Python的queue介绍
Python的队列,内置的有两种,一种是线程queue,另一种是进程queue,但是这两种queue都是只能在同一个进程下的线程间或者父进程与子进程之间进行队列通讯,并不能进行程序与程序之间的信息交换。这种情况下,就要引用一个中间件,来实现程序之间的通讯。可实现的工具有 Redis\httpsqs\RabbitMQ等,以RabbitMQ为例。
RabbitMQ
MQ并不是python内置的模块,而是一个需要你额外安装的程序,安装完毕后可通过python中内置的pika模块来调用MQ发送或接收队列请求。接下来我们就看几种python调用MQ的模式与方法。
Centos 7 进行RabbitMQ 安装流程,如下:
Centos7安装RabbitMQ
先安装Erlang
#rpm -Uvh http://www.rabbitmq.com/releases/erlang/erlang-18.1-1.el7.centos.x86_64.rpm安装rabbitmq-server
#rpm -Uvh http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.6/rabbitmq-server-3.5.6-1.noarch.rpm查看rabbitmq-server有没有安装好,能查到说明已经安装成功了
#rpm -qa|grep rabbitmq用以下命令安装维护插件:
#rabbitmq-plugins enable rabbitmq_management 开启rabbit-server用以下命令:
#service rabbitmq-server restart用以下命令查看rabbit-server当前状态
#rabbitmqctl status创建一个账户,赋予管理员权限
# rabbitmqctl add_user chen1203 chen1203. (账号 密码)
# rabbitmqctl set_user_tags chen1203 administrator命令查看创建完的账号
#rabbitmqctl list_users删除用户
#rabbitmqctl delete_user username修改密码
#rabbitmqctl oldPassword Username newPassword浏览器:http://外网ip:15672/ 登录
重要概念理解:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务
1、RabbitMQ 简单远程调用示例
将使用Python编写两个小程序:
发送单个消息的生产者(发送者),以及接收消息并将其打印出来的消费者(接收者)。这是一个消息传递的“Hello World”。
图中,“P”是我们的生产者,“C”是我们的消费者。中间的盒子是一个队列 - RabbitMQ代表消费者保存的消息缓冲区。
整体设计将如下所示:
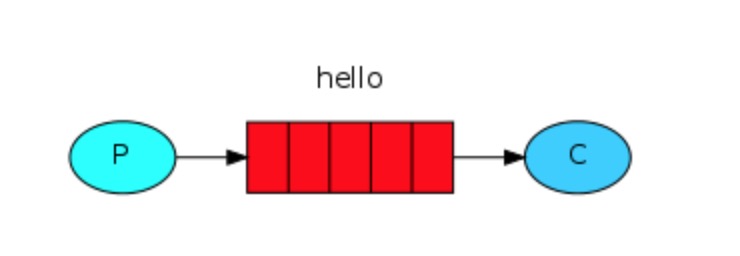
P:生产者简称,一个发送消息的程序是一个生产者。尽管消息流经RabbitMQ或者您的应用程序,但它们只能存储在队列中。一个队列只受主机内存和磁盘限制的约束,它本质上是一个很大的消息缓冲区。许多生产者可以发送进入一个队列的消息,并且许多消费者可以尝试从一个队列接收数据。
hello:queue_name 队列名称。这里命名为hello 。生产者发送信息到队列,消费者从队列中取数据。
C:消费与接受有类似的意义。一个消费者是一个程序,主要是等待接收信息。
举例:
生产者:RabbitMQ_producers.py
import pikarabbitmq_passwd = pika.PlainCredentials('chen12034','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel() #声明一个管道#声明queue队列
channel.queue_declare(queue='hello')channel.basic_publish(exchange='',routing_key='hello', #队列名字body='Hello World!') #消息内容
print(" [x] Sent 'Hello World!'")
