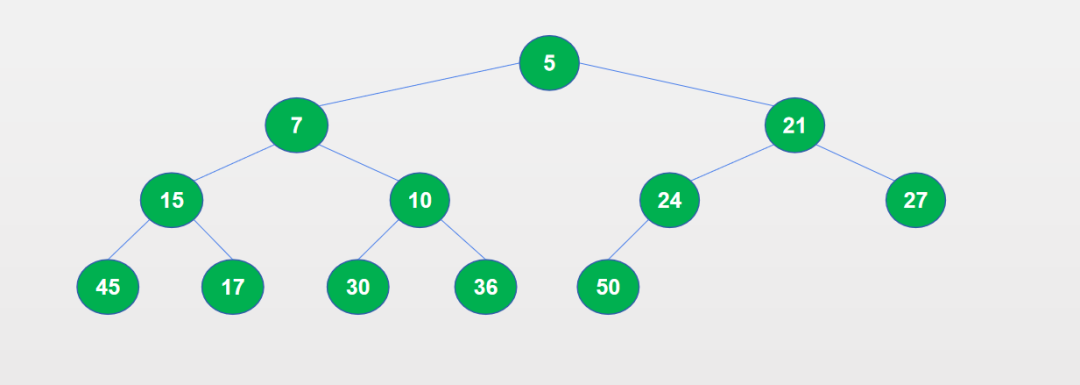
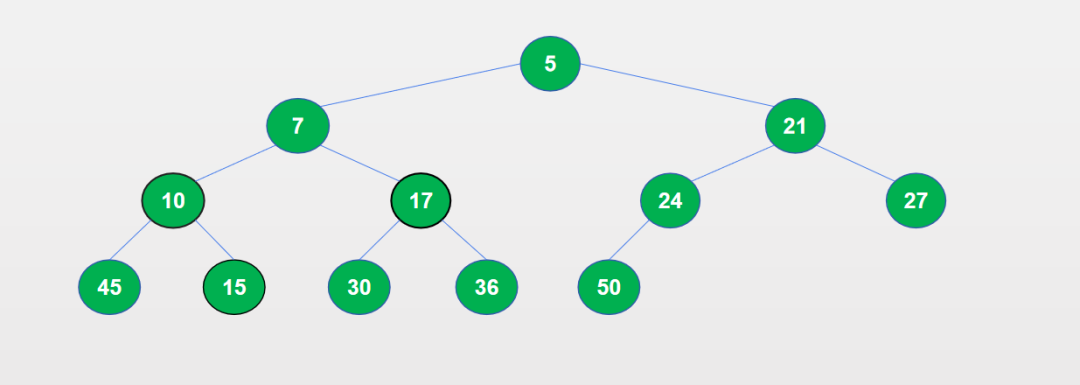
三、使用heapq实现堆排序
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]heap = []for num in array: heapq.heappush(heap, num)print(heap[0])# print(heapq.heappop(heap))heap_sort = [heapq.heappop(heap) for _ in range(len(heap))]print("heap sort result: ", heap_sort)5heap sort result: [5, 7, 10, 15, 17, 21, 24, 27, 30, 36, 45, 50]四、获取堆中的最小值或最大值
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]heapq.heapify(array)print(heapq.nlargest(2, array))print(heapq.nsmallest(3, array))[50, 45][5, 7, 10]五、使用heapq合并两个有序列表
array_a = [10, 7, 15, 8]array_b = [17, 3, 8, 20, 13]array_merge = heapq.merge(sorted(array_a), sorted(array_b))print("merge result:", list(array_merge))merge result: [3, 7, 8, 8, 10, 13, 15, 17, 20]六、heapq替换数据的方法
array_c = [10, 7, 15, 8]heapq.heapify(array_c)print("before:", array_c)# 先push再popitem = heapq.heappushpop(array_c, 5)print("after: ", array_c)print(item)array_d = [10, 7, 15, 8]heapq.heapify(array_d)print("before:", array_d)# 先pop再pushitem = heapq.heapreplace(array_d, 5)print("after: ", array_d)print(item)before: [7, 8, 15, 10]after: [7, 8, 15, 10]5before: [7, 8, 15, 10]after: [5, 8, 15, 10]7