connection.close() #队列关闭消费者:RabbitMQ_client.py
import pikarabbitmq_passswd = pika.PlainCredentials('chen12034','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passswd))channel = connection.channel() #声明一个管道#声明queue队列,
channel.queue_declare(queue='hello')#ch 管道的内存对象地址
def callback(ch, method, properties, body):print(" [x] Received %r" % body)#开始消费消息 声明语法
channel.basic_consume(callback, #调用函数,如果收到消息就调用函数来处理消息queue='hello',no_ack=True)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收队列打印信息如下:
生产者:
[x] Sent 'Hello World!'消费者:[*] Waiting for messages. To exit press CTRL+C[x] Received b'Hello World!'[x] Received b'Hello World!'[x] Received b'Hello World!' 结论:消费者只要一启动,就会启动在那里,不停的收取信息。除非CTRL+c终止,进程。这里模拟生产者,每次只发送一次信息。可以多执行几次。
插播报错信息处理流程:
远程调用RabbitMQ端口报错,报错如下:
/Library/Frameworks/Python.framework/Versions/3.5/bin/python3.5 /Users/mac/PycharmProjects/untitled2/51CTO/7days/rabbitmq_producers.py
Traceback (most recent call last):File "/Users/mac/PycharmProjects/untitled2/51CTO/7days/rabbitmq_producers.py", line 4, in <module>connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.5.4',5672,'/',rabbitmq_passwd))File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/pika-0.11.2-py3.5.egg/pika/adapters/blocking_connection.py", line 374, in __init__File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/pika-0.11.2-py3.5.egg/pika/adapters/blocking_connection.py", line 414, in _process_io_for_connection_setupFile "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/pika-0.11.2-py3.5.egg/pika/adapters/blocking_connection.py", line 466, in _flush_output
pika.exceptions.ProbableAccessDeniedError: (-1, 'EOF')
修改 RabbitMQ用户权限,流程如下:
调整RabbitMQ 用户访问权限:把NO access 改为 /。
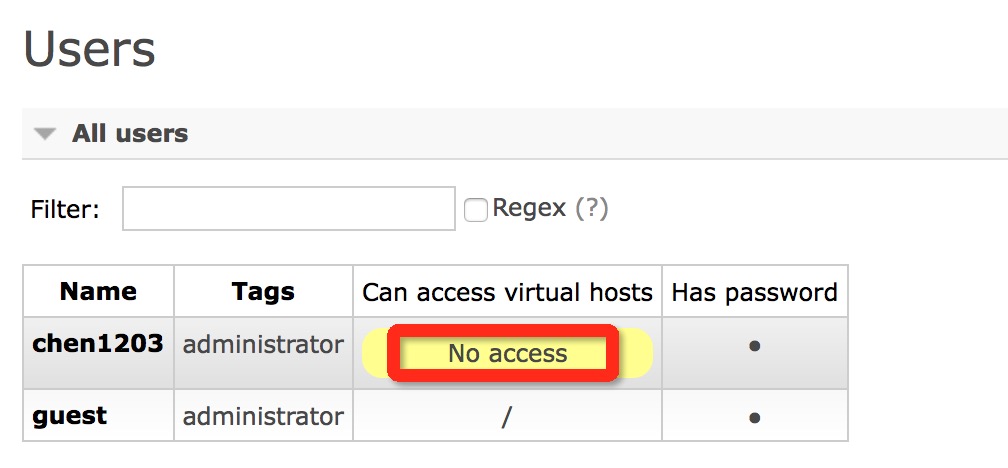
可点击用户名设置:

或者使用命令调整:#rabbitmqctl set_permissions -p '/' chen1203 ".*" ".*" ".*"Setting permissions for user "chen1203" in vhost "/" ...
效果如下:

2、RabbitMQ 队列消息分发轮询
A、消息分发轮询
整体设计将如下所示:
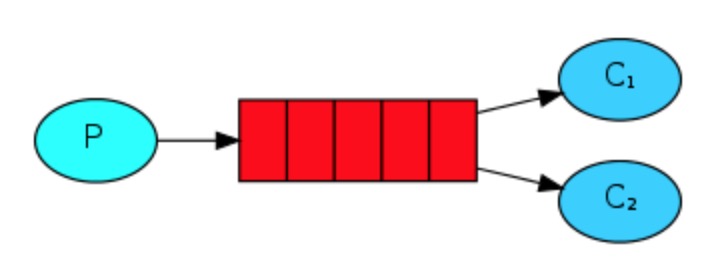
启动三个消费者程序,多次执行生产程序发送消息。观察发现消费者会先启动优先接收的原则,进行获取。模拟过程中,可以加入time.sleep()参数。
举例如下:
生产者:
import pikarabbitmq_passwd = pika.PlainCredentials('chen1203','chen1203..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.5.4',5672,'/',rabbitmq_passwd))channel = connection.channel() #声明一个管道#声明queue队列
channel.queue_declare(queue='hello')body = "hello word11"
channel.basic_publish(exchange='',routing_key='hello', #队列名字body=body) #消息内容
print(" [x] Sent %s" % body)
connection.close() #队列关闭消费者:
#no_ack=True 信息处理完成或没处理完成,都不会给服务器端确认。当队列信息不关心的情况下,可以设置no_ack=True(简单说可以允许信息丢失)。一般默认情况下不加,让其他消费者客户端继承接收,信息接收完成,需要手动确认一下,保证消息被完整处理。
import pika
import timerabbitmq_passswd = pika.PlainCredentials('chen1203','chen1203..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.5.4',5672,'/',rabbitmq_passswd))channel = connection.channel() #声明一个管道#声明queue队列,
channel.queue_declare(queue='hello')#ch 管道的内存对象地址
def callback(ch, method, properties, body):time.sleep(10)print(" [x] Received %r" % body)#开始消费消息 声明语法
channel.basic_consume(callback, #调用函数,如果收到消息就调用函数来处理消息queue='hello',#no_ack=True)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收队列
信息输出:
/Library/Frameworks/Python.framework/Versions/3.5/bin/python3.5 /Users/mac/PycharmProjects/untitled2/51CTO/7days/rabbitmq_client.py[*] Waiting for messages. To exit press CTRL+C[x] Received b'hello word5'[x] Received b'hello word11'[x] Received b'hello word'[x] Received b'hello word2'[x] Received b'hello word5'[x] Received b'hello word10'[x] Received b'hello word1'[x] Received b'hello word6'[x] Received b'Hello World!'[x] Received b'Hello World1122!'[x] Received b'hello word'[x] Received b'hello word3'[x] Received b'hello word4'[x] Received b'hello word6'[x] Received b'hello word7'[x] Received b'hello word9'
结论:当把消费者C1 、C2 慢慢关掉之后,只保留C3 一个的时候。C3会把C1、C2的信息进行接管。可以理解为,只要RabbitMQ 服务器不挂,信息没有丢失。
知识延伸:消费者是把数据接收了,RabbitMQ 中为何还存在这么多的数据,为什么不是跟着消费者消费的信息,进而减少?
# rabbitmqctl list_queues
Listing queues ...
hello 16
在消费者def callback 函数中,加入:ch.basic_ack(delivery_tag = method.delivery_tag),语法如下:
def callback(ch, method, properties, body):print " [x] Received %r" % (body,)time.sleep( body.count('.') )print " [x] Done"ch.basic_ack(delivery_tag = method.delivery_tag) 举例
生产者:
import pikarabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel() #声明一个管道#声明queue队列
channel.queue_declare(queue='hello')body = "hello word11"
channel.basic_publish(exchange='',routing_key='hello', #队列名字body=body) #消息内容
print(" [x] Sent %s" % body)
connection.close() #队列关闭消费者:
import pika
import timerabbitmq_passswd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passswd))channel = connection.channel() #声明一个管道#声明queue队列,
channel.queue_declare(queue='hello')#ch 管道的内存对象地址
def callback(ch, method, properties, body):time.sleep(10)print(" [x] Received %r" % body)ch.basic_ack(delivery_tag= method.delivery_tag)#开始消费消息 声明语法
channel.basic_consume(callback, #调用函数,如果收到消息就调用函数来处理消息queue='hello',#no_ack=True 信息处理完成或没处理完成,都不会给服务器端确认。当队列信息不关心的情况下,可以设置no_ack=True(简单说可以允许信息丢失)。一般默认情况下不加,让其他消费者客户端继承接收)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收队列
结论:操作验证过程中,检查服务器中的队列数据,会随着消费者的接收进而减少,这样有利于去判断队列中的数据是否有堆积。
# rabbitmqctl list_queues
Listing queues ...
hello 0
B、消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
整体设置如下:
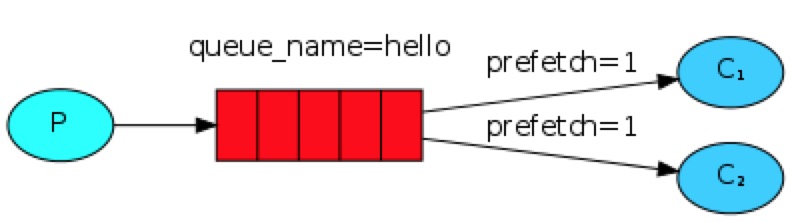
只需要在消费者端添加,如下参数:channel.basic_qos(prefetch_count=1)
举例:
生产者:
import pikarabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel() #声明一个管道#声明queue队列
channel.queue_declare(queue='hello1',durable=True)body = "hello word13"
channel.basic_publish(exchange='',routing_key='hello1', #队列名字body=body,properties=pika.BasicProperties(delivery_mode = 2))
print(" [x] Sent %s" % body)
connection.close() #队列关闭消费者1,加入time.sleep(30):
import pika
import timerabbitmq_passswd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passswd))channel = connection.channel() #声明一个管道#声明queue队列,
channel.queue_declare(queue='hello1',durable=True)channel.basic_qos(prefetch_count=1)#ch 管道的内存对象地址
def callback(ch, method, properties, body):time.sleep(30)print(" [x] Received %r" % body)ch.basic_ack(delivery_tag= method.delivery_tag)#开始消费消息 声明语法
channel.basic_consume(callback, #调用函数,如果收到消息就调用函数来处理消息queue='hello1',#no_ack=True 信息处理完成或没处理完成,都不会给服务器端确认。当队列信息不关心的情况下,可以设置no_ack=True(简单说可以允许信息丢失)。一般默认情况下不加,让其他消费者客户端继承接收)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收队列消费者2,不加时间等待:
import pikarabbitmq_passswd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passswd))channel = connection.channel() #声明一个管道#声明queue队列,
channel.queue_declare(queue='hello1',durable=True)channel.basic_qos(prefetch_count=1)#ch 管道的内存对象地址
def callback(ch, method, properties, body):print(" [x] Received %r" % body)ch.basic_ack(delivery_tag= method.delivery_tag)#开始消费消息 声明语法
channel.basic_consume(callback, #调用函数,如果收到消息就调用函数来处理消息queue='hello1',#no_ack=True 信息处理完成或没处理完成,都不会给服务器端确认。当队列信息不关心的情况下,可以设置no_ack=True(简单说可以允许信息丢失)。一般默认情况下不加,让其他消费者客户端继承接收)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收队列
结论:C1 处理的比较慢,队列中的数据会由C2处理。直接到C1处理完第一个数据后,在重新处理其他的数据。。而不是平均轮询的模式。
3、RabbitMQ 队列消息持久化
场景:无论是RabbitMQ服务挂掉,还是消费者被断掉。当再次启动的时候,却保队列信息还在,不会丢失,可以正常接收。
队列持久化:在声明队列的时候,后面添加参数:durable=True,说明队列被持久化。在生产者,消费者中,都需要添加该参数。语法如下:
channel.queue_declare(queue='hello', durable=True)队列中数据持久化:把队列中的数据,进行持久化。在生产者中加入properties=pika.BasicProperties(delivery_mode = 2)。语法如下:
channel.basic_publish(exchange='',routing_key="task_queue",body=message,properties=pika.BasicProperties(delivery_mode = 2, # make message persistent))
举例:
生产者:
import pikarabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel() #声明一个管道#声明queue队列
channel.queue_declare(queue='hello1',durable=True)body = "hello word11"
channel.basic_publish(exchange='',routing_key='hello1', #队列名字body=body,properties=pika.BasicProperties(delivery_mode = 2))
print(" [x] Sent %s" % body)
connection.close() #队列关闭消费者:
import pika
import timerabbitmq_passswd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passswd))channel = connection.channel() #声明一个管道#声明queue队列,
channel.queue_declare(queue='hello1',durable=True)#ch 管道的内存对象地址
def callback(ch, method, properties, body):time.sleep(2)print(" [x] Received %r" % body)ch.basic_ack(delivery_tag= method.delivery_tag)#开始消费消息 声明语法
channel.basic_consume(callback, #调用函数,如果收到消息就调用函数来处理消息queue='hello1',#no_ack=True 信息处理完成或没处理完成,都不会给服务器端确认。当队列信息不关心的情况下,可以设置no_ack=True(简单说可以允许信息丢失)。一般默认情况下不加,让其他消费者客户端继承接收)print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收队列
结论:操作模拟RabbitMQ 服务挂掉:
- 1、没有持久化的程序,队列库、数据,在RabbiMQ服务中都会丢失。
- 2、有持久化的程序,当RabbitMQ 再次启动的时候,队列库还在,数据还在。启动消费者可以正常接收。
4、RabbitMQ 广播模式
上面的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了。Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息。
exchange简单来讲,就是中间件转发器。主要类型有:
- fanout:所有bind到此exchange的queue都可以接收消息
- direct:通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息。注意:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
- headers:通过headers 来决定把消息发给哪些queue
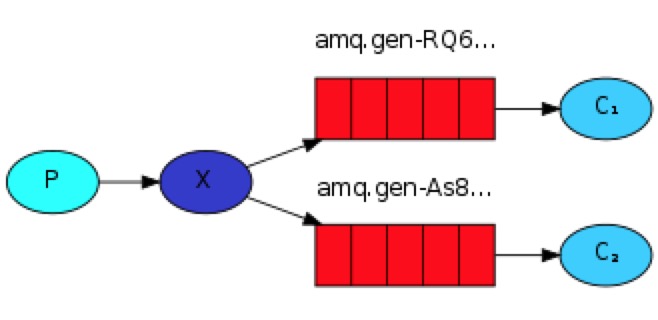
A、fanout 广播订阅模式(类似收音机接收频道信息,客户端关闭,信息就不存在了)--all 模式
需要queue和exchange绑定,因为消费者不是和exchange直连的,消费者是连在queue上,queue绑定在exchange上,消费者只会在queu里度消息。
整体设置如下,发送一个信息,让每个客户端都能收到同样的信息:
举例:
生产者:
import pika
import sysrabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.exchange_declare(exchange='logs',exchange_type='fanout')message = ' '.join(sys.argv[1:]) or "info: Hello World---1111!"channel.basic_publish(exchange='logs',routing_key='',body=message)
print(" [x] Sent %r" % message)
connection.close()消费者:
import pikarabbitmq_passwd = pika.PlainCredentials('chen1203','chen1203..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.5.4',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.exchange_declare(exchange='logs',exchange_type='fanout')result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queuechannel.queue_bind(exchange='logs',queue=queue_name)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r" % body)channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming()
结论:生产者发送一个信息,启动的两个消费者,同时能把信息收到。
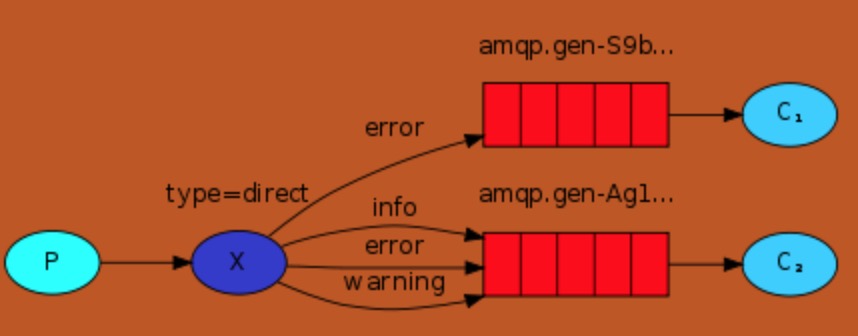
B、direct 广播订阅模式(有选择的接收消息exchangr_type = direct) -- 接收者可以过滤消息,只收我想要的消息
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
整体设计如下:
举例:
生产者:
import pika
import sysrabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.exchange_declare(exchange='direct_logs',exchange_type='direct') # 定义类型severity = sys.argv[1] if len(sys.argv) > 1 else 'info' #如果没有值输入,默认就是info级别的日志
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',routing_key=severity,body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()消费者:
import pika
import sysrabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.exchange_declare(exchange='direct_logs',exchange_type='direct')result = channel.queue_declare(exclusive=True)
queue_name = result.method.queueseverities = sys.argv[1:]
if not severities:sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])sys.exit(1)for severity in severities:channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming()
执行操作,启动三个终端:
C1的启动模式为表示只接收 error 日志,启动客户端: $ python3 RabbitMQ_direct_cli.py error
C2的启动模式为表示只接收 info 日志,启动客户端: $ python3 RabbitMQ_direct_cli.py info
P启动,表示定义日志格式为info 级别:$ python3 RabbitMQ_direct_p.py info
结论:C1 收不到对应信息,C2正常接收。
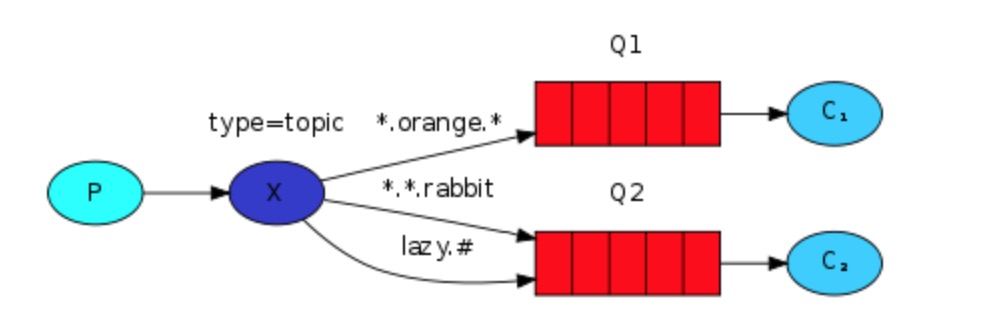
C、topic 广播订阅模式(更细致的消息过滤(exchange_type=topic))
未来在业务中应用,可以用来区分,系统日志、php\nginx功能日志,做到更细分化的日志订阅。比如把error中,apache和mysql的分别或取出来。
整体设计如下:
举例:
生产者:
import pika
import sysrabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.exchange_declare(exchange='topic_logs',exchange_type='topic')severity = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',routing_key=severity,body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()消费者:
import pika
import sysrabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.exchange_declare(exchange='topic_logs',exchange_type='topic')result = channel.queue_declare(exclusive=True)
queue_name = result.method.queueseverities = sys.argv[1:]
if not severities:sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])sys.exit(1)for severity in severities:channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key=severity)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming() 运行接收端,指定接收哪些消息,如下:
发送端:
$ python3 RabbitMQ_topic_p.py "#"
$ python3 RabbitMQ_topic_p.py "kern.*"
$ python3 RabbitMQ_topic_p.py "mysql.*"
$ python3 RabbitMQ_topic_p.py "*.info"
$ python3 RabbitMQ_topic_p.py "*.info" "mysql*"接收端:
C1
$ python3 RabbitMQ_topic_cli.py *.info[*] Waiting for logs. To exit press CTRL+C[x] '*.info':b'Hello World!'[x] '*.info':b'mysql*'C2
$ python3 RabbitMQ_topic_cli.py *.error mysql.*[*] Waiting for logs. To exit press CTRL+C[x] 'mysql.*':b'Hello World!C3
$ python3 RabbitMQ_topic_cli.py # ----注释:#表示全部接收
Usage: RabbitMQ_topic_cli.py [info] [warning] [error]
CQ-Chen:shell CQ_Chen$ python3 RabbitMQ_topic_cli.py '#' [*] Waiting for logs. To exit press CTRL+C[x] '#':b'Hello World!'[x] 'kern.*':b'Hello World!'[x] 'mysql.*':b'Hello World!'[x] '*.info':b'Hello World!'[x] '*.info':b'mysql*'
5、RabbitMQ RPC
理解:什么是RPC?
(RPC) Remote Procedure Call Protocol 远程过程调用协议
在公司中,系统由大大小小的服务构成,不同的团队维护不同的代码,部署在不同的机器。但是在做开发时候往往要用到其它团队的方法,因为已经有了实现。但是这些服务部署不同的机器上,想要调用就需要网络通信,这些代码繁琐且复杂,一不小心就会写的很低效。RPC协议定义了规划,其它的公司都给出了不同的实现。例如:WebApi。
在RabbitMQ中RPC的实现也是很简单高效的,现在我们的客户端、服务端都是消息发布者与消息接收者。
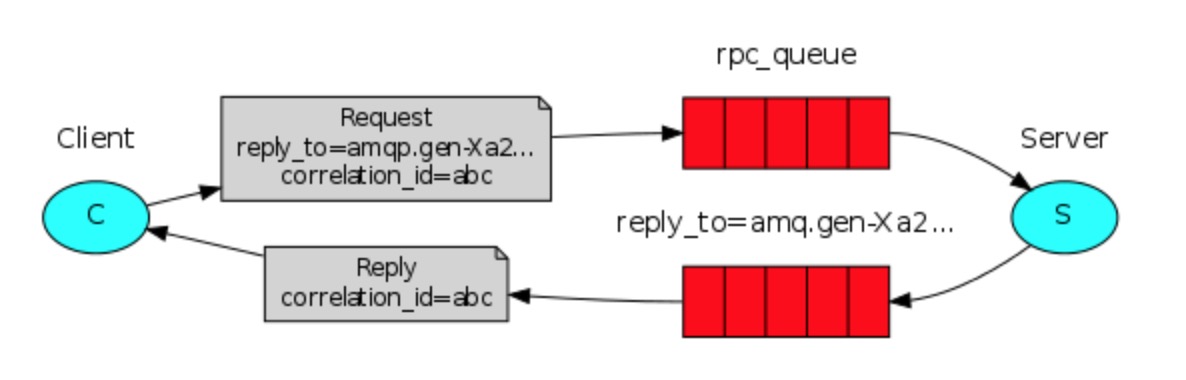
流程原理:
- 客户端通过RPC向服务端发出请求:
过程会传输两个值,correlation_id:请求标识,erply_to:处理完过后把结果返回到指定的这个队列中。- 服务端拿到了请求,开始处理并返回:
correlation_id:这是请求标识 ,原封不动的给你。 这时候客户端用自己的correlation_id与服务端返回的id进行对比。是我的,就接收。反之丢弃。整体设计如下:
举例:(参考官网的例子:http://www.rabbitmq.com/tutorials/tutorial-six-python.html)
客户端:
import pika
import uuidclass FibonacciRpcClient(object):def __init__(self):#指定链接的RabbitMQself.rabbitmq_passwd = pika.PlainCredentials('chen12033', 'chen12033..')self.connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41', 5672, '/', self.rabbitmq_passwd))self.channel = self.connection.channel()result = self.channel.queue_declare(exclusive=True)self.callback_queue = result.method.queueself.channel.basic_consume(self.on_response, no_ack=True,queue=self.callback_queue)def on_response(self, ch, method, props, body):if self.corr_id == props.correlation_id: #对比server端返回的uuid值,如果是一样,就赋值给response等于bodyself.response = bodydef call(self, n):self.response = Noneself.corr_id = str(uuid.uuid4())self.channel.basic_publish(exchange='',routing_key='rpc_queue', #制定队列通道properties=pika.BasicProperties(reply_to=self.callback_queue, #指定返回去reply_to 通道correlation_id=self.corr_id,),body=str(n))while self.response is None: #判断self.response 没有数据,就一直执行,直到函数 def on_response 中的# self.corr_id == props.correlation_id 把body赋值给予self.response,才会执行下一步。self.connection.process_data_events()return int(self.response)fibonacci_rpc = FibonacciRpcClient()print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(24) #可更改call的值
print(" [.] Got %r" % response)服务端:
import pika
import timerabbitmq_passwd = pika.PlainCredentials('chen12033','chen12033..')
connection = pika.BlockingConnection(pika.ConnectionParameters('203.66.8.41',5672,'/',rabbitmq_passwd))channel = connection.channel()channel.queue_declare(queue='rpc_queue')#函数计算数列:1 1 2 3 5 8 13 21 34 前面两个数的和等于第三个数的值。
def fib(n):if n == 0:return 0elif n == 1:return 1else:return fib(n - 1) + fib(n - 2)def on_request(ch, method, props, body):n = int(body)print(" [.] fib(%s)" % n)response = fib(n)ch.basic_publish(exchange='',routing_key=props.reply_to,properties=pika.BasicProperties(correlation_id= \props.correlation_id),body=str(response))ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue') #指定queue 跟客户端一至print(" [x] Awaiting RPC requests")
channel.start_consuming()输出:
客户端:[x] Requesting fib(30)[.] Got 832040服务端:[x] Awaiting RPC requests[.] fib(30)
结论:当客户端发起请求时,fibonacci_rpc.call(30) 指定一个值。服务端计算完成,把结果通过另外的对列渠道返回给客户端,数据双向传输。








